
AI Orchestration: Scale AI & Achieve Results
Your first AI win usually looks deceptively complete.
A support chatbot works. A forecasting model helps the revenue team. A document pipeline saves analysts hours. Then the next request lands. Connect it to the CRM. Add approval logic. Pull in product data. Route edge cases to a human. Log every decision for compliance. Suddenly the model that looked valuable on its own starts behaving like a disconnected tool that nobody can safely scale.
That's the point where most companies realize the hard part of AI isn't getting one model to work. It's getting multiple systems to work together reliably, with clear ownership, measurable outcomes, and operating rules the business can trust.
Introduction Beyond Your First AI Success
A founder launches an internal AI assistant. It answers questions from company docs and saves time immediately. A month later, sales wants it connected to pricing data. Customer success wants it to summarize account history. Legal wants an approval step before sensitive answers go out. Ops wants to know when it fails, why it fails, and who touched the workflow last.
The assistant didn't stop being useful. It just stopped being enough.
That's where ai orchestration enters the picture. Not as a flashy feature, and not as another isolated tool, but as the operating layer that turns separate AI experiments into a coordinated business capability. It connects models, data sources, APIs, workflows, and governance so teams can scale beyond a single successful demo.

The shift is already large enough to matter commercially. Grand View Research estimates the global AI orchestration market at USD 9.76 billion in 2024 and projects it to reach USD 58.92 billion by 2033, with a 22.4% CAGR from 2025 to 2033 according to its artificial intelligence orchestration market report. That's not the profile of an experimental niche. It's the profile of an infrastructure category.
The wall most teams hit
The first wall is usually integration. One model works, but every new use case requires custom glue code, another prompt layer, another manual handoff, and another exception process.
The second wall is accountability. Leaders ask reasonable questions:
- Who owns output quality: Is it the data team, engineering, ops, or the vendor?
- What happens on failure: Does the system retry, escalate, or stop?
- Which KPI improves: Throughput, cost, accuracy, conversion, or cycle time?
- Can we govern it: Are there logs, permissions, human approvals, and auditability?
Without orchestration, those questions pile up faster than value.
Practical rule: If your AI system now depends on more than one model, more than one data source, or more than one team, you're no longer managing a tool. You're managing an operating system.
Why this matters now
The companies moving fastest aren't the ones with the most pilots. They're the ones turning isolated use cases into repeatable systems. That means choosing where AI should plug into the business, which handoffs should stay automated, and where controls need to be explicit.
If you're looking at where this goes next, examples like these real-world generative AI deployments are useful because they show the pattern clearly. Value starts with one use case, but scale only happens when the surrounding workflow becomes coordinated, governed, and measurable.
What AI Orchestration Really Means for Your Business
Think of an orchestrator the way you'd think of a conductor. The conductor doesn't play every instrument. The conductor decides who enters when, what depends on what, how the timing holds, and what happens when one section is off.
In business terms, ai orchestration is the layer that coordinates models, data, APIs, and agents so they work as one system instead of a stack of disconnected components. Industry descriptions from IBM and Automation Anywhere frame it this way, emphasizing coordination inside a unified system, along with governance, compliance, and measurable outcomes as core reasons companies invest. IBM outlines that perspective in its explanation of AI agent orchestration.
It's not the same as workflow automation
A standard workflow engine can move a task from Step A to Step B. That's useful, but limited. AI orchestration has to do more because AI outputs are variable, context-sensitive, and sometimes wrong.
That means the orchestration layer often needs to handle:
- Model selection: Which model should answer this request?
- Context routing: Which data source or tool should the model use?
- Fallback logic: What happens if confidence is low or a tool call fails?
- Approval rules: When should a human review the result?
- Operational controls: What gets logged, monitored, and audited?
Simple automation assumes predictability. Orchestration exists because AI systems don't always behave predictably.
What leaders should hear in the definition
The business meaning is straightforward. Orchestration is the bridge between model-centric work and process-centric results.
A model can classify, generate, summarize, or predict. But businesses don't buy models for their own sake. They buy outcomes. Faster case handling. Lower processing cost. More consistent support. Fewer manual reviews. Better decision support.
A good orchestrator doesn't make your models look smarter. It makes your business process more dependable.
That distinction matters. Teams often over-focus on prompt quality or model choice while under-investing in coordination. The result is a powerful model trapped inside a weak delivery system.
What changes when you treat it strategically
Once you frame orchestration as a business capability, the design questions improve:
| Business question | Weak AI setup | Orchestrated AI setup |
|---|---|---|
| How does work move? | Ad hoc scripts and manual handoffs | Defined routing and dependencies |
| How do teams change models? | High friction, brittle integrations | Modular swaps with lower disruption |
| How do you govern actions? | Inconsistent rules by use case | Centralized policy, approvals, and logs |
| How do you measure value? | Isolated feature metrics | KPI-linked process performance |
This is why orchestration becomes the true maturity test. A company with one useful model has AI capability. A company with orchestration has the beginnings of an AI engine.
The Core Components of an AI Orchestration Platform
Most executives don't need a low-level architecture diagram. They do need to know what capabilities they're buying, what those capabilities protect, and where they provide an advantage.
AI orchestration platforms matter because they separate work into automation, integration, and management pillars. That modular structure lets a company swap or scale models without rewriting the entire application, which reduces friction and supports secure, auditable operations, as described in HatchWorks' overview of AI orchestration.
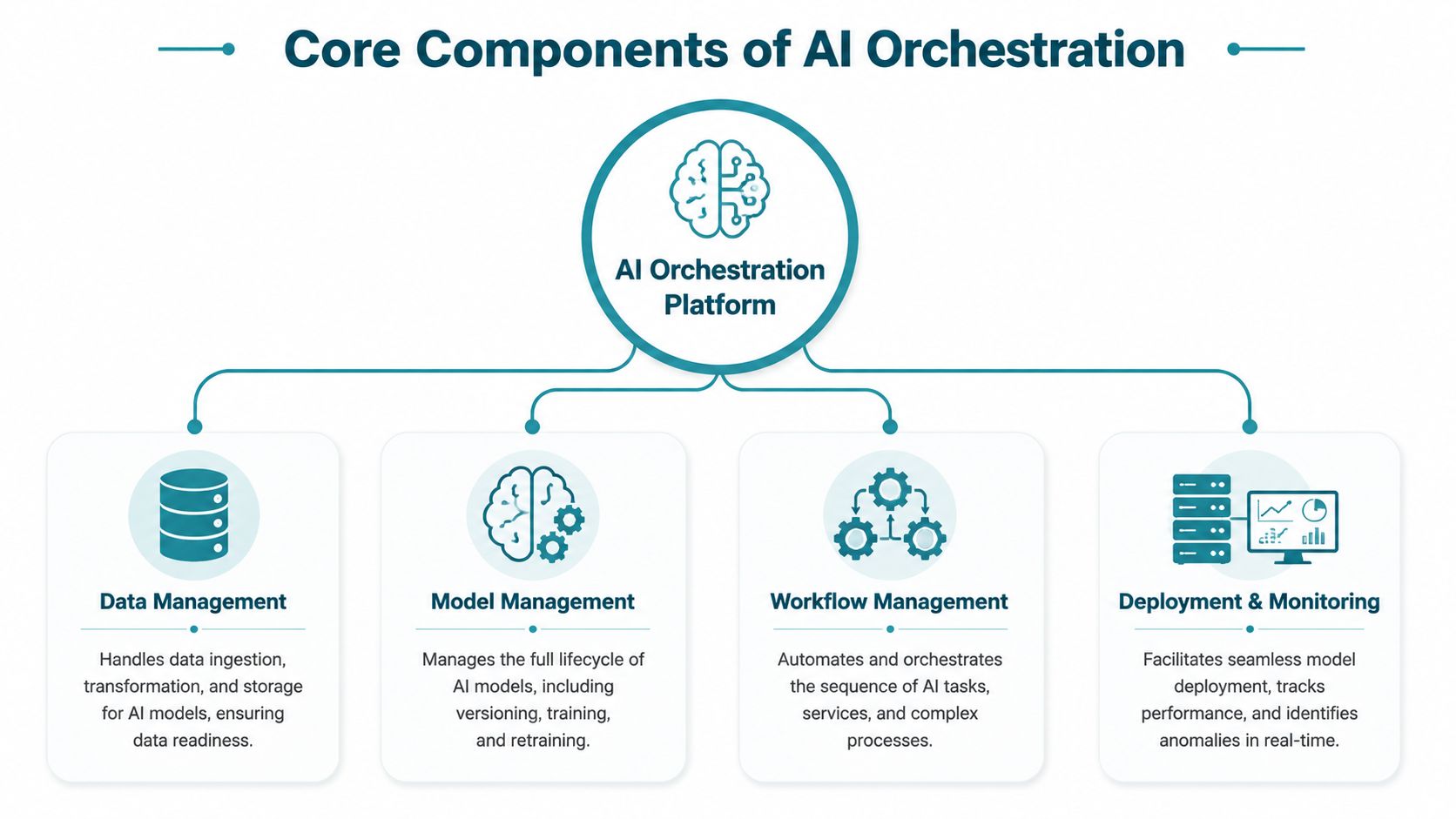
Data management
If the data layer is weak, the rest of the stack becomes expensive guesswork.
This part of the platform handles ingestion, transformation, access, and storage. For a business leader, that translates into one question. Can the AI system consistently reach the right data in the right format at the right moment?
When this layer is done poorly, teams see the same symptoms over and over:
- Stale outputs: The model answers from old information.
- Inconsistent responses: Different channels use different source data.
- Manual cleanup: Staff spend time fixing data before AI can use it.
- Security friction: Access controls are bolted on after deployment.
When it's done well, the AI workflow gets cleaner because the system doesn't need to compensate for broken inputs.
Model management
A model registry or lifecycle layer sounds technical, but the business value is plain. It gives you version control, rollback options, and a source of truth for what model is live, where it's used, and whether it should still be trusted.
That matters when teams want to test a better model, fine-tune a domain-specific one, or replace an expensive provider. Without a management layer, every change becomes risky because nobody knows what else might break.
A solid model management capability should support these decisions:
| Capability | Why it matters to the business |
|---|---|
| Version tracking | You can explain which model produced which output |
| Controlled deployment | Teams can test changes without destabilizing operations |
| Retraining governance | Updates happen on purpose, not by accident |
| Replacement flexibility | You aren't locked into one model path |
Workflow management
This is the coordination brain. It decides sequence, routing, dependencies, retries, and escalation.
For example, a workflow might retrieve data, classify the request, run generation, apply business rules, and then either send the result automatically or route it for human review. The workflow engine is where that logic lives.
One useful way to think about it is that the workflow layer answers four operational questions:
- What happens first
- What depends on prior output
- What happens when something fails
- Who gets involved if confidence is low
A lot of teams try to hold this logic inside prompts. That usually works for demos and fails in production.
Deployment and monitoring
A system isn't production-ready because it works once. It's production-ready when you can deploy it safely, observe it continuously, and respond before users or regulators find the problem first.
This layer covers serving, uptime, anomaly detection, task tracking, and operational visibility. It's where leaders get answers to practical questions like whether latency is rising, whether a handoff is failing, or whether one step in the workflow is creating downstream errors.
If your team can't see where an AI workflow slows down or breaks, it can't manage the economics of that workflow.
That's also why many companies pair platform work with operating support from internal ML teams, cloud providers, system integrators, or consulting partners. Firms such as AmasaTech's work on agentic AI workflows focus on this layer from an outcomes perspective, tying orchestration decisions to metrics like throughput, cost, and accuracy rather than treating the platform as a standalone technical purchase.
Common Architecture Patterns for Scalable AI Systems
Architecture choices are where AI ambition usually meets operating reality.
Leaders often hear “multi-agent” and assume more sophistication automatically means more value. It doesn't. The right pattern depends on the shape of the work, the tolerance for latency, and how costly failure becomes once the system starts taking action.
Microsoft's guidance on AI agent design patterns makes the tradeoff clear. Sequential orchestration fits workflows with clear stage dependencies. Multi-agent orchestration is better for parallel problem-solving across specialties, but it adds coordination overhead. Microsoft also stresses instrumentation, performance tracking, integration tests, and rubric-based evaluation because outputs are non-deterministic.
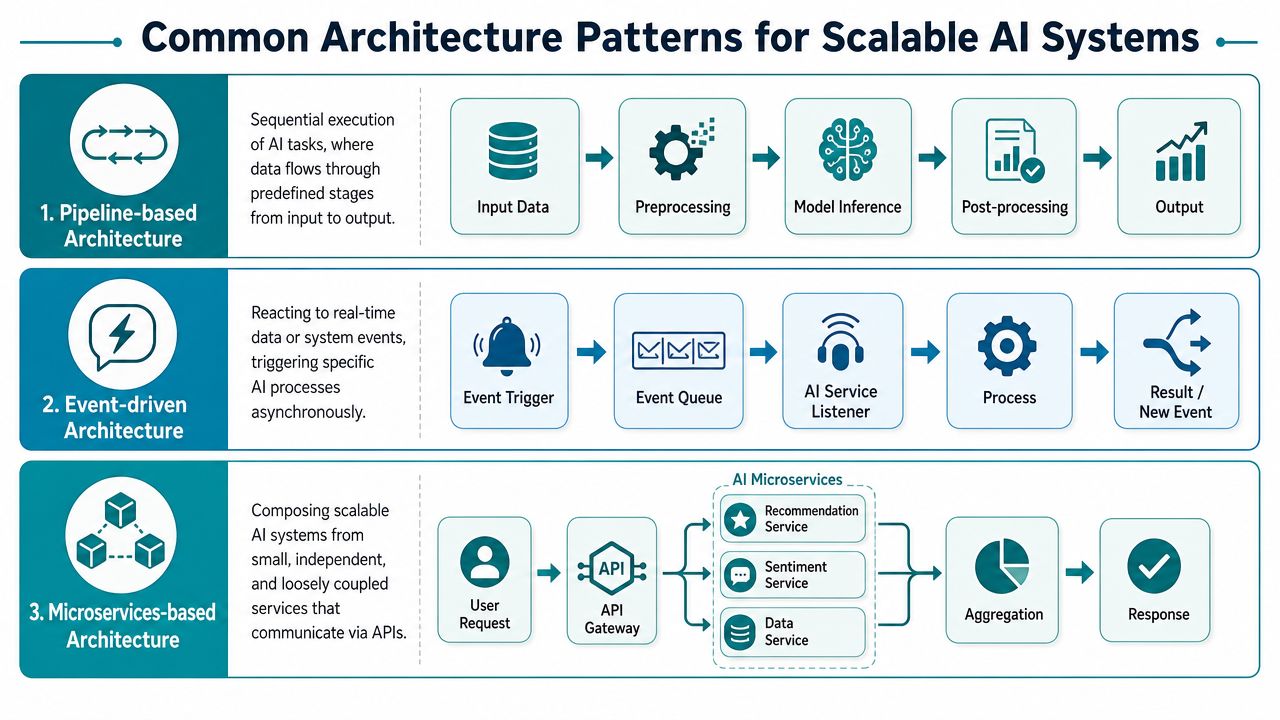
Sequential orchestration
This is the simplest pattern to understand and often the best place to start. One step feeds the next. Think intake, classification, retrieval, draft generation, review, then final action.
It works well when the process itself is naturally ordered. Document processing, claims triage, support summarization, and internal knowledge workflows often fit here.
Its strengths are practical:
- Clear dependencies: Each step has a defined predecessor.
- Easier debugging: Teams can inspect the chain more directly.
- Cleaner accountability: It's easier to locate where a bad result entered the flow.
Its weakness is just as clear. Early-stage failures propagate. If the retrieval step gets the wrong information, every downstream step inherits the problem.
Multi-agent orchestration
This pattern uses specialized agents that coordinate on a broader task. One agent may research, another may validate, another may summarize, and another may prepare an action or decision.
It's useful when the work spans multiple functions or requires different forms of expertise. Revenue operations, compliance-heavy review, product intelligence, and cross-system decision support often push in this direction.
But multi-agent systems introduce costs teams underestimate:
| Pattern | Best fit | Main benefit | Main drawback |
|---|---|---|---|
| Sequential | Ordered workflows with clear dependencies | Simplicity and traceability | Upstream failures cascade |
| Multi-agent | Complex tasks with parallel specializations | Greater flexibility across domains | More coordination overhead and new failure modes |
More agents means more handoffs. More handoffs means more places for latency, drift, and confusion to enter the system.
Event-driven and service-based designs
Not every orchestration pattern is a visible chain. In many production environments, work starts because an event occurs. A document arrives. A customer submits a form. A ticket changes status. A payment exception appears.
That pushes teams toward event-driven and microservices-based designs, where AI capabilities respond to triggers and communicate through APIs. This is often the more scalable operating model, especially when AI has to plug into existing product or operations infrastructure rather than sit inside a single app.
If your team is sorting through that question, this kind of API architecture guidance is usually where the practical design conversation begins. Not with “Which agent framework should we use?” but with “How will requests, outputs, and controls move across systems we already run?”
What works in production
Production-grade orchestration is less about clever routing than disciplined observation.
Teams that do this well instrument every handoff. They track task progress. They log failures. They test integrated workflows, not just isolated prompts. They evaluate outputs against rubrics because acceptable performance in AI systems often depends on ranges, not exact matches.
Teams that struggle usually make one of two mistakes. They either oversimplify a complex problem into one fragile sequence, or they overbuild a multi-agent design before they've proven the economics.
Measuring the Business Value of Orchestration
The business case for orchestration isn't “AI feels more advanced.” The business case is that it changes how work gets done, what that work costs, and how reliably the company can improve it.
A lot of writing on AI orchestration leans on productivity language. That misses the harder and more useful question. What are the operating economics of the workflow once AI is in it?
Coverage in UX Magazine frames this well in its discussion of AI agent orchestration platforms. The issue is the tradeoff between orchestration overhead and improvements in throughput, cost per task, and failure rate, while also accounting for latency, error propagation, and integration cost.
The KPIs that actually matter
If I'm advising a CEO or ops leader, I don't start with model benchmarks. I start with process metrics.
Look at measures like:
- Throughput: Are more cases, tickets, documents, or requests getting completed in the same operating window?
- Cost per task: Did the workflow become cheaper once you include model use, integration work, and exception handling?
- Failure rate: How often does the process break, escalate, or require rework?
- Time to resolution: When something goes wrong, how quickly can the team detect and fix it?
- Deployment frequency: How quickly can the company improve the workflow without destabilizing it?
Those metrics tell you whether orchestration is functioning as a business asset or just adding technical complexity.
Where value tends to show up first
The earliest value usually appears in three places.
First, handoff reduction. When AI systems move work between retrieval, reasoning, validation, and action in a defined way, teams spend less time stitching together tasks manually.
Second, change velocity. A modular orchestration layer makes it easier to replace one component without rebuilding the whole application.
Third, operational visibility. Once the workflow is instrumented, leaders can finally see where cost and delay live.
The point of orchestration isn't to add more AI. It's to make AI accountable to business performance.
When orchestration is worth it and when it isn't
There are cases where orchestration clearly makes sense. Regulated workflows. Cross-system decisions. Multi-step case handling. Internal operations with repeated handoffs and measurable service levels.
There are also cases where it's overkill. A single contained use case with one model, one data source, and low operational risk may not need a full orchestration layer yet.
Use this decision frame:
| Situation | Better choice |
|---|---|
| One model, limited workflow, low risk | Keep it simple |
| Multiple tools or models, frequent handoffs | Introduce orchestration |
| Compliance, approvals, or audit needs | Add orchestration with governance |
| High maintenance from brittle integrations | Re-architect around orchestration |
If your team is already trying to connect AI work to operational KPIs, a practical benchmark is whether you can monitor those KPIs consistently over time. This kind of AI transformation progress monitoring discipline usually separates serious programs from pilot theater.
Your Roadmap to Implementing AI Orchestration
Most companies shouldn't start with a platform decision. They should start with a workflow decision.
The core governance issue is often overlooked early. Deloitte points out that the important question for regulated enterprises isn't only whether agents can collaborate, but what control plane prevents autonomous workflows from violating policy, compliance, or cost limits. Its analysis of AI agent orchestration governance emphasizes guardrails, audits, and human approval loops.
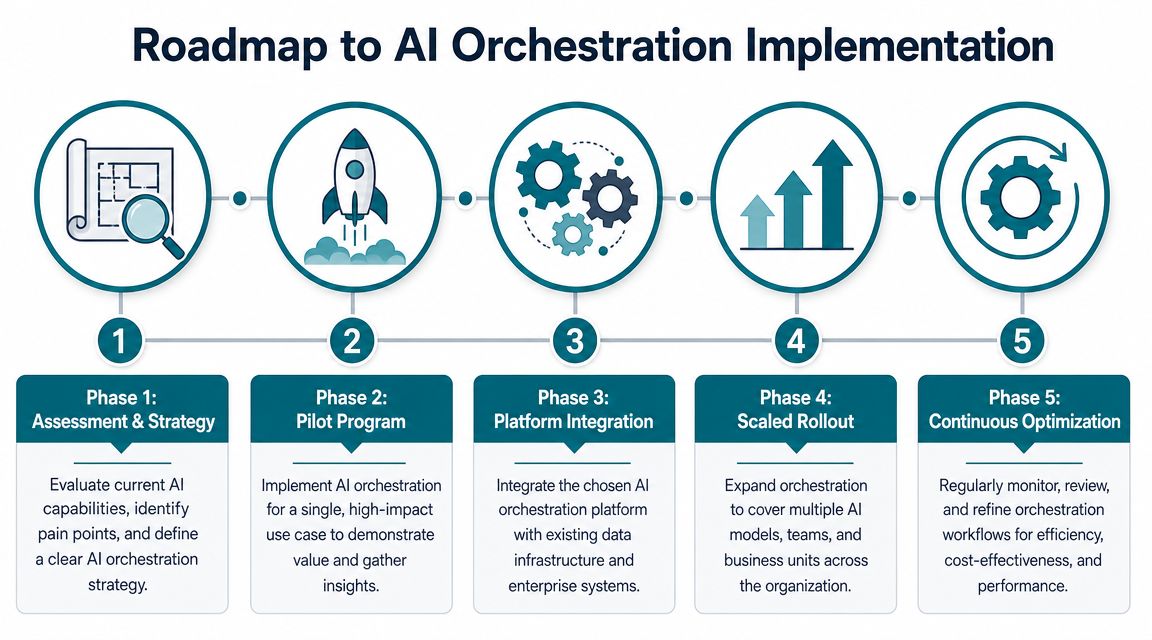
Phase one and two
Start with an audit, then choose one contained workflow.
Audit the current state. Which AI systems already exist. Which teams own them. Where are the handoffs. Where do failures disappear into email, chat, or spreadsheets. Where does latency frustrate customers or staff. Which use case already has a measurable pain point and enough data to improve?
Then run a pilot on one high-impact process. Internal knowledge retrieval, document intake, support triage, or compliance review are common starting points because they have visible inputs and repeatable outputs.
A good pilot has these properties:
- It solves a real business bottleneck
- It has clear process boundaries
- It can be measured against a known KPI
- It doesn't require full organizational redesign on day one
Phase three and four
After the pilot proves value, integrate the orchestration layer into adjacent systems and expand carefully.
That often means connecting data sources, identity controls, CRM or ERP workflows, approval logic, and observability tooling. The mistake here is trying to scale without standardizing ownership and policy first.
Then move into scaled rollout. But scale by workflow family, not by enthusiasm. If one orchestrated process works in support operations, don't immediately copy the design into underwriting, legal review, and finance ops without adapting for risk, data, and decision rights.
Phase five
Optimization is continuous because AI behavior, costs, and business requirements all move.
At this stage, strong teams review:
- Workflow performance
- Escalation patterns
- Model or tool replacement opportunities
- Guardrail effectiveness
- Human review burden
Some approvals can be removed over time. Others should stay permanent. That's a management decision, not a purely technical one.
Governance in ai orchestration should be designed before autonomy expands, not after an incident forces the issue.
A practical operating model
If you need a simple roadmap to align leadership, use this structure:
| Phase | Leadership focus |
|---|---|
| Assessment and strategy | Identify workflow pain and success criteria |
| Pilot program | Prove one measurable quick win |
| Platform integration | Connect orchestration to core systems and controls |
| Scaled rollout | Expand selectively with clear ownership |
| Continuous optimization | Refine cost, quality, and governance over time |
For teams planning that progression, a structured AI adoption roadmap can help frame sequencing. The important point is that orchestration should follow business priorities, not the other way around.
Conclusion Orchestrate Your AI-First Future
A single successful AI model can create momentum. It doesn't create maturity.
Maturity starts when the business can coordinate models, data, tools, approvals, and monitoring as one operating system. That's what ai orchestration gives you. It turns isolated capability into repeatable execution. It gives leaders a way to connect AI investment to real process outcomes instead of scattered experiments.
The strategic payoff is larger than technical neatness. Orchestration lets a company standardize how AI work gets routed, governed, measured, and improved. That's the bridge from “we have AI features” to “we run AI-enabled operations.”
The implementation path doesn't need to be dramatic. Start with one workflow that matters. Measure the economics accurately. Add visibility before complexity. Put guardrails in place before autonomy expands. Then scale what proves itself.
That's the shift serious operators make. They stop asking whether AI can produce an output. They start asking whether AI can reliably produce business results inside the way the company already works, or wants to work next.
For any leadership team building toward an AI-first operating model, that's the core role of orchestration. It's not a technical accessory. It's the control layer that makes intelligent systems usable, governable, and worth scaling.
If your team is moving from AI pilots to outcome-driven execution, AmasaTech works with organizations on AI audits, phased adoption strategy, workflow automation, custom AI agents, and KPI-tied delivery models that focus on measurable business results rather than standalone proofs of concept.