
Edge AI Deployment 2026: Your Complete Roadmap
The number that should reframe this conversation is US$82.0 billion. That's the edge computing market forecast for 2026, according to STL Partners' edge computing statistics. Most leaders still treat edge AI like a specialist architecture choice. In practice, 2026 is the year it becomes an operating model decision.
That changes how you should think about deployment. The hard question isn't “What is edge AI?” It's “Where does local inference create enough operational or financial advantage to justify the complexity?” If you're a founder, that means budgeting beyond the demo. If you run operations, it means defining success in uptime, quality yield, bandwidth consumption, and incident response, not just model accuracy.
Teams that get edge AI deployment in 2026 right won't win because they bought the newest chip or adopted the latest framework. They'll win because they picked narrow use cases, matched architecture to the environment, and tracked KPIs that matter to finance and frontline operators.
Why 2026 Is the Tipping Point for Edge AI
US$82.0 billion is large enough to change buying behavior, not just headline decks. As noted earlier, that is the 2026 forecast for the edge computing market, and it helps explain why edge AI is shifting from pilot territory into mainstream operating plans.
The reason is practical. By 2026, edge deployment is no longer a science project reserved for advanced engineering teams. Hardware options are broader, deployment tooling is better, and finance leaders can now evaluate local inference against familiar line items such as cloud spend, network usage, labor efficiency, scrap rates, and downtime.
That combination matters more than the technology itself.
Earlier edge programs often started with a technical proof point. A model ran on a camera. A gateway processed sensor data offline. A vehicle handled inference without constant connectivity. Those were useful milestones, but they rarely answered the question a CFO or operations lead will ask first: what cost does this remove, and how will we measure the return?
2026 is the tipping point because that question now has clearer answers.
Three shifts are driving it:
- The infrastructure is more standardized: Teams can deploy across multiple sites without rebuilding the stack each time.
- The cost case is easier to model: Local inference can reduce recurring cloud processing, data transfer, and operational delays in ways that show up in budgets.
- The buying trigger is operational pain: Edge AI gets funded when it improves throughput, uptime, safety response, or service quality in environments where waiting on the cloud adds cost.
A hybrid architecture often works like a retail supply chain. Central systems handle planning, coordination, and long-range optimization. Local sites handle the immediate decisions that keep shelves stocked and customers moving. Edge AI follows the same pattern. Keep model training, fleet oversight, and historical analysis centralized. Put time-sensitive inference close to the machine, camera, worker, or asset.
For business leaders, the implication is straightforward. The decision is no longer whether edge AI is interesting. The decision is where local inference changes the unit economics of an operation enough to justify device management, field support, and deployment complexity.
That will not apply to every workflow. It should not. If the process can tolerate delay, depends on heavy centralized compute, or lacks enough scale to offset rollout costs, cloud inference may remain the better choice. But if a decision has to happen on a factory line, in a store, inside a vehicle, or at a remote site, edge AI starts to look less like an innovation bet and more like basic operational design.
Leaders reviewing broader AI operating models are already seeing this pattern in how companies are using AI transformation in 2026. The winners will be the teams that treat edge deployment as a budgeting and performance question first, then choose the architecture that fits.
Deconstructing Edge AI Beyond the Buzzwords
Edge AI is simple in principle. Instead of sending all data to a distant cloud system for analysis, you run part of the intelligence near the data source. That might be on a camera, inside a sensor, on a gateway, or on an on-site server.
Think about a smartphone sorting photos locally versus uploading everything before it can tell you what's in the image. The first approach feels instant and private. The second adds delay, network dependency, and data movement. Edge AI applies that same logic to industrial systems, stores, vehicles, kiosks, and connected equipment.
The plain-English definition
Edge AI means AI inference happens close to where data is generated.
The key word is inference, not training. Most organizations still train heavier models in the cloud or a data center. At the edge, the goal is usually to execute decisions quickly and repeatedly in production.
That distinction helps business leaders avoid a common mistake. They assume “AI at the edge” means recreating a full cloud AI stack in every location. It doesn't. Usually, you keep centralized systems for model development, fleet management, and analytics, then place the right decision logic on devices or local infrastructure.
If your use case is visual inspection, worker safety, shelf monitoring, or machine anomaly detection, the important question isn't whether the model is elegant. It's whether the system can act when conditions change on the ground. That's why many real deployments start with computer vision solutions for inspections and monitoring.
The three business drivers
Most edge AI buying decisions come down to three forces.
- Speed: Some decisions lose value if they arrive late. A defect that passes the line, a safety event that isn't flagged in time, or a machine fault that escalates before intervention all have direct operating cost.
- Privacy and control: In some environments, sending raw video, audio, or operational data upstream creates governance problems or expands risk.
- Autonomy: Connectivity is often less reliable than architecture diagrams suggest. Stores, warehouses, remote sites, vehicles, and field operations can't always assume stable backhaul.
Here's the simplest filter to use:
| Driver | What it solves | Typical edge fit |
|---|---|---|
| Speed | Real-time decisions | Inspection, alerting, safety response |
| Privacy | Local handling of sensitive data | On-device vision, localized processing |
| Autonomy | Operation during weak or intermittent connectivity | Remote assets, mobile systems, field sites |
What edge AI is not
It's not a universal replacement for cloud AI. It's not automatically cheaper. And it's not just “run the same model on a smaller box.”
Practical rule: Put intelligence at the edge only when local action creates measurable value that a centralized workflow can't deliver cleanly.
That's why edge AI deployment in 2026 should be framed as workflow design, not infrastructure fashion. The winning design is the one that puts each part of the job in the right place.
The 2026 Edge AI Hardware and Software Stack
Most failed edge programs don't fail because the model is bad. They fail because the stack is mismatched. A team picks a powerful model that won't fit thermal limits, or a cheap device that can't sustain inference, or a management layer that turns every update into a field-service event.
A workable stack has two parts. The hardware foundation determines what can run. The software ecosystem determines whether you can operate it at scale.
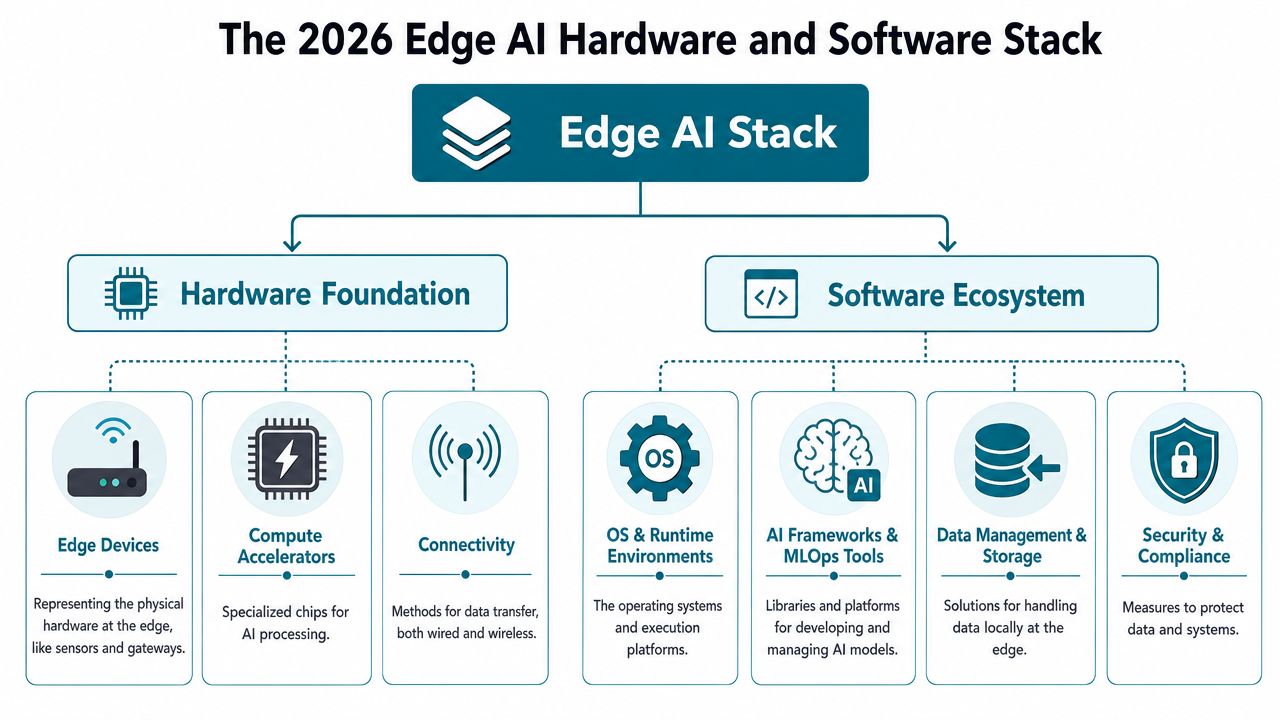
Hardware first, because physics wins
By 2026, edge AI deployment relies heavily on specialized AI chips that can deliver 26 TOPS at 2.5 W, or about 10 TOPS/W, and these chips are at least 6× more efficient than CPUs and mainstream GPUs for neural-network tasks, according to N-iX's review of edge AI hardware trends.
That efficiency gap is why architecture decisions are changing. General-purpose compute still has a place, especially for coordination, non-AI logic, and some local processing. But always-on inference on cameras, sensors, and embedded controllers becomes much more practical when a dedicated accelerator handles the neural workload.
Three hardware choices matter most:
- Endpoint devices: Cameras, sensors, kiosks, robots, handhelds, and embedded controllers. These define environmental constraints such as heat, power draw, enclosure size, and physical tampering risk.
- Accelerators: NPUs and other AI-specific chips determine whether local inference is viable.
- Connectivity layer: Ethernet, Wi-Fi, cellular, and industrial networking affect where you place intelligence and how often systems sync upstream.
If you're evaluating consumer-grade connected products or distributed device fleets, the hardware conversation often overlaps with Consumer IoT solution design and deployment choices.
Software is where scale becomes real
Hardware gets most of the attention. Software decides whether the deployment survives contact with operations.
The most practical stack usually includes:
- Runtime and OS layer: The execution environment on-device or on the gateway.
- Model packaging: A consistent format for moving models between training and deployment environments.
- Orchestration and fleet management: The control plane for rollout, rollback, monitoring, and versioning.
- Security controls: Identity, secure boot, signed updates, and access policies.
- Local data services: Buffering, event retention, and lightweight storage for disconnected operation.
A good analogy is a trucking fleet. The vehicles matter, but the dispatch system decides whether freight arrives on time. In edge AI, accelerators are the vehicles. Orchestration is dispatch.
What works and what breaks
The stack works when teams design backward from operating conditions. Start with power, heat, latency tolerance, and maintenance reality. Then choose the model and device.
What usually breaks:
| Common mistake | Why it fails |
|---|---|
| Selecting the largest model that fits in a lab demo | Field conditions reduce headroom fast |
| Ignoring update mechanics | Every model refresh becomes manual work |
| Treating observability as optional | You can't improve systems you can't see |
| Over-centralizing logs and raw data | Network costs and delay rise quickly |
A strong edge stack is boring in the right places. Predictable deployment beats impressive specs.
Choosing Your Edge Deployment Architecture
Architecture is where strategy becomes budget. The wrong pattern can make a promising use case expensive to maintain. The right one can keep costs controlled while preserving the operational benefit that justified edge in the first place.
Most edge AI deployments fall into three patterns. They're not ideological camps. They're trade-off choices.
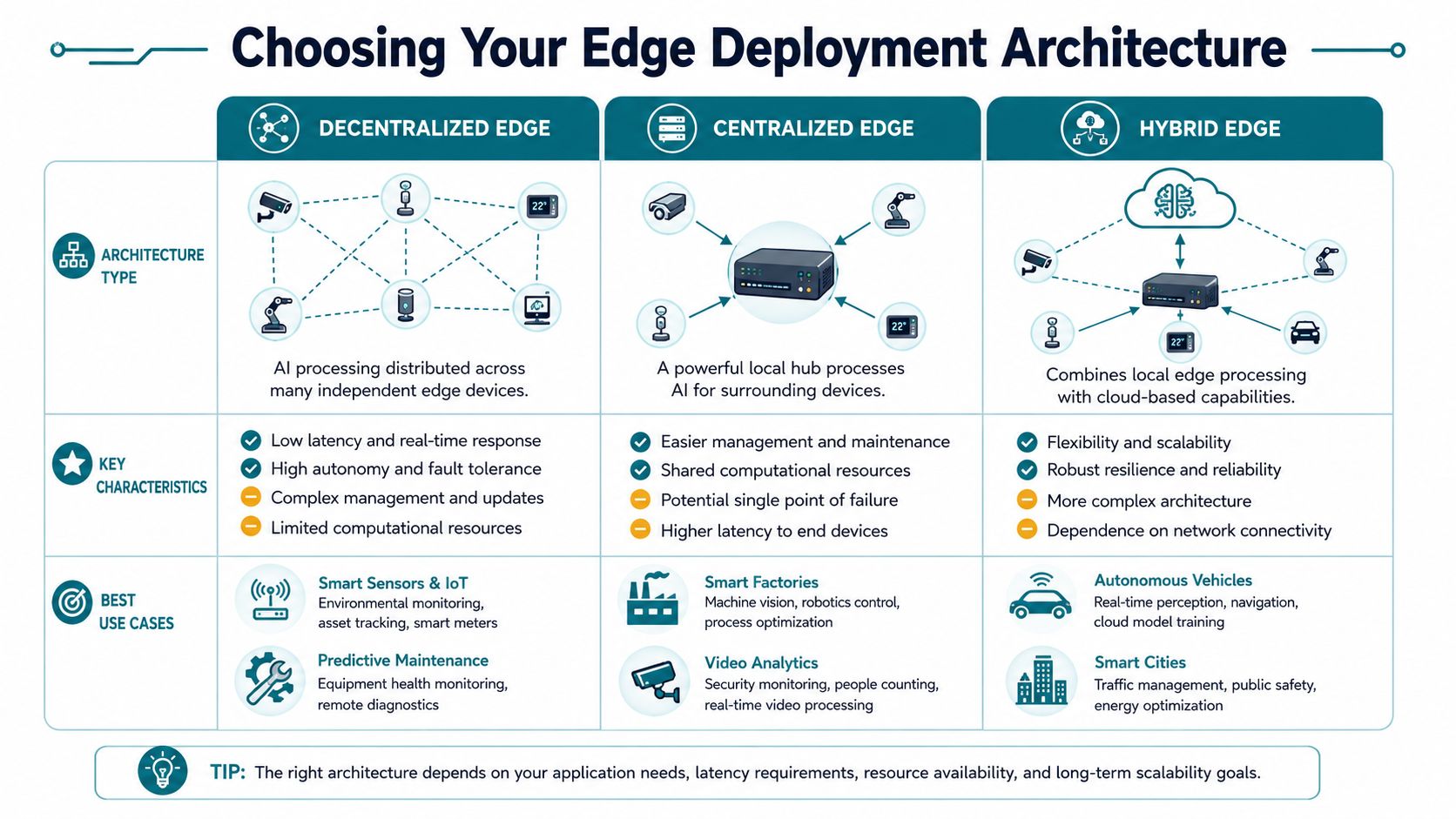
Device-native deployments
This is the purest form of edge. Inference runs on the end device itself, such as a smart camera, handheld scanner, wearable, or embedded controller.
The upside is straightforward. You get low latency, local autonomy, and less need to move raw data around. The downside is equally clear. Every device becomes part of your deployment surface.
Device-native fits best when:
- Each endpoint must act independently
- Connectivity is inconsistent
- The model is narrow and stable
This pattern struggles when models are heavy, sites need shared compute, or update discipline is weak.
Gateway-centric deployments
Here, devices send data to a more capable on-site hub, edge server, or industrial gateway. That local hub runs inference and coordinates actions.
This setup often makes sense in factories, stores, clinics, or logistics sites where several devices feed a common workflow. It centralizes management within the site without pushing every decision to the cloud.
A gateway-centric pattern is often the practical middle ground when:
- You need more compute than endpoints can carry
- Several cameras or sensors support one process
- You want simpler local management than fully decentralized fleets
The trade-off is resilience. If the gateway is the brain for the whole site, you need a plan for failover and degraded operation.
Hybrid architectures
Hybrid has become the dominant serious answer because it reflects how operations work. Local systems handle immediate decisions. The cloud handles training, orchestration, heavier analytics, and fleet-level oversight.
A key 2026 pattern is the use of hybrid edge architecture with Small Language Models and model compression techniques such as quantization and pruning. This approach enables local inference and agentic workflows and can cut unplanned industrial downtime by up to 40% through real-time anomaly detection, according to this 2026 discussion of hybrid edge AI architectures.
That architecture works because it mirrors supply chains. You don't keep every item in a central warehouse, and you don't manufacture everything in every store. You position resources where they create the best response time and the lowest total friction.
A useful comparison looks like this:
| Pattern | Best for | Main risk |
|---|---|---|
| Device-native | Independent endpoints, offline operation | Fleet complexity |
| Gateway-centric | Shared-site workflows, local coordination | Local single point of failure |
| Hybrid | Mixed latency needs, scale, centralized governance | Design complexity |
For leaders trying to decide how much should stay centralized, the broader cloud-versus-edge discussion in this analysis of testing the cloud model is often the right framing.
Choose the architecture that matches the business process, not the one your engineering team finds most elegant.
Building the Business Case with Costs and KPIs
Most edge AI proposals often get weak because they describe latency gains, local inference, and privacy benefits, then stop short of a real financial model. A CFO won't fund architecture. They'll fund a measurable operating improvement.
The business question is simple: when does edge beat centralized AI economically? By 2026, the clearest answer is that edge is strongest where decision latency, bandwidth costs, or connectivity constraints dominate, especially in industrial computer vision and remote operations, as noted by the Edge AI Foundation's guidance on business-fit edge deployments.
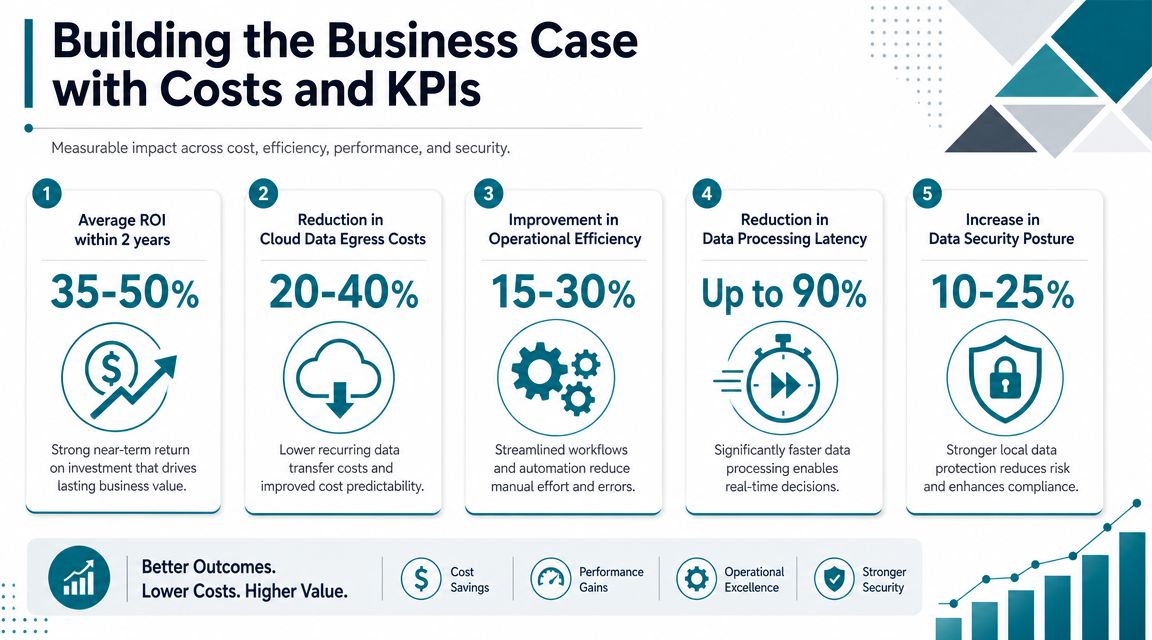
One note before going further: the infographic above includes example ranges, but you shouldn't use generic benchmark percentages to approve a project. Build the case from your own workflow economics.
What belongs in the cost model
An edge AI budget is broader than device cost. The right model includes both deployment and operating burden.
Use these cost buckets:
- Hardware spend: Cameras, gateways, embedded devices, accelerators, ruggedization, and local networking.
- Software and platform spend: Runtime, orchestration, monitoring, MLOps, and security tooling.
- Integration work: Connecting the AI output to MES, ERP, WMS, POS, ticketing, or field-service workflows.
- Operations and maintenance: Device replacement, support, updates, model refreshes, and observability.
- Change management: Training operators, supervisors, and maintenance teams to trust and use system outputs.
A model that excludes the last two usually looks attractive in procurement and painful six months later.
The KPIs that actually matter
Don't lead with inference speed unless speed directly maps to money, risk, or throughput. Start with workflow KPIs.
Better KPI categories include:
Operational continuity
- Equipment uptime
- Mean time to detect a fault
- Mean time to respond on site
Quality and process control
- Defect escape rate
- Rework volume
- False reject burden on operators
Cost containment
- Cloud data transfer exposure
- Manual review hours
- Truck rolls or field-service interventions
Commercial impact
- Faster service throughput
- More usable data from remote sites
- New premium features enabled by local intelligence
A strong dashboard often pairs one technical KPI with one business KPI. Example: model precision plus defect escapes. Or alert latency plus machine downtime.
How to decide if the economics are real
Use a short decision screen before funding the pilot.
| Question | Why it matters |
|---|---|
| Does delayed action have a measurable cost? | Edge matters most when time changes the outcome |
| Is raw data expensive or impractical to move constantly? | Local processing can lower recurring overhead |
| Can the edge output trigger an action, not just a report? | Action creates ROI faster than passive analytics |
| Will the deployment replace manual effort or prevent losses? | That's where budget approval gets easier |
If you need a baseline for tracking progress against AI KPIs across operations, this guide to AI transformation progress monitoring is a useful companion framework.
Your Phased Edge AI Deployment Roadmap
Leaders often overcomplicate edge AI deployment in 2026 by trying to design the full future-state architecture before proving one narrow workflow. That's backward. Edge should scale through controlled phases, each with a different question.
The first question is whether the use case has enough value. The second is whether the system can survive in the field. The third is whether you can operate it repeatedly without heroics.
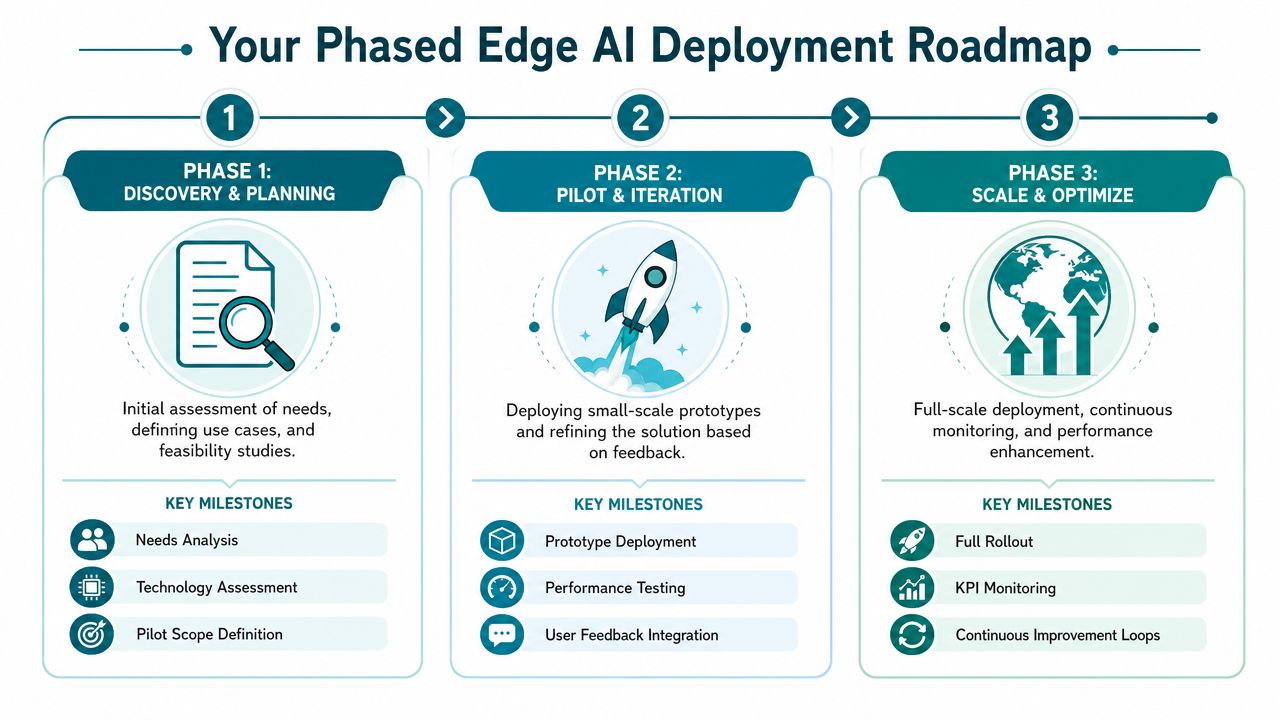
Phase 1 Audit and strategy
Start with one workflow, not one technology.
Pick a use case where local inference changes an operational outcome. Good candidates are visual inspection, anomaly detection, occupancy or queue monitoring, remote asset surveillance, and machine-state interpretation. Weak candidates are “interesting data opportunities” that don't trigger a decision or reduce work.
During the audit, pressure-test five things:
- Business value: What cost, delay, or risk does the current process create?
- Data reality: Do you have usable edge data, and is it labeled or labelable?
- Actionability: What happens when the model flags an event?
- Environment fit: Power, heat, connectivity, maintenance access, and physical security.
- System ownership: Which team will own the workflow after go-live?
A solid output for this phase is a one-page deployment charter. It should name the process owner, target KPIs, site constraints, escalation path, and success threshold for a pilot.
Phase 2 Pilot and validation
Pilots should be small enough to learn from and serious enough to expose operational friction. That usually means a single site, one line, one asset class, or one location type.
Don't optimize for presentation quality. Optimize for truth. A pilot should reveal whether the model performs in real light, noise, motion, and failure conditions, and whether frontline staff respond correctly to the output.
Pilot checklist:
- Instrument the workflow: Capture predictions, exceptions, overrides, and actions taken.
- Track baseline versus AI-assisted performance: Compare against the current process, not a theoretical benchmark.
- Document edge-specific failures: Power interruptions, connectivity gaps, device reboots, thermal slowdowns, update issues.
- Review with operators weekly: They'll spot false positives and process workarounds before dashboards do.
The pilot succeeds when operators change behavior and the business metric moves. A technically elegant demo that no one uses isn't a deployment.
Phase 3 Scale the operating model
Scaling is where many teams discover they didn't build a deployment model. They built a pilot artifact.
At this stage, standardize what can be repeated:
- Device images
- Provisioning steps
- Model packaging
- Rollback procedures
- Alert routing
- On-site support playbooks
This is also the point where orchestration matters more than model novelty. Some organizations use internal MLOps platforms. Others use vendor tooling. AmasaTech, for example, offers AI workflow enterprise model deployment services that fit this stage by focusing on production rollout, monitoring, and KPI-linked operation rather than just model development.
Phase 4 Optimize and govern
Once the system is live across multiple sites, the main job changes. You're no longer proving the concept. You're preserving reliability.
That means:
- Watching model performance in production: Not just accuracy, but action quality and exception rates.
- Managing drift and updates: Conditions change by site, season, layout, operator behavior, and hardware age.
- Closing the loop with operations: AI outputs should inform maintenance plans, staffing, quality reviews, and process redesign.
A mature deployment treats edge AI like a living operational system. The best sign you've reached that stage is simple. Site teams stop talking about “the AI project” and start treating it like part of normal operations.
Navigating Deployment Risks and Compliance
Edge AI risk rarely shows up on launch day. It shows up in quarter two, when 200 devices are running different software versions, two sites have weak connectivity, and operations teams start creating workarounds to keep throughput up.
That is why governance belongs in the budget, not in a later wishlist. Founders often model the cost of devices, integration, and model development, then underfund patching, monitoring, audit logging, and field support. In practice, those operating controls determine whether the deployment reduces cost or becomes a recurring service problem.
Security starts with the device, not the dashboard
Edge systems live in factories, stores, vehicles, clinics, and warehouses. People can unplug them, move them, swap components, or connect unauthorized peripherals. A well-configured cloud console does not fix a physically exposed endpoint.
Set the baseline early:
- Assign a verifiable identity to each device. No shared credentials. No unmanaged access paths.
- Authenticate every software package. Firmware, containers, and model files should be signed and verified before they run.
- Limit the blast radius. Segment devices by site or function so one compromised node does not expose the full fleet.
- Plan for offline periods. Security controls cannot depend on constant connectivity.
These controls add cost up front. They reduce a far larger cost later: emergency field remediation, production downtime, and loss of trust from site operators.
Compliance gets more operational at the edge
Local inference can reduce exposure by keeping raw data on the device. It does not remove compliance work. It changes the questions.
Teams need clear answers before rollout:
- What data is processed locally
- What leaves the device, and in what form
- How long any local data or logs are retained
- Who can review outputs, export records, or override decisions
- How policy changes are pushed across the fleet
The hardest compliance failures are usually not dramatic breaches. They are inconsistent handling across sites. One location stores images for 30 days. Another keeps them indefinitely. One supervisor can export event logs. Another cannot. That inconsistency creates legal exposure and makes audits slow and expensive.
For regulated environments, treat policy enforcement like model deployment. Version it, test it, and confirm it reaches every endpoint.
Reliability is a financial control
An unreliable edge system is not just a technical issue. It distorts the business case. If alerts are noisy, staff ignore them. If updates break devices, truck rolls go up. If model performance varies by hardware class, KPI reporting becomes hard to trust.
A simple operating view helps:
| Risk area | Mitigation move |
|---|---|
| Model drift | Review live performance by site, compare exception rates, and set retraining triggers |
| Hardware variance | Approve specific device classes and pin runtime versions |
| Intermittent connectivity | Buffer locally, sync later, and define degraded operating modes |
| Failed updates | Use staged releases, health checks, and rollback paths |
| Audit gaps | Keep immutable logs for model version, policy version, and operator actions |
| Alert fatigue | Tune thresholds with frontline teams and track action rate, not just alert volume |
Hybrid edge architecture works like a regional supply chain. The device handles immediate decisions close to the action. Central systems handle oversight, reporting, and policy control. If either side is poorly designed, costs rise fast. Too much dependence on the cloud increases fragility. Too little central control creates an unmanageable fleet.
AmasaTech helps organizations turn AI strategy into measurable operating outcomes. For edge AI deployment in 2026, the useful starting point is a scoped audit of where local inference can improve uptime, quality, cost, or service performance, followed by a phased production plan.