
AI Augmented Development: An Org-Wide Playbook
Your engineering team is already feeling it. A few developers are using GitHub Copilot or ChatGPT on the side. Product wants faster delivery. Security wants to know where prompts and code are going. Leadership keeps asking the same question: are we behind on AI, or are we about to create a governance mess by moving too fast?
That tension is normal. Most companies aren't deciding whether AI belongs in software delivery anymore. They're deciding how to make it useful, measurable, and safe across the whole lifecycle.
AI augmented development works when you treat it as an operating model, not a developer perk. The teams that get value don't start with a tool bake-off. They start by auditing readiness, choosing narrow pilot use cases, redesigning review and testing workflows, and putting governance in place before adoption outruns control.
Moving Beyond the Hype to a Real Strategy
The board-level pressure is real because the market signal is real. One industry analysis estimates the AI-augmented software engineering market was valued at USD 2.1 billion in 2023 and is projected to reach USD 26.8 billion by 2030, with a 37.5% compound annual growth rate from 2024 to 2030 according to Codewave's analysis of AI-augmented development trends.
That isn't a story about autocomplete. It's a story about software organizations rebuilding delivery around new assumptions. Teams are no longer asking whether AI can suggest code. They're asking where AI belongs in planning, implementation, testing, documentation, support tooling, and release operations.
The mistake I see most often is treating adoption as a procurement task. Buy a license, roll it out, wait for productivity. That rarely works. AI augmented development changes how engineers gather context, how reviewers evaluate changes, how QA validates behavior, and how leaders measure throughput. If those pieces stay untouched, the tool usually creates noise faster than it creates value.
Strategy starts with operating constraints
A workable strategy needs four things:
- A readiness view: Know where your codebase quality, documentation, security posture, and team habits will help or block adoption.
- A use case thesis: Pick a narrow set of engineering tasks where speed matters and verification is manageable.
- A workflow redesign: Update review, testing, and release controls so faster generation doesn't overwhelm downstream steps.
- A scaling model: Decide how standards, approvals, training, and measurement will spread beyond the first team.
A lot of leaders need a phased path, not a grand transformation plan. That's why a practical AI adoption roadmap for enterprise teams is more useful than another feature comparison between coding assistants.
Practical rule: If you can't explain how AI will change your review queue, test strategy, and release controls, you don't have a strategy yet. You have tool enthusiasm.
The right posture is calm and operational. Start with the current state. Fix the obvious bottlenecks. Prove value in a bounded environment. Then scale what survives contact with production.
Conducting Your AI Readiness Audit
Before introducing AI into engineering, audit the system it's entering. Organizations quickly discover that the limiting factor isn't model quality. It's fragmented documentation, inconsistent review standards, unclear ownership, and codebases that are hard to reason about even without AI.
Industry adoption makes this urgent. By 2026, around 90% of software development professionals are reported to use AI tools in daily work, and 65% say they are heavily reliant on them according to Azilen's review of AI-augmented development adoption. That makes readiness a management issue, not just an engineering experiment.
A strong audit looks at three dimensions first: people, process, and platforms. If you want a more structured worksheet, a practical AI readiness checklist for operational teams is a useful starting point.
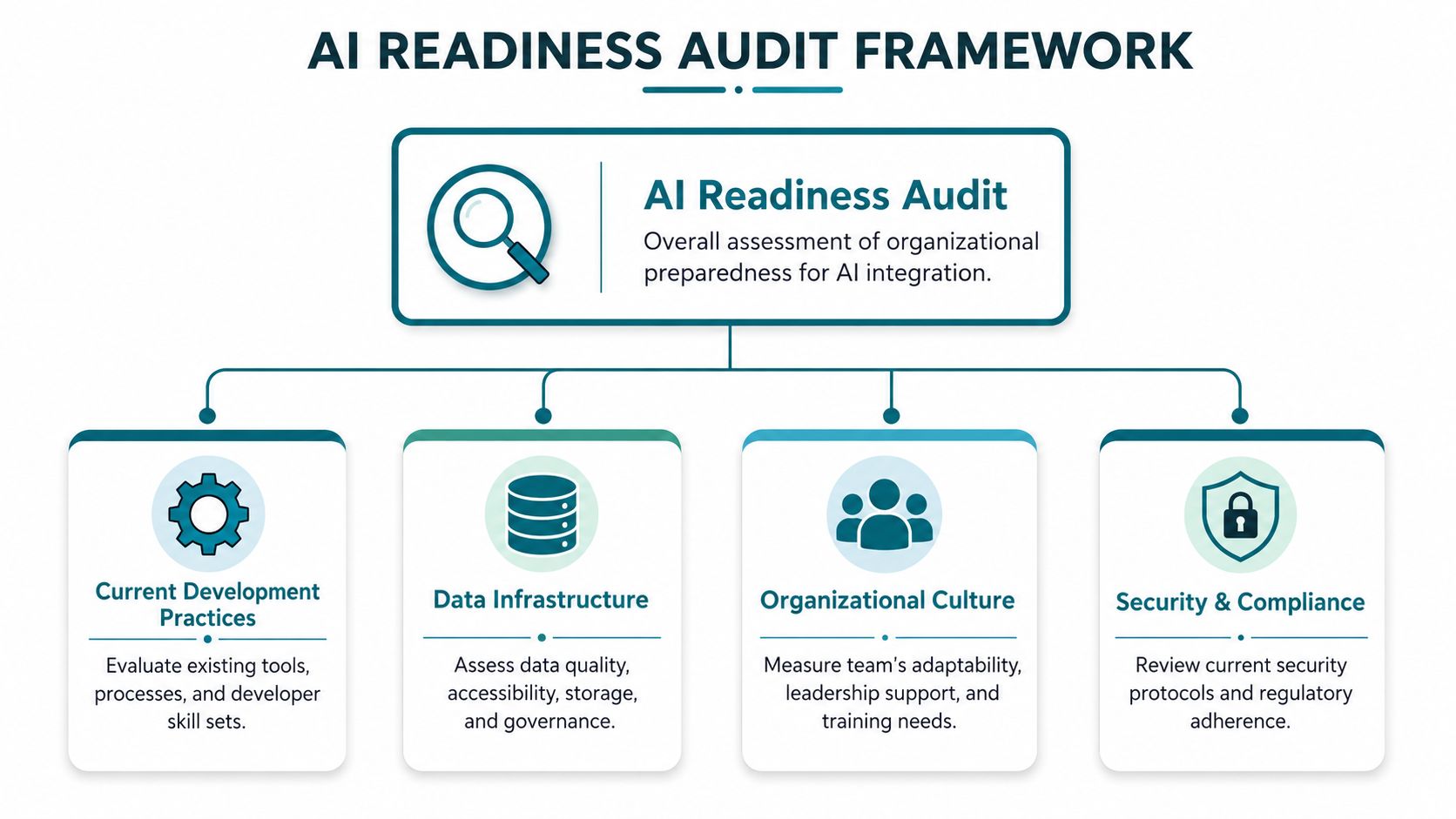
People and team behavior
Start with how engineers work, not how managers think they work.
Ask questions like:
- Who already uses AI tools: Shadow adoption matters because habits are already forming, with or without policy.
- Which engineers validate rigorously: Seniority alone doesn't predict good AI usage. Some engineers review generated code carefully. Others accept plausible output too quickly.
- Where skill gaps sit: Teams may need training in prompt design, secure usage, model limitations, or test-first validation.
You're looking for role-based readiness. A backend team maintaining regulated workflows needs different guardrails than a frontend team generating UI scaffolding.
Process and SDLC friction
Map your delivery flow from ticket creation to deployment. Don't ask where AI could fit in theory. Ask where work stalls today.
Common patterns show up fast:
- Specification ambiguity: Engineers lose time clarifying requirements, so AI generated output just amplifies confusion.
- Boilerplate-heavy implementation: Repetitive service code, test scaffolding, and documentation tend to be easier to augment.
- Review bottlenecks: Pull requests wait because reviewers must reconstruct context from scratch.
- Test debt: Teams can generate code faster than they can validate it.
Teams usually overestimate coding as the bottleneck and underestimate handoffs, review latency, and weak test coverage.
That's why the audit should follow work, not just tools.
Platforms and internal context quality
For AI to produce useful engineering output, your internal context has to be usable. That means code, docs, standards, tickets, and architecture records need to be reasonably current and accessible.
Review these areas:
- Codebase health: Is the system modular enough for targeted generation and review?
- Documentation quality: Can an engineer or model find current API behavior, domain rules, and architecture decisions?
- Knowledge access: Are runbooks, design docs, and repository conventions searchable?
- Security boundaries: Do you know what code or data can be shared with external models?
A readiness audit should end with a ranked opportunity list. Not a giant backlog. Just a small set of promising use cases, a list of blockers, and clear ownership for fixing them.
Selecting a Pilot Project for a Quick Win
The best first pilot is boring in the right way. It has visible business value, low blast radius, and a straightforward path to measurement. It does not need to be the most advanced use of AI in the company.
That matters because AI isn't uniformly helpful. A rigorous benchmark from METR found that for experienced developers working on familiar codebases, AI tools increased completion time by 19%, as summarized in AgileEngine's evidence-based guide to AI-assisted software development. That should reset how you choose pilots. Don't start where your strongest engineers already move quickly from memory.
What makes a pilot strong
Good pilot candidates usually share a few traits:
- Unfamiliar or broad context: Internal APIs, cross-team systems, or domains where engineers spend time retrieving background.
- Boilerplate-heavy work: Repeated patterns in test generation, schema mapping, DTO creation, or documentation updates.
- Clear output boundaries: The team can easily review whether the result is correct.
- Simple measurement: You can compare cycle time, review latency, rework, or defect escape before and after.
Weak pilots are easy to recognize too. Don't start with high-risk production refactors, subtle bug hunts in legacy systems, or architecture work where the main challenge is judgment rather than generation.
A practical selection lens
Use this matrix when shortlisting candidates:
| Pilot Project Idea | Potential Impact | Measurement Difficulty | Implementation Risk |
|---|---|---|---|
| Generate unit tests for a stable internal service | High | Low | Low |
| Draft API documentation from existing code and specs | Medium | Low | Low |
| Build an internal support bot over engineering docs with RAG | High | Medium | Medium |
| Use AI for legacy core-module bug fixing | Medium | High | High |
| Generate frontend component scaffolds from design patterns | Medium | Medium | Low |
| Apply AI to broad architecture redesign decisions | High | High | High |
A quick win usually sits in the upper-left of that table. Measurable, useful, reviewable.
Good pilot examples and bad ones
A sensible pilot might be test generation for a well-defined service with stable interfaces. Engineers can compare coverage quality qualitatively, review output quickly, and see whether it reduces repetitive work.
Another solid option is a retrieval-augmented internal engineering assistant over API docs, runbooks, and service ownership records. That doesn't write production code directly, but it reduces context retrieval time and often helps new team members faster than another static wiki cleanup project.
Poor first pilots tend to sound impressive in steering meetings:
- Full AI code review replacement: Review is where judgment and risk control live. Don't automate trust before you understand failure modes.
- Automatic fixes in a core legacy platform: Old systems carry hidden constraints. Generated changes can look clean and still break real workflows.
- AI-driven planning across the entire SDLC: That's too broad for a first pass and too hard to attribute cleanly.
Pick the pilot your skeptics can respect, not the pilot your enthusiasts want to demo.
The first implementation should teach the organization three things: where AI helps, where it slows people down, and what control points need to change before wider rollout.
Building Your AI Development Toolchain
A usable AI development stack has layers. If you only buy a coding assistant, you'll get fragmented experimentation. If you design a toolchain, you can connect generation, context retrieval, validation, and delivery into something the team can trust.

The three layers that matter
I usually break the stack into three practical categories.
Copilots for in-flow development
These are the tools engineers use while writing code in the IDE or chat interface. GitHub Copilot is the most obvious example. These tools are strongest when the work is local, repetitive, and easy to validate in the moment.
Use them for:
- Scaffolding routine code
- Drafting tests
- Explaining unfamiliar snippets
- Generating first-pass documentation
Don't expect them to replace system understanding. They reduce friction. They don't own design.
Specialized generators for narrow engineering tasks
Some tasks deserve purpose-built workflows rather than generic prompting. Teams often need reliable generation around migrations, frontend components, structured test cases, or code transformations that follow known internal patterns.
This layer matters because repeatable tasks benefit from tighter templates, stricter input formats, and narrower output expectations. Generic chat works until consistency matters.
Examples include:
- Migration and schema helpers
- Design-to-component generators
- Test generation workflows
- Static analysis and remediation assistants
RAG systems for internal context
Retrieval-augmented generation is where many organizations gain their first major advantage. The model stops guessing from public training data and starts answering with internal sources such as architecture docs, APIs, service ownership records, coding standards, and runbooks.
That changes the interaction from “write me some code” to “work with our actual environment.”
A plain LLM gives you fluency. A RAG-backed engineering assistant gives you context.
How the pieces fit together
A healthy toolchain routes work to the right layer.
- Start in the copilot when an engineer is implementing a routine change.
- Move to a specialized generator when the task follows a repeatable internal pattern.
- Pull from RAG when correctness depends on company-specific knowledge.
This is also where architecture discipline matters. Your repositories, documentation systems, identity model, and APIs need to support controlled context flow. A strong API architecture approach for AI-enabled systems helps because these systems often fail at boundaries, not inside the model itself.
One practical note on vendors. Teams usually combine commercial tools and internal services. GitHub Copilot may cover IDE assistance. An internal RAG service may sit on top of documentation and code search. AmasaTech is one example of a provider that works on AI audits, RAG pipelines, and custom AI deployment as part of broader operational rollout. That kind of support is relevant when the problem is organizational integration, not just model access.
The toolchain should reflect how your engineers already work. If it forces them to leave core systems, copy context manually, or guess which tool is approved, adoption becomes messy fast.
Integrating AI into Your Engineering Workflows
Tool rollout is the easy part. Workflow redesign is where adoption succeeds or fails.
The core management question is simple: which parts of the SDLC should stay human, and when does AI create new operational risk? That framing matters because AI can increase throughput while also widening the blast radius of mistakes if review, testing, and deployment controls stay unchanged, as noted in Splunk's discussion of AI-augmented software engineering risks and oversight.
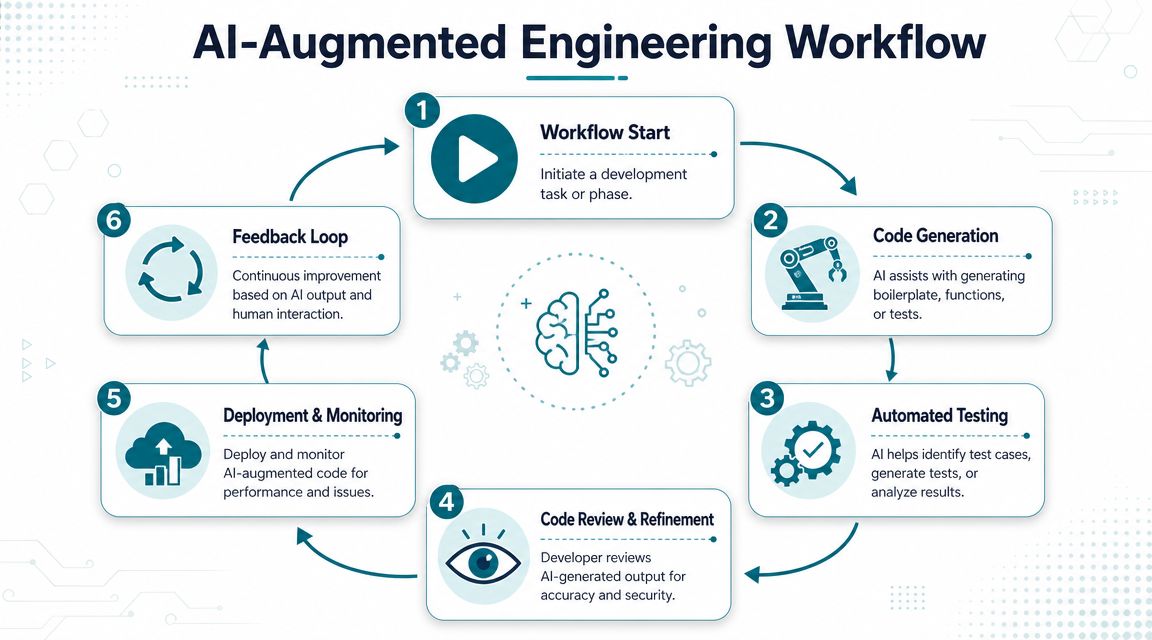
Keep humans where judgment matters most
In practice, humans should stay firmly in control of a few points:
- Requirement interpretation: AI can help draft, summarize, or clarify. Product intent still needs human ownership.
- Architecture choices: Trade-offs across scalability, security, cost, and maintainability need experienced judgment.
- Final review of risky changes: Authentication flows, payments, permissions, regulated logic, and data handling shouldn't move on generated confidence alone.
- Production release authority: Deployment decisions need context beyond code.
What changes is the reviewer's job. Reviewers spend less time correcting syntax and more time validating behavior, assumptions, edge cases, and security implications.
Redesign review and testing around generated speed
If developers can generate changes faster, the old review process starts to lag. That creates a dangerous gap. More code enters the queue. Review quality drops. Defects move downstream.
A safer workflow usually includes:
- Declare AI assistance in the pull request. Reviewers need to know whether a change includes generated code, generated tests, or generated docs.
- Require rationale, not just diff size. The author should explain what the code is supposed to do and what was manually validated.
- Strengthen automated checks. Linting, static analysis, policy checks, test execution, and dependency scanning need to catch more before human review.
- Change review prompts. Reviewers should check logic, unsafe assumptions, and data handling before style issues.
- Tighten post-deploy observation. Watch new changes more closely when generation speed rises.
A useful AI workflow productivity model for delivery teams treats AI as part of the workflow, not a side assistant.
Measure outcomes that reflect real delivery
A lot of AI reporting is still too shallow. “How many prompts did we run?” doesn't tell a leadership team much.
Track operational outcomes instead:
- Pull request cycle time
- Review latency
- Change failure rate
- Incident resolution time
- Rework after merge
- Developer time spent gathering context
Don't reward raw output. Reward verified throughput.
That distinction matters because generated code can front-load speed and back-load correction. If leaders only watch visible coding velocity, they can miss the extra burden pushed into QA, review, and operations.
Establishing Governance and Scaling Responsibly
The hard part begins after the first pilot works. Success creates demand. More teams want access. More code gets generated. More documents are indexed. More prompts touch internal knowledge. Without governance, adoption outpaces control almost immediately.
Independent guidance from the U.S. SEI makes the key point clearly. AI-augmented software engineering requires traceable evidence for assurance. The primary bottleneck is not code generation, but auditability and proof of correctness, according to SEI's guidance on AI-augmented software engineering.

Put policy around model usage and code handling
Governance starts with clear rules that engineers can follow.
Write down:
- What can be shared with external models: Source code, tickets, logs, customer data, secrets, and regulated content need explicit boundaries.
- Which tools are approved: If you leave this vague, shadow usage fills the gap.
- What must be logged: Prompt history, model version, source context, and approval trail may all matter depending on your risk level.
- Which outputs need extra scrutiny: Security-sensitive code, infrastructure changes, and compliance-related logic usually need stronger review paths.
This doesn't need to become bureaucracy for its own sake. It needs to create consistent decisions under delivery pressure.
Build a verification stack, not just an access model
Most organizations spend too much time on access and too little on evidence. They approve a tool, connect SSO, and think governance is done.
It isn't. You also need a verification stack:
- Automated testing gates that run before review and before release
- Static analysis and policy checks for generated changes
- Dependency and license scanning for introduced packages or snippets
- Traceability records that show how a change was produced and validated
- Knowledge source controls for any RAG system feeding engineers or agents
Governance is what lets you scale adoption without scaling uncertainty.
Scale through standards and operating ownership
Once two or three teams are using AI in production, informal coordination stops working. At that point, create a lightweight operating model.
That usually includes:
- A small center of excellence or working group: Engineering, security, platform, and product should all be represented.
- Standard playbooks: Prompt patterns, review expectations, approved use cases, and exception handling.
- Training by role: Developers, reviewers, engineering managers, and security leads don't need the same guidance.
- Ongoing measurement: Track where teams gain throughput and where risk or rework starts creeping in.
For leadership, the main job is keeping the program evidence-based. A practical AI transformation progress monitoring approach helps teams avoid two common failures: scaling because enthusiasm is high, or freezing because one failed pilot created distrust.
AI augmented development becomes durable when it stops being novel. It becomes part of how work is scoped, executed, reviewed, and governed. That's the point where it starts compounding.
If you're trying to turn scattered AI usage into a controlled engineering capability, AmasaTech helps organizations assess readiness, define measurable pilots, build RAG and workflow integrations, and operationalize governance around real business outcomes.