
AI in Clinical Trials: A Practical Implementation Guide
Only a small share of AI ideas in clinical development ever make it into validated, repeatable operations. That gap matters more than market excitement, because executive teams do not fund experiments indefinitely. They fund cycle-time reduction, lower screening costs, better enrollment performance, and clearer portfolio decisions.
For clinical leaders, the question is not whether AI has interesting applications. The critical question becomes where AI can produce measurable gains with data you already have, controls your quality team can sign off on, and workflows your study teams will use. That is the shift from innovation theater to ROI.
We see the same pattern across industries. Companies get returns from AI after they connect use cases to operational bottlenecks, data readiness, and adoption discipline, not by buying more tools. AmasaTech outlined that pattern in this review of companies getting results from AI transformation.
In clinical trials, that usually starts with one hard-nosed assessment. Which delays, handoffs, and manual reviews are expensive enough to fix first, and which of them can be improved with the data, governance, and validation standards already in place. That is the implementation journey that matters.
The Tipping Point for AI in Clinical Trials
Clinical AI spending is rising fast, but the investment signal matters less than what it reflects inside sponsor and CRO operations. Budget is shifting because AI has moved into workflow decisions that affect trial timelines, screening cost, monitoring effort, and protocol execution. That is the tipping point.
What changed is not interest. Interest has been there for years. What changed is execution discipline.
Clinical teams now have enough digital exhaust to improve specific steps in the study lifecycle. Eligibility criteria sit in documents and systems. Patient history lives across structured fields and notes. Site performance data, safety narratives, imaging, and operational logs all contain patterns that used to require slow manual review. AI can now classify, rank, summarize, and flag that information at a speed that fits daily operations, if the data is usable and the review process is clearly defined.
Pressure from the business side is also sharper. Development leaders are being asked to cut cycle time, protect quality, and make better resource decisions at the same time. In that environment, AI gets approved when it reduces a known bottleneck. It does not get approved because the model is impressive.
The strongest programs usually start small. They focus on a narrow decision or review task, assign one accountable owner, define one or two operational metrics, and validate output quality before expanding scope. That pattern shows up across sectors, not just healthcare, and it is visible in these examples of companies getting results from AI transformation.
A practical test helps here. If a proposed AI use case cannot be tied to startup speed, enrollment efficiency, site productivity, monitoring workload, or safety review time, it is still an experiment. If it can improve one of those metrics without adding a second layer of manual checking, it is worth serious evaluation.
That last point is where many teams get stuck. An AI system that saves analysts 30 minutes but creates 40 minutes of QA review is not progress. The tipping point arrives when the workflow, controls, and data quality are mature enough that AI reduces work instead of relocating it.
For executives, the implication is straightforward. The risk is no longer limited to missing a technology trend. The larger risk is continuing to fund high-cost manual processes that can now be shortened, prioritized, or standardized with acceptable validation and oversight.
That does not mean every sponsor should build custom models or buy a broad platform. The better first move is usually an operating review. Identify where teams search across disconnected systems, reconcile conflicting records, review free text at scale, or make repeat judgment calls with partial information. Those are the places where AI is most likely to produce measurable ROI within the controls clinical organizations already require.
Five Core Applications of AI in Clinical Research
A practical discussion of AI in clinical trials starts with jobs, not models. What work is the system doing that people currently do too slowly, too inconsistently, or at too high a cost?
A useful market signal comes from adoption itself. A Medidata survey found that 93% of clinical trial executives are using or actively investigating AI in 2025, and FDA experts have described AI as useful for site selection, recruitment, dropout prediction, and real-time safety monitoring in a 2024 FDA discussion on AI in clinical trial design and research.

Patient recruitment and selection
Recruitment is usually the first place executives look, and for good reason. Manual screening is slow, eligibility criteria are often complex, and matching patients across fragmented records takes time that study teams rarely have.
AI helps when it acts as a ranking and triage layer. It can parse inclusion and exclusion criteria, scan structured and unstructured patient data, and surface likely candidates for human review. The key phrase is for human review. In practice, the strongest implementations don't auto-enroll anyone. They reduce the review universe and improve the quality of the first pass.
What works:
- Criteria parsing: Translate protocol language into machine-readable logic.
- Record prioritization: Flag patients with the strongest likely fit first.
- Prescreening support: Route uncertain cases to coordinators instead of burying them.
What usually fails:
- Over-automation: Teams trust the model as a final eligibility engine.
- Weak data mapping: Required fields exist, but they aren't standardized across systems.
- No clinician feedback loop: The model keeps making the same avoidable mistakes.
Organizations exploring this area often start with adjacent workflow automation such as automated patient data extraction for healthcare records, because extraction quality determines whether downstream recruitment models are useful at all.
Trial design and protocol optimization
Protocol design decisions create downstream costs. If inclusion criteria are too narrow, enrollment slows. If endpoints are hard to capture consistently, sites struggle. If procedures create unnecessary burden, dropout risk rises.
AI can support protocol optimization by learning from historical trial patterns, site performance data, and operational feedback. It won't replace clinical judgment, but it can pressure-test assumptions before those assumptions become amendments.
Practical rule: Use AI here to identify likely friction points early, not to make final protocol decisions on its own.
Strong teams use models to ask sharper questions:
- Which eligibility rules are likely to create avoidable screening burden?
- Which site profiles are best aligned to this protocol's recruitment needs?
- Where are operational demands likely to exceed site capacity?
Site monitoring and data management
Monitoring is full of repetitive review work. Data checks, missing fields, query generation, source alignment, and anomaly detection all create administrative drag. AI is most useful here when it reduces the amount of low-value inspection humans need to do.
A model can flag records that look unusual, identify inconsistent entries, or prioritize sites that deserve closer attention. The operational win isn't “hands-free monitoring.” It's focused monitoring.
A good deployment changes the workflow from “review everything” to “review what the model says is most likely to matter.”
Imaging and biomarker analysis
Trials that depend on imaging or signal-heavy biomarker review often face consistency problems. Different readers can focus on different features, and review queues can slow decisions.
Computer vision and pattern-recognition systems can help by standardizing first-pass analysis, surfacing suspect scans, or organizing visual findings for specialist review. This is one of the clearest examples of AI as augmentation. The technology's value comes from speed, consistency, and prioritization. Clinical interpretation still belongs with qualified experts.
Safety signal detection
The FDA discussion referenced earlier noted AI's role in real-time safety monitoring and in identifying clusters of signs and symptoms that may indicate safety concerns. Natural language processing becomes especially useful in this context, as safety information frequently resides in narratives, reports, notes, and loosely structured documentation rather than solely in clean fields.
The practical application is straightforward. AI can read more text than a human team can reasonably process in the same time window, cluster similar observations, and escalate cases for investigation. The hard part isn't building the model. It's designing a governance process so safety, clinical, and regulatory teams know when to trust the alert, when to challenge it, and how to document the response.
Measuring the Impact and Calculating ROI
Most AI programs in clinical development fail at the business-case stage for a simple reason. They describe capability, not economic value.
Executives don't fund “better insights.” They fund shorter timelines, fewer avoidable delays, lower review burden, stronger enrollment execution, and better use of specialist time. If your team can't connect the model to those outcomes, you don't have an ROI story yet.

Start with operational economics
A solid ROI model in clinical trials usually has four components:
| Value driver | What to measure | How to think about impact |
|---|---|---|
| Recruitment efficiency | Time to identify and review candidates | Faster enrollment can reduce downstream schedule pressure |
| Study execution quality | Protocol deviations, data queries, rework volume | Fewer avoidable errors mean less remediation effort |
| Monitoring productivity | Reviewer time, prioritized case volume, manual review load | Teams spend more time on high-risk issues |
| Retention and continuity | Dropout risk flags, intervention timing, follow-up completion | Earlier intervention may preserve participant continuity |
The best metric set is the one your finance, clinical operations, and study leadership teams already review. Don't create an AI-only scorecard that lives outside the operating business.
Use ROI formulas your leadership team already accepts
A practical formula is simple:
ROI = (financial value created or cost avoided – total implementation cost) / total implementation cost
The challenge is estimating value credibly. In regulated environments, that means using internal baselines instead of broad industry assumptions.
Examples of internal calculations:
- Recruitment workflow: Compare coordinator hours spent on manual prescreening before and after AI-assisted triage.
- Monitoring workflow: Measure whether reviewers resolve more meaningful issues per hour when anomaly detection ranks cases.
- Protocol planning workflow: Estimate the cost of preventable rework that earlier risk identification could avoid.
If a team can't identify a baseline, it should pause deployment and instrument the workflow first.
The fastest way to lose confidence in an AI program is to launch it without a before-state. Then every benefit becomes an argument instead of a measurement.
Separate hard ROI from strategic ROI
Some returns show up directly in budget and labor. Others improve trial economics indirectly.
Hard ROI usually includes:
- Reduced manual review time
- Lower administrative burden
- Better use of specialized clinical staff
- Less rework in repetitive data workflows
Strategic ROI often includes:
- Faster study decisions
- Better site allocation choices
- Stronger executive confidence in forecasting
- More consistent operating processes across studies
Both matter. The mistake is mixing them together and calling all of it “savings.”
To keep the program credible, assign each initiative a short measurement plan:
- Primary KPI
- Baseline
- Review cadence
- Executive owner
- Stop or scale criteria
That operating discipline is what turns AI from an innovation initiative into a managed portfolio. Teams that need a tighter operating layer often benefit from a formal approach to AI transformation progress monitoring, especially when multiple pilots compete for budget and leadership attention.
Navigating Key Regulatory and Ethical Guardrails
AI in clinical trials doesn't break because the model is weak. More often, it breaks because governance is vague.
If a system influences recruitment, site selection, monitoring, or safety review, leaders need clear answers to basic questions. Who validates it? Who overrides it? What gets logged? What happens when the output conflicts with clinical judgment? If those answers are missing, adoption stalls even when the technical output looks promising.
Bias and representativeness need operational answers
One of the most common claims in AI discussions is that better matching will improve trial diversity. That claim is incomplete.
Recent academic commentary highlights a harder challenge. AI can help identify underrepresented populations and geographic areas with limited trial access, but improved screening alone doesn't solve structural barriers. Travel burden, site placement, patient education, and local outreach still determine who can enroll, as discussed in this ASCO publication on equitable trial access.
That has direct implications for implementation:
- Audit recruitment geography: Don't just ask where eligible patients are. Ask where your current site network underserves them.
- Review exclusion logic: Some criteria may create bias before outreach even starts.
- Match outreach resources to model findings: If AI identifies underserved regions, operations must decide what support follows.
The ethical standard isn't “the model found more people.” It's whether the program helped the organization reach people it usually misses.
Human oversight is part of the design
The most effective AI governance frameworks treat human review as a design feature, not a fallback. That matters in every high-stakes workflow, but especially in recruitment decisions, participant monitoring, and safety escalation.
A useful internal policy usually covers:
- Intended use: What the model is allowed to do
- Human authority: Who makes final operational decisions
- Escalation rules: Which outputs require review
- Documentation standards: How decisions and overrides are recorded
- Model review cycle: When performance gets reassessed
This isn't bureaucratic overhead. It's what keeps the organization from deploying a tool that creates more compliance risk than operational value.
If your team can't explain a model's role in one sentence and its human override path in one more, it isn't ready for production.
Privacy, trust, and accountability
Clinical AI projects also fail when data use assumptions are sloppy. Teams need explicit rules around access, retention, de-identification, vendor controls, and auditability. In healthcare, trust is operational. If investigators, compliance teams, and site staff don't trust how the system handles data and recommendations, they won't use it consistently.
That's why legal and governance planning should start before procurement, not after pilot success. Organizations that need a structured starting point often benefit from specialized guidance on AI legal consulting for startups and regulated businesses, particularly when they're moving from internal prototypes to production systems.
The Essential Data Readiness Checklist
Most failed AI deployments in clinical research share one root cause. The organization starts with a use case before it understands its data reality.
That's backwards. In AI in clinical trials, readiness isn't a technical checklist for the data science team alone. It's an executive-level audit of whether the organization can supply trustworthy inputs, govern access, and support the workflow after deployment.

Availability and accessibility
Start with a blunt question: can the teams who need the data get it in usable form?
Many organizations technically “have” the data but can't operationalize it because it's locked across EDC platforms, EHR systems, imaging repositories, spreadsheets, PDFs, and email-driven processes. AI systems struggle when each workflow starts with manual gathering and reconciliation.
Check these first:
- Data location: Do you know where protocol, patient, site, and operational data currently lives?
- Access path: Can approved teams retrieve it without custom one-off effort each time?
- Format mix: How much of the relevant information is structured versus free text, image, or document based?
If access is slow, the model won't fix the workflow. It will inherit the bottleneck.
Quality and consistency
Poor data quality doesn't always look dramatic. More often it shows up as small inconsistencies that wreck model reliability. Site names vary. Fields are partially filled. Eligibility concepts are captured differently across systems. Notes contain shorthand that only experienced coordinators understand.
Use this self-audit:
- Completeness: Are key fields consistently present?
- Standardization: Do equivalent terms map cleanly across sources?
- Freshness: Is the data current enough for operational use?
- Error handling: Who corrects obvious issues, and how quickly?
A useful rule is to test one narrow workflow manually before training anything. Pull a sample, review it with operators, and document the failure modes. That exercise usually reveals whether the problem is model choice or input quality.
Governance and infrastructure
Governance isn't only about compliance. It determines whether the AI workflow can scale.
Ask:
- Ownership: Which team owns each source of truth?
- Permissions: Who approves access and downstream use?
- Auditability: Can you reconstruct what data informed an output?
- Security controls: Are protected datasets handled under clear policy?
- Infrastructure fit: Can your environment support ingestion, processing, monitoring, and retention without fragile workarounds?
A simple readiness scorecard can help leadership decide whether to proceed.
| Readiness area | Green signal | Warning sign |
|---|---|---|
| Data access | Cross-functional teams can retrieve approved datasets reliably | Each request requires manual escalation |
| Data quality | Common fields are well defined and reviewable | Teams argue over which dataset is “right” |
| Governance | Ownership and access rules are documented | Access depends on informal relationships |
| Infrastructure | Systems support repeatable AI workflows | Pilots rely on temporary exports and local fixes |
Teams that want a broader assessment model can use an AI readiness checklist for enterprise adoption as a starting framework, then adapt it to realities of regulated clinical operations.
Your Phased AI Implementation Roadmap
Most organizations shouldn't begin with a moonshot. They should begin with a workflow that's painful, measurable, and narrow enough to govern well.
That's the difference between AI theater and an AI operating model. A mature roadmap doesn't ask, “Where can we use AI?” It asks, “Which implementation sequence creates confidence, evidence, and internal capability?”
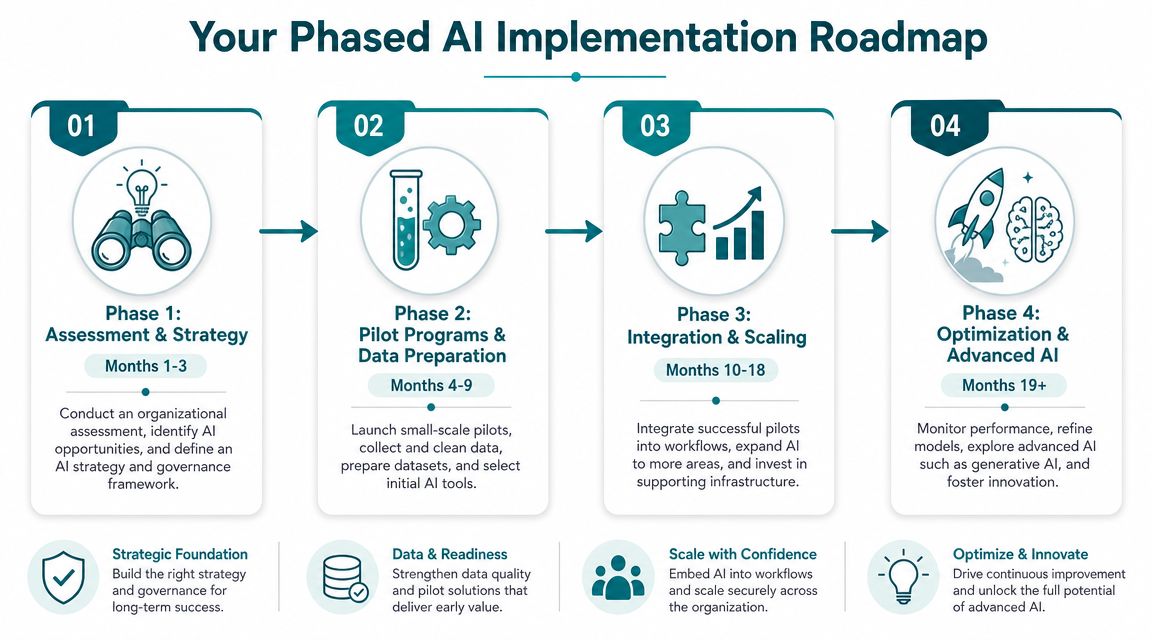
Phase 1 assessment and workflow selection
The first phase is diagnostic, not technical. Pick one or two trial operations workflows that meet four criteria:
- High friction
- Clear owner
- Available data
- Measurable baseline
Good candidates often include patient prescreening support, site feasibility survey categorization, document classification, protocol text extraction, or safety narrative triage. These workflows are usually repetitive enough to benefit from automation and bounded enough to validate safely.
Leadership should insist on three outputs before any pilot starts:
- Business problem statement
- Decision rights and governance owner
- Primary KPI with baseline
If the team can't produce those quickly, the organization isn't choosing a use case. It's browsing.
Phase 2 pilot with controlled scope
The best pilot programs are small, instrumented, and hard to misunderstand. They don't try to transform the full study lifecycle. They aim to prove that a specific AI intervention improves a specific step.
Examples of sensible pilot scopes:
- AI-assisted eligibility triage for one study area
- NLP categorization of site responses
- Intelligent extraction from patient records or investigator documents
- Monitoring support that ranks records for reviewer attention
During the pilot, evaluate three things separately:
- Model performance
- Workflow fit
- User adoption
A model can perform well in testing and still fail in operations if it creates too many edge cases or forces staff into awkward review steps.
Start with the decision that consumes time, not the model that seems most sophisticated.
Phase 3 integration into operating workflows
Once a pilot proves useful, the next challenge is integration. Many programs stall at this point. The AI output exists, but it lives outside the core workflow, so staff copy results manually or ignore them.
Integration work usually includes:
- Connecting outputs to existing systems or review queues
- Defining exception-handling rules
- Training staff on when to trust and when to challenge the tool
- Logging actions and overrides for auditability
- Establishing ongoing performance monitoring
The target state is simple. The AI output should appear where the work already happens.
Phase 4 scaling and portfolio management
After one or two successful deployments, leaders should shift from project mode to portfolio mode. That means prioritizing initiatives based on business value, data readiness, regulatory fit, and implementation complexity.
The table below helps frame that progression.
Phased AI Initiatives From Quick Wins to Long-Term Value
| Initiative Example | Phase | Potential KPIs | Complexity |
|---|---|---|---|
| Protocol text extraction and classification | Quick win | Review time, manual abstraction effort, extraction accuracy | Low |
| Site feasibility survey categorization | Quick win | Time to summarize responses, reviewer workload, turnaround time | Low |
| AI-assisted patient prescreening | Quick win to strategic | Coordinator review burden, candidate prioritization quality, time to outreach | Medium |
| Dropout risk prediction | Strategic | Timeliness of intervention, retention workflow responsiveness, case review quality | Medium to high |
| Imaging review prioritization | Strategic | Queue management, specialist review efficiency, consistency of first-pass triage | High |
| Safety narrative clustering and escalation support | Long-term value | Alert handling workflow, review speed, signal investigation efficiency | High |
Strong scaling decisions usually follow a few rules:
- Standardize governance before multiplying pilots
- Reuse data pipelines where possible
- Retire weak pilots quickly
- Keep a human owner accountable for every production model
The roadmap matters because it protects the organization from two common mistakes. One is waiting too long and treating AI as a future issue. The other is moving too fast and deploying tools without the operating discipline needed in clinical environments.
Building Your AI-First Clinical Future
The organizations getting real value from AI in clinical trials aren't the ones with the most ambitious language. They're the ones that connect a real operational problem to the right data, the right workflow, and the right governance model.
That usually starts smaller than executives expect. One recruitment bottleneck. One data-review burden. One safety workflow that needs better prioritization. When that first implementation is measured properly, it does more than improve a process. It gives the organization a repeatable way to evaluate every next AI decision.
The sequence matters. Confirm data readiness first. Choose a workflow with a clear owner. Pilot narrowly. Measure against a baseline. Add governance before scale, not after. Then expand into higher-value use cases once teams trust the operating model.
Clinical development doesn't need more AI enthusiasm. It needs better execution. The winners in this category will be the organizations that treat AI as a disciplined capability embedded in trial operations, not a side experiment run by innovation teams alone.
The first useful step is rarely procurement. It's an internal audit. Find the workflow that drains time, creates rework, or delays decisions. Then ask whether better data use, supported by AI, can improve that workflow in a way your business can measure.
AmasaTech helps organizations move from AI curiosity to operational results with a structured audit, phased roadmap, and KPI-tied delivery model. If you're evaluating AI in clinical trials and want a practical plan grounded in readiness, workflow design, and measurable outcomes, explore AmasaTech.