
AgentOps Services: A Guide to AI Automation & ROI
You launched a few AI agents because the demos looked obvious. One triages support tickets. Another drafts outbound emails. A third pulls data from internal systems and prepares summaries for account managers. For a few weeks, the story sounds good. Tasks move faster, teams get excited, and leadership starts asking where else agents can help.
Then the operational friction shows up.
One agent takes five steps to finish a task that should take one. Another calls the wrong tool because permissions were set too broadly. A customer-facing workflow produces inconsistent output, and nobody can explain why the result looked fine yesterday but failed today. Finance sees unpredictable API spend. Security asks who approved an agent to access production records. Legal asks whether you can reconstruct a decision if an agent sends a message or updates a system on your behalf.
That's the point where most companies realize deploying agents and running them are two different disciplines.
Your AI Agents Are Powerful But Are They Under Control
A founder or ops leader usually reaches AgentOps after the first real success. The agents are working well enough to matter, but not reliably enough to trust at scale. The issue isn't that the model is bad. The issue is that the business now has a new kind of digital worker, and nobody has put in place the operating controls to manage it.

That problem is becoming more common because the market is moving fast. Futurum Research data cited by ZBrain says only 12–18% of organizations have already formalized AgentOps practices, while another 45% of large companies plan to pilot AgentOps workflows within the next 18 months. The same source says the global AI agents market was valued at $5.26 billion in 2024 and is growing at a 46.3% CAGR (ZBrain on AgentOps adoption and market momentum). Early adoption is still limited, but the direction is clear.
What breaks first in real operations
The first failure mode is usually inconsistency. The second is lack of visibility. The third is trust.
- Inconsistency across tasks: The same agent handles similar requests differently because prompts, tools, or context windows aren't controlled tightly enough.
- No business-level observability: Teams can see that an API call happened, but they can't tie cost, latency, and task success back to a workflow owner.
- Weak operational boundaries: Agents get access to systems before companies define what they may do without review.
This is why AgentOps services matter. They aren't just another AI tool category. They are the management layer for an autonomous workforce.
For business leaders exploring agentic AI workflows in operations, the practical question isn't whether agents can perform useful work. It's whether that work can be made repeatable, measurable, and governable.
Strong agent performance in a demo proves capability. Strong AgentOps proves the business can live with that capability in production.
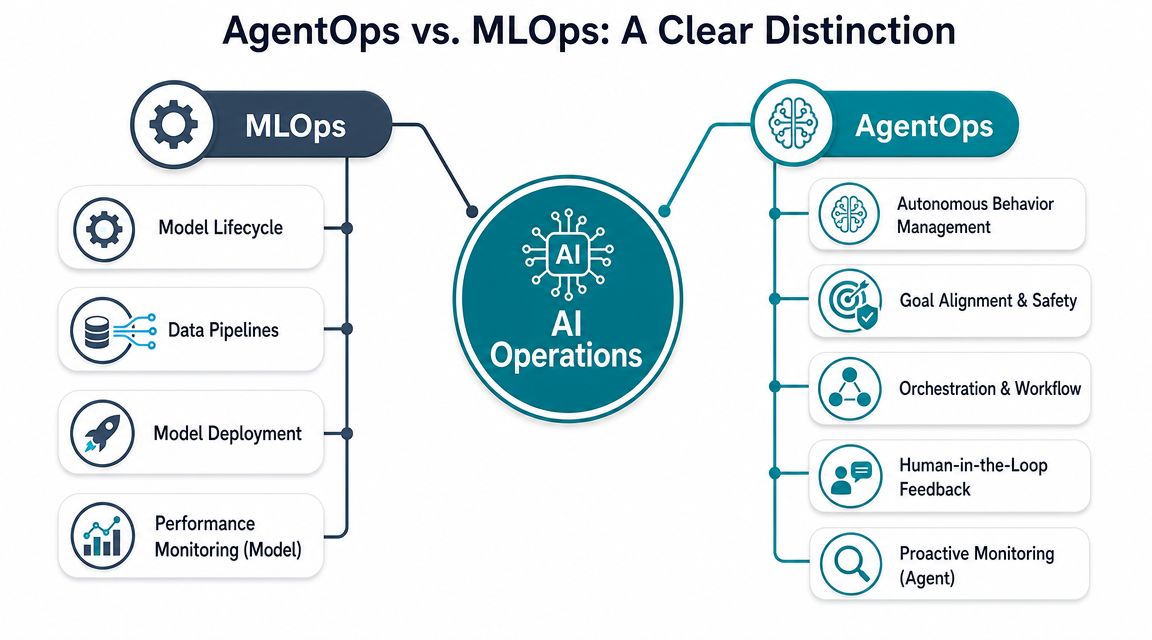
Defining AgentOps Beyond MLOps
Most leaders already understand MLOps at a high level. You train a model, deploy it, monitor quality, and manage drift. That frame helps, but it isn't enough for agentic systems.
IBM describes AgentOps as an emerging set of practices for managing the full lifecycle of autonomous AI agents, building on DevOps and MLOps while extending observability into development, testing, monitoring, feedback, and governance phases. IBM also notes that this matters because regulation, including the EU AI Act, is pushing teams to add guardrails, traceability, and compliance controls to agentic systems (IBM on what AgentOps covers).
The simplest business analogy
If MLOps is about maintaining a specialized factory machine, AgentOps is about managing a team of autonomous workers.
A model predicts. An agent decides, sequences actions, invokes tools, handles exceptions, and sometimes interacts with customers or core systems. That means the operational question shifts from "Is the model accurate?" to "Did the agent complete the task within the rules, at the right cost, with a traceable decision path?"
Where the scope expands
MLOps usually centers on model performance and deployment reliability. AgentOps services must handle a wider surface area:
| Operational area | MLOps focus | AgentOps focus |
|---|---|---|
| Core unit | Model | Agent and workflow |
| Main concern | Prediction quality | Task execution quality |
| Monitoring target | Drift, latency, accuracy | Reasoning steps, tool use, refusals, cost, escalation |
| Governance need | Model lifecycle control | Action control and auditability |
| Business risk | Poor output | Poor action |
That difference changes procurement. If you're buying infrastructure for agents, standard model monitoring won't solve your core problems. You need instrumentation around workflows, permissions, and business outcomes. That's especially important when the architecture includes APIs, tools, retrieval systems, and handoffs across internal applications, which is why teams with strong API architecture for AI systems usually mature faster in AgentOps.
What business leaders should actually ask
The right questions are operational, not academic:
- Can we see how an agent reached a result?
- Can we limit which tools it may use and under what conditions?
- Can we prove when a human reviewed a high-stakes step?
- Can we connect cost and latency to task value?
If the answer is no, you don't yet have AgentOps. You have agents running.
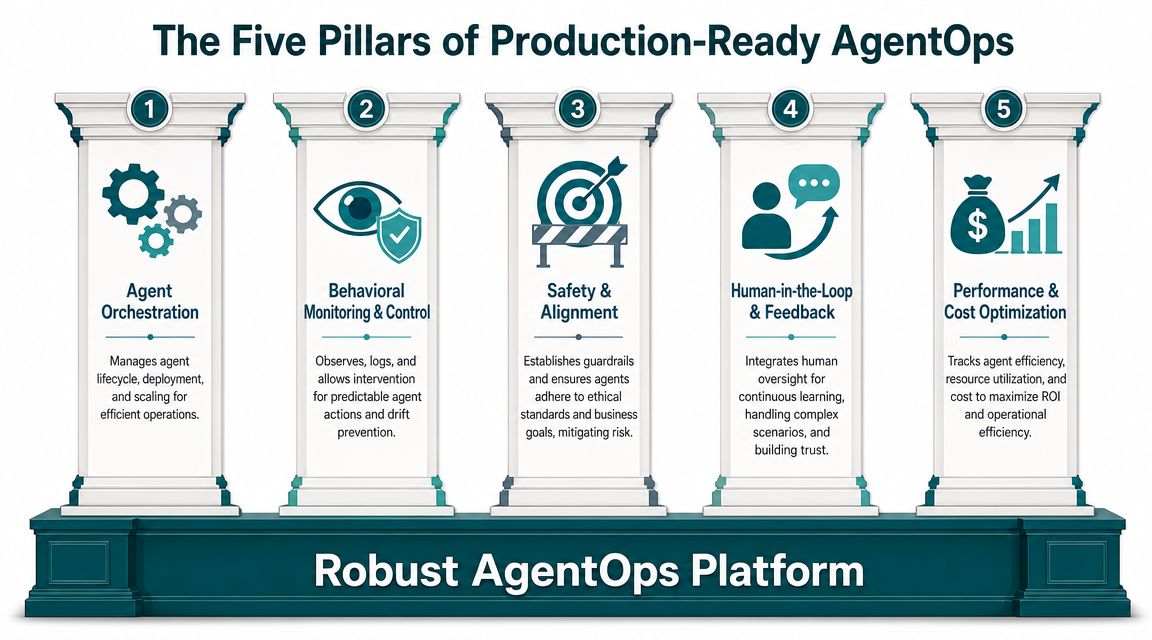
The Five Pillars of Production-Ready AgentOps
A production system doesn't fail because one prompt was weak. It fails because the operating model is incomplete. In practice, effective AgentOps services rest on five pillars. If one is missing, the business feels it quickly.
Teradata's guidance is useful here because it gets concrete. It notes that AgentOps adds production controls beyond standard MLOps by managing an agent's multi-step reasoning, tool scoping, refusal behavior, and traceability. Teradata recommends instrumenting agent steps and tool calls with spans, hashing sensitive inputs instead of logging raw values, and enforcing token-budget and p95-latency SLOs so cost, latency, and compliance remain measurable in production (Teradata on production controls for AI agents).
Deployment and orchestration
This is the workflow layer. It governs how agents start, how they call tools, how they hand work to other agents or humans, and how failures get contained.
What works is explicit orchestration with defined states. What fails is letting a general-purpose agent improvise across too many business-critical steps. If your support agent can both classify a ticket and issue an account action, those should be separate capabilities with clear routing rules.
Monitoring and observability
Monitoring an agent isn't just uptime and response time. You need visibility into the path it took.
A useful observability setup answers questions like these:
- Step trace: Which actions did the agent attempt before finishing?
- Tool trace: Which systems did it touch, in what order?
- Decision trace: Where did it refuse, retry, or escalate?
- Business trace: Did the workflow resolve the issue, reduce queue time, or create rework?
Practical rule: If you can't reconstruct an agent decision after an incident, you don't have production observability yet.
Security and guardrails
This pillar decides whether your agent is a safe operator or a future incident report. Tool permissions matter more than prompt polish once agents act on live systems.
Good controls usually include bounded permissions, scoped credentials, action policies, and approval gates for sensitive tasks. Weak controls look like a broad API key and a vague instruction that says "be careful."
Cost and performance control
Under these conditions, many pilots lose executive support. The agent may be useful, but if it burns tokens on low-value steps or waits too long on chained tool calls, the ROI case collapses.
Teams that run agents well treat cost and latency as managed constraints, not side effects. They set token budgets by workflow, track latency at the task level, and decide where a lighter model or simpler path is good enough. For teams hardening these systems in cloud environments, the same operational discipline used to test cloud workflows before scale-up applies directly here.
Human in the loop and feedback
Fully autonomous agents sound attractive. In business operations, selective oversight usually wins.
A strong pattern is simple: let the agent do the repetitive work, then require review on high-stakes moments. That might mean a collections agent drafts an email but a human approves the send, or a compliance agent prepares a decision package but routes edge cases to an analyst.
A practical operating checklist
| Pillar | What good looks like |
|---|---|
| Orchestration | Defined workflow states and failure paths |
| Observability | Step-level traces tied to business tasks |
| Guardrails | Least-privilege tool access and approval rules |
| Cost control | Token budgets and latency thresholds by use case |
| Human oversight | Escalation paths and review queues for exceptions |
Calculating the ROI of AgentOps Services
Most ROI discussions around AI stay too abstract. They focus on capability, not economics. That's a mistake. AgentOps services should be bought and measured the same way you'd measure any operational system: by the value of outcomes minus the cost of achieving them.
Start with one workflow, not a platform narrative
If you try to justify AgentOps as a broad innovation program, the economics get fuzzy fast. Start with a specific workflow where agents already do meaningful work or should.
A few examples make this practical:
- Fintech operations: An agent handles KYB document intake, extracts fields, checks completeness, and prepares a review package.
- Manufacturing quality: A vision-enabled agent flags defect events, routes evidence, and triggers a plant workflow.
- Legal operations: An agent reviews incoming documents, classifies matter type, drafts summaries, and escalates exceptions.
The ROI model is straightforward. Estimate the current cost of the workflow. Then compare it with the cost of the agentized version, including service fees, model usage, review time, and incident handling.
Use three ROI buckets
The business case usually comes from a mix of these:
Cost savings
This is the easiest place to start. Count manual hours reduced, duplicate handling removed, and queue management effort eliminated.
For example, if invoice-heavy workflows still depend on people rekeying documents or checking edge cases manually, the cost baseline is visible. Teams already exploring invoice OCR in AI operations often find AgentOps becomes necessary once those document workflows trigger downstream actions instead of simple extraction.
Revenue enablement
Some agents create value by improving speed to action. Faster lead qualification, shorter response cycles, and quicker onboarding all matter when they move deals or retention.
This category is harder to model, so be conservative. Tie it to a business event you can observe, such as shorter time to first response or faster handoff to sales.
Risk reduction
This is the bucket many leaders underweight. If an agent can send messages, alter records, or trigger transactions, controls have financial value even when they don't show up as labor savings.
The most credible AgentOps ROI models include avoided rework, avoided incidents, and reduced exception-handling effort. Not just labor substitution.
Measure outcomes, not activity
Avoid vanity metrics like number of prompts, number of agents deployed, or raw automation rate. Better KPIs include:
- Task completion quality
- Cost per completed workflow
- Escalation rate for high-risk actions
- Time to resolution
- Exception rework volume
If your vendor reports mostly technical dashboard metrics, ask them to map each one to a business KPI. If they can't, the service may be operationally neat but commercially weak.
How to Select an AgentOps Vendor or Partner
A common failure pattern looks like this. The team gets an agent into production, usage grows fast, and only then do leaders discover no one can answer three basic questions with confidence: who approved its actions, what it changed, and whether the workflow is paying for itself.
That is the essential vendor decision.
The practical choice is whether your business can stand up an operating layer quickly enough to control production agents across security, finance, compliance, and operations. Software matters, but the larger risk sits in process ownership. A weak AgentOps setup creates spend drift, permission creep, unclear accountability, and slow incident response.
When building in-house makes sense
Build internally when agentic workflows are core to your competitive model and you already have strong platform engineering, security, and operational governance. It also fits cases where the workflows are unusually specific or the control requirements are too bespoke for an outside partner to handle efficiently.
The hidden cost is coordination.
Engineering can assemble tools. The harder part is getting security reviews, approval policies, runbooks, exception handling, KPI instrumentation, and business ownership in place at the same time. If those pieces come together late, the business ends up with agents that work technically but remain hard to trust operationally.
For many firms, the deciding factor is not technical capability. It is time to a controlled operating model.
What to demand from a partner
A partner should be able to show how they will run your agent operations, not just what they will install. Ask them to walk through a real workflow from trigger to action to exception. If that walkthrough stays at the dashboard level, keep digging.
Strong partners usually make five things clear:
- Scope of authority. Which actions can the agent take, in which systems, under what approval rules.
- Evidence trail. What gets logged, how reviews are recorded, and what an auditor or operator can reconstruct after the fact.
- Exception handling. How high-risk or ambiguous cases get routed to a person, and how fast that handoff happens.
- Business accountability. Which workflow KPI they are expected to improve, protect, or stabilize.
- Commercial alignment. Whether the engagement is tied to outcomes or to hours, licenses, and implementation tasks.
If your team needs help framing that decision inside a broader transformation plan, use an AI adoption roadmap for enterprise operating priorities before you start vendor selection. It prevents a tooling purchase from masquerading as an operating strategy.
AgentOps partner evaluation checklist
| Evaluation Criterion | What to Look For |
|---|---|
| Business KPI alignment | They define success in workflow outcomes, not just uptime or prompt quality |
| Operating model | They show how agents are approved, monitored, overridden, and reviewed |
| Tool access control | They can enforce scoped permissions and action boundaries |
| Auditability | They retain evidence of actions, approvals, and exceptions |
| Escalation design | They provide human review paths for sensitive cases |
| Cost governance | They track spend by workflow and tie it to business value |
| Incident handling | They have a process for failure review, rollback, and remediation |
| Integration depth | They can connect agents to your existing systems without creating brittle workarounds |
| Reporting quality | They produce reports your operations, security, and finance teams can all use |
| Commercial model | They can work in an outcomes-oriented engagement, not only time-and-materials |
A better procurement lens
Procure AgentOps the way you would procure a managed operational capability. Ask which business process the partner will stabilize, which KPI they will report against, what evidence they will provide each month, and how they will handle exceptions, rework, and policy breaches.
That changes the buying criteria. A vendor selling orchestration features may still be the wrong choice if they cannot own measurable operating performance. The better question is not whether they have observability, guardrails, or approval flows. The better question is whether those controls reduce cost per workflow, lower exception volume, improve throughput, or contain operational risk.
AmasaTech is one example of this model. The firm structures AI engagements around outcome-as-a-service, starting with an AI audit and tying delivery to business KPIs such as accuracy, throughput, cost, or revenue impact. That is the standard to look for, whether you choose that provider or another one.
If a vendor can demo tooling but cannot explain how a disputed agent action would be reviewed, documented, and resolved, you are buying software support, not AgentOps.
Your Phased Roadmap to AgentOps Maturity
Many teams don't need a grand transformation plan. They need a sequence that reduces risk while increasing trust. A phased roadmap does that better than a big-bang rollout.

Phase one pilot and assess
Pick one workflow with clear boundaries and low downside if the agent underperforms. The goal isn't maximum automation. The goal is to establish a baseline and learn where the workflow breaks.
Good pilot KPIs are operationally simple:
- Completion rate for the target task
- Average review effort per task
- Failure or escalation reasons
- Cost per completed run
Teams at this stage often benefit from a broader AI adoption roadmap for the business so the pilot doesn't become an isolated experiment.
Phase two scale and standardize
Once one workflow is stable, add more. At this stage, many teams move too fast. They replicate agents before standardizing permissions, observability, and governance.
A better approach is to standardize the operating layer first. Define common logging, approval rules, runbooks, and KPI reporting. Only then expand into adjacent use cases.
What should become standard
| Area | Standard to establish |
|---|---|
| Monitoring | Shared trace and incident review format |
| Security | Common permission scoping rules |
| Workflow design | Reusable escalation and fallback patterns |
| Reporting | Shared business KPI dashboard |
Phase three optimize and automate
At this point, the basic controls exist. Now you can improve routing, add specialized sub-agents, tighten review triggers, and automate parts of the feedback loop.
The important shift is that optimization should happen against business metrics, not novelty. If a multi-agent workflow is more elegant but harder to audit, it may be the worse design. Mature AgentOps favors controlled complexity.
Mature teams don't aim for the most autonomous system. They aim for the highest level of autonomy the business can reliably govern.
From Agentic AI Strategy to Measurable Outcomes
The strategic mistake is treating agents like software features. They behave more like a new operating layer inside the business. They need controls, review paths, measurable service levels, and clear ownership.
That's why AgentOps services matter. They turn agentic AI from a promising capability into a managed business function. Without that layer, most companies end up with scattered pilots, uneven trust, and poor visibility into cost or risk.
The procurement model matters too. Buying AgentOps as licenses and implementation hours often misaligns incentives. The client pays for activity. The provider gets rewarded for shipping systems, not for making them deliver measurable results.
An outcomes-as-a-service model fixes that. It anchors the engagement on business KPIs such as throughput, cost, accuracy, cycle time, or controlled escalation quality. That changes the conversation from "How many agents did we deploy?" to "Which operational outcomes improved, and can we prove it?"
For business leaders, that's the maturity shift. You stop funding AI as experimentation and start managing it as accountable operations.
If you're evaluating AgentOps services and want a partner that starts with AI readiness, maps automation to business KPIs, and structures delivery around measurable outcomes, talk with AmasaTech about an AI audit and phased implementation approach.