
How Legal Teams Use AI for Document Management
A lot of legal teams are in the same place right now. The documents keep multiplying, but headcount doesn't. One urgent deal, one investigation, or one compliance review can dump thousands of files into a system that was built to store documents, not interrogate them.
That's where the conversation around AI gets practical. Legal leaders aren't asking whether AI can summarize a contract anymore. They're asking whether it can help them find the right clause faster, reduce review drag, improve consistency, and lower risk without creating a governance mess somewhere else.
The most useful way to understand how legal teams use AI for document management is to look past feature lists. The hard part isn't buying a tool that can classify or extract. The hard part is deploying it in a way that changes real workflow outcomes and still stands up to scrutiny when privilege, confidentiality, and defensibility matter.
The End of the Document Deluge
A familiar scene plays out late in the evening. A legal team is chasing a due diligence deadline, inboxes are filling with redlines, outside counsel has asked for another batch of supporting documents, and nobody is fully confident that the latest version is the version being reviewed.

In that environment, traditional document management breaks down. Search depends on naming conventions. Knowledge sits inside individual lawyers' heads. Review teams spend too much time locating language that should be instantly available. What should be a legal repository behaves more like cold storage.
That's why the market is shifting from passive document management to AI-assisted review and knowledge extraction. As Harvey's overview of AI in legal document management notes, tasks that once took hours, such as finding relevant clauses, can now take minutes. That change matters because the value of a document system isn't in preserving files. It's in helping lawyers act on what those files contain.
From archive to working intelligence
Legal teams routinely manage large volumes of agreements, discovery materials, compliance records, and matter files. AI changes the operating model by reading across those sets for key clauses, inconsistencies, missing provisions, and other relevant language. Instead of asking, “Where is the document?” teams can ask, “What does our portfolio say about assignment rights, liability caps, or renewal terms?”
That's the fundamental upgrade behind tools like document intelligence systems. They turn scattered files into usable legal memory.
Legal teams don't need another folder structure. They need a faster path from document storage to decision support.
What legal leaders actually care about
In practice, the buying criteria are simple:
- Speed: Can the team retrieve and review the right material before a deadline slips?
- Accuracy: Can the system surface the right clause or inconsistency without creating more cleanup work?
- Risk control: Can the team spot missing language, outdated terms, or compliance issues before the document moves forward?
When AI works well in legal document management, it doesn't replace legal judgment. It removes wasted motion around retrieval, triage, and first-pass analysis so lawyers can spend their time on negotiation, escalation, and strategy.
How AI Learns to Read Legal Documents
Most non-technical leaders don't need a deep model architecture briefing. They need a clear mental model. The simplest one is this: AI for legal document management behaves like a very fast junior associate or paralegal that has been trained to recognize document types, pull out important terms, and flag what deserves human attention.
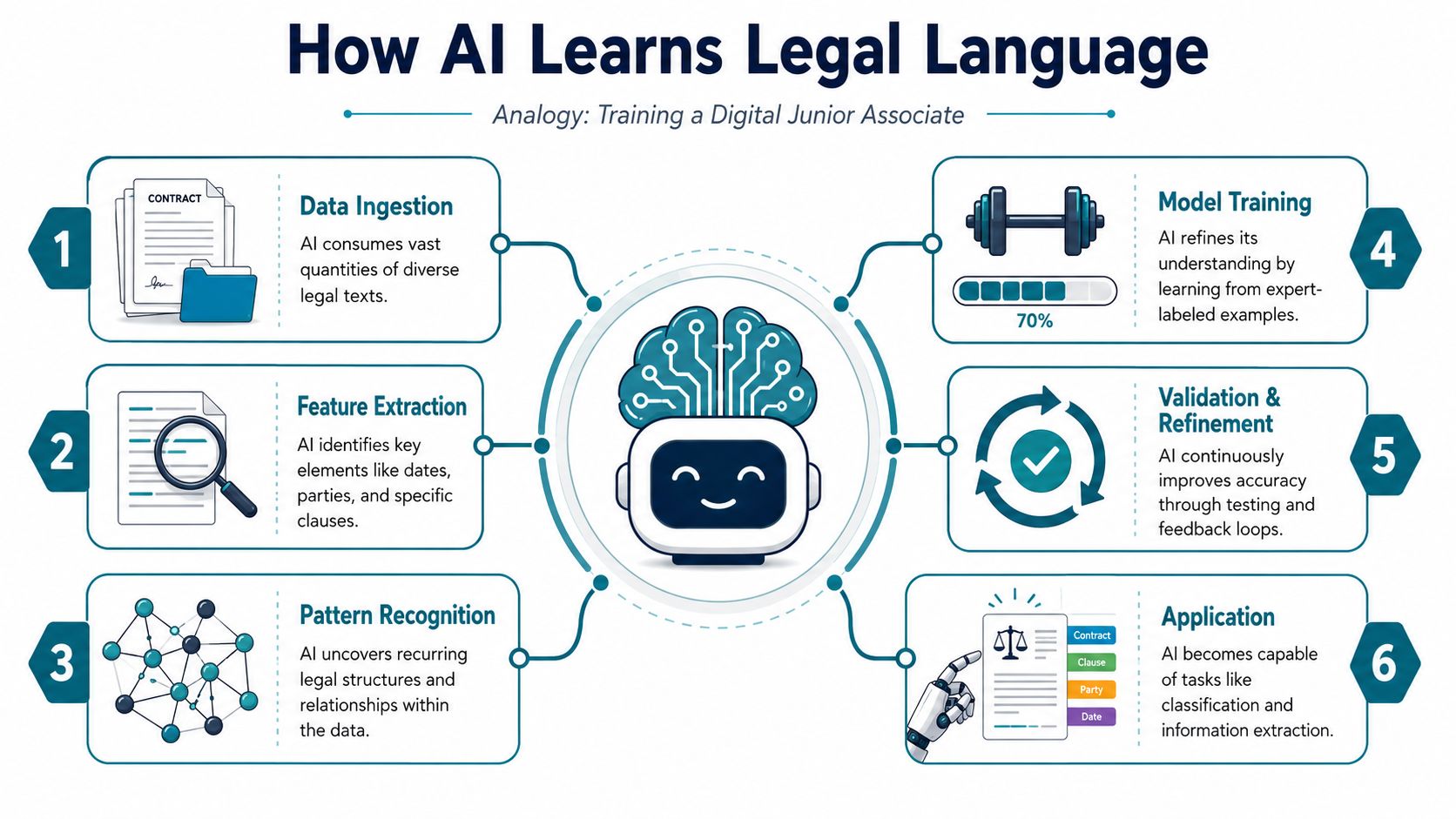
That training starts with ingestion. Paper files, scans, PDFs, Word documents, and email attachments have to be converted into machine-readable text. This is where OCR and text extraction matter. If the system can't reliably read the input, everything downstream gets weaker.
For teams dealing with mixed file quality, text detection workflows are often the unglamorous but essential first step. Clean text is what makes useful classification and extraction possible.
The three jobs AI handles first
Once documents are readable, AI usually takes on three foundational tasks.
Classification
The system learns to distinguish an NDA from an MSA, a lease from a policy, or a pleading from a supporting exhibit. Good classification matters because routing, retention, review rules, and search relevance all depend on it.Extraction
After classification, the model pulls out structured fields and legal concepts. That can include dates, parties, governing law, renewal language, limitation of liability clauses, notice periods, or confidentiality terms.Summarization and comparison
AI can generate a first-pass summary and compare one version against another to highlight material changes, missing provisions, or inconsistencies that deserve review.
Why the gains are real
Legal teams use Natural Language Processing to automate metadata and clause extraction, reducing document review time by approximately 70% compared to manual processes, and some firms using these capabilities report 99.9% accuracy in clause extraction. That benchmark appears in the verified data provided for this article.
What matters operationally is the cause behind those results. The model isn't “thinking like a lawyer” in the human sense. It's identifying patterns in unstructured text at a scale no human team can match consistently. It can scan for liability caps, termination dates, or compliance obligations across large libraries without getting tired or missing the eighty-third near-duplicate agreement.
Practical rule: Don't treat the first model output as a final legal answer. Treat it as a structured first pass that narrows what qualified reviewers need to inspect.
Where teams get tripped up
The biggest implementation mistake is assuming general-purpose AI can be dropped into messy legal content and perform well immediately. It usually can't. Problems appear when:
- Files are inconsistent: Bad scans, odd naming, and duplicate versions confuse the pipeline.
- Taxonomies are vague: If the team doesn't define document types and target fields clearly, extraction quality suffers.
- Review rules are missing: Lawyers need to know which outputs can be trusted for triage and which require line-by-line validation.
AI reads legal documents well when the workflow around it is disciplined. The technology matters, but so do the labels, review loops, and exception handling.
Key AI Use Cases Driving Legal Efficiency
The most effective deployments focus on a narrow set of high-friction workflows first. Legal teams don't get the best results by turning on every AI feature at once. They get results by targeting places where document volume is high, review logic is repetitive, and delays create downstream cost.
Contract review and portfolio analysis
Many teams initiate their use of AI by having it review large sets of agreements to identify missing clauses, outlier language, non-standard terms, or obligations that need follow-up. That helps in remediation projects, post-acquisition reviews, vendor paper analysis, and renewal planning.
The business benefit is straightforward. Lawyers stop spending hours finding where key language appears and start deciding whether that language is acceptable.
Search that behaves like legal research
Traditional search only works when users know the right keywords, naming conventions, or folder path. AI-supported retrieval is more useful because lawyers can ask natural-language questions against internal repositories and get grounded answers tied to the underlying documents.
That's where Retrieval-Augmented Generation, or RAG, has changed the workflow. Verified benchmark data shows that RAG pipelines can accelerate legal research by 3 to 5 times and reduce administrative effort by over 40% by combining large language models with retrieval from secure enterprise databases. That same pattern is what makes first-pass briefs, deposition summaries, and matter research more workable inside familiar environments.
A practical example of this operating model appears in this AI-powered contract review automation project, where retrieval and review logic are applied to contract analysis rather than generic chat.
Redaction, routing, and compliance support
Not every valuable use case is glamorous. Some of the best returns come from controlling repetitive document handling.
Consider where AI helps most:
- Sensitive data redaction: The system identifies and prepares content for review when privileged, confidential, or regulated information needs to be handled carefully.
- Workflow routing: Documents can be directed based on content, not just file name or sender.
- Compliance checks: AI can flag missing provisions, inconsistent language, or terms that may create policy conflicts before a document advances.
Better legal document AI doesn't just answer questions. It reduces the amount of administrative work wrapped around those questions.
What works and what doesn't
A quick comparison makes the pattern clear:
| Approach | What usually works | What usually fails |
|---|---|---|
| Contract analytics | Standardized clause libraries, defined exception rules | Throwing mixed templates into a model with no labeling discipline |
| AI search | Retrieval grounded in internal sources | Open-ended chat with no source boundaries |
| Redaction | Human-reviewed first pass for sensitive content | Fully automated release with no legal check |
| Workflow automation | Routing based on known document classes | Trying to automate edge cases before core cases are stable |
The lesson is simple. Use AI where repeatability is high and decision thresholds are clear. Keep human review where legal judgment, privilege, or material risk is involved.
Real World Wins with AI in Legal Document Management
The strongest proof points come from workflows legal teams already recognize. Not abstract demos. Actual tasks that consume time every week.
Research that stops being a bottleneck
One published case study on AI in legal document management reported a 4x faster legal research workflow, up to an 85% accuracy improvement using page-level citation, and a 70% improvement in compliance and risk management, according to this case study on legal AI outcomes.
Those numbers are useful because they reflect the three outcomes legal teams care about most. Faster retrieval. Better precision. Stronger risk control.
In practice, that means a lawyer isn't manually opening file after file to confirm whether a clause appears somewhere in a document set. The system narrows the field, points to the relevant pages, and makes verification faster.
Due diligence and clause hunting
A common failure mode in due diligence is not that lawyers miss the legal issue entirely. It's that the team spends too much time locating the right language across too many versions. AI changes that by surfacing clause patterns, discrepancies, and missing provisions across a document library in one pass.
That doesn't eliminate attorney review. It makes attorney review more selective and more defensible. Lawyers can spend their time on the exceptions that matter instead of re-reading standard boilerplate at scale.
Compliance review before documents move forward
Another practical win comes from pre-approval review. AI-assisted checks can identify missing language or compliance risks before a contract reaches the final stage of a workflow. That matters because late-stage legal fixes create drag for procurement, sales, finance, and the business owner waiting for approval.
A useful way to think about AI in this context is as an early warning layer. It catches the routine issues quickly and consistently, then hands the harder calls to the legal team.
The best legal AI deployments don't remove lawyers from the loop. They remove low-value repetition from the lawyer's day.
When teams implement document AI well, the before-and-after shift is visible. The repository becomes easier to search, research stops stalling on manual retrieval, and compliance review moves earlier in the process instead of showing up as rework at the end.
Your Implementation Roadmap From Strategy to ROI
Most legal AI projects don't fail because the model can't classify a contract. They fail because nobody defined what success should look like in workflow terms. A fast demo isn't the same as a useful deployment.
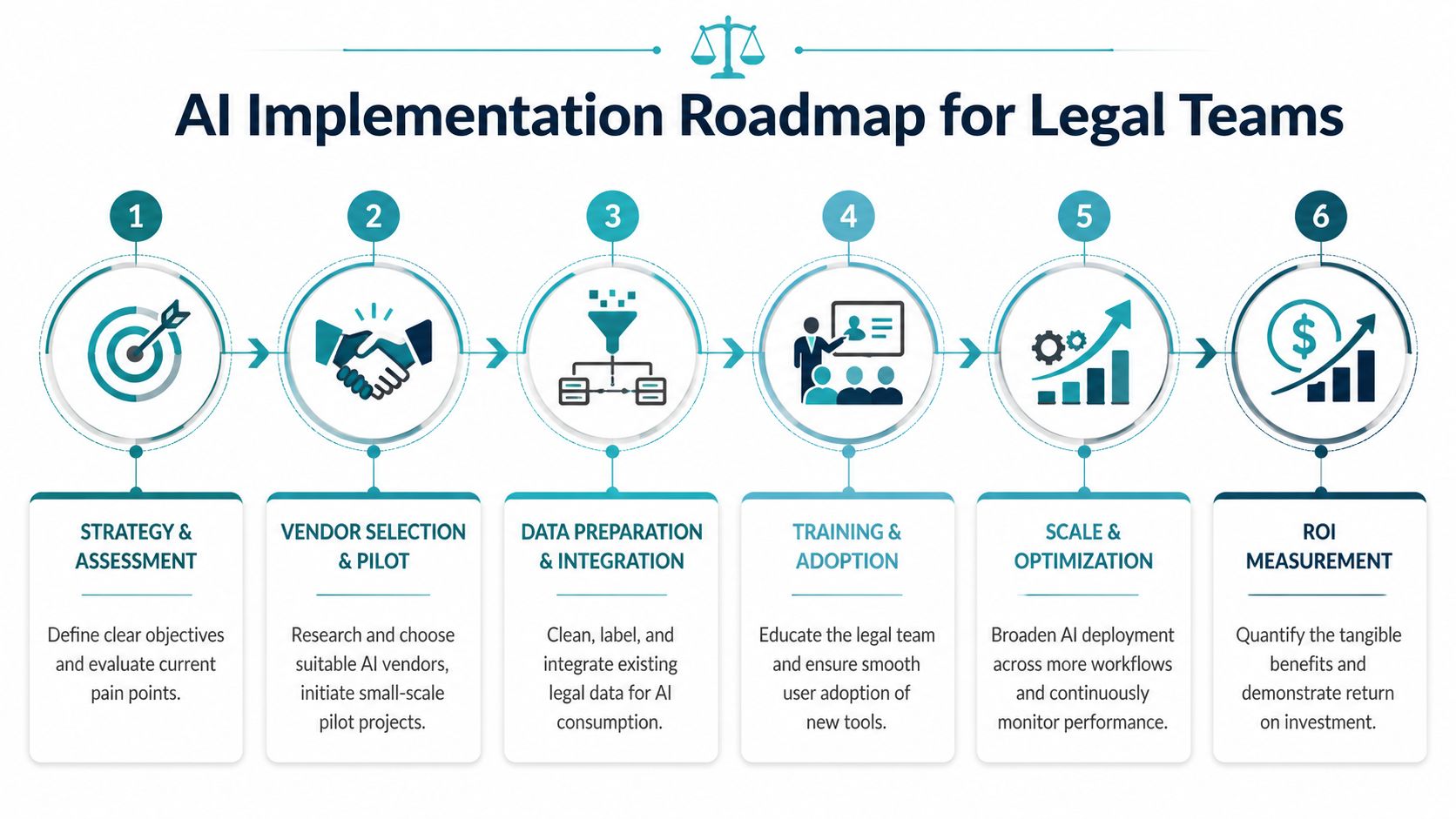
The critical gap, as Thomson Reuters notes in its legal operations discussion, is KPI selection. Vendors sell productivity. Legal leaders still have to prove whether AI changes downstream bottlenecks like approval delays, rework, or handoff friction across the document lifecycle.
Start with one painful workflow
Don't begin with “document management” as a broad category. Start with a concrete use case that has visible friction.
Good pilot candidates usually have these traits:
- High volume: The team handles the task repeatedly.
- Repeatable logic: Reviewers look for the same fields, clauses, or exceptions.
- Measurable delay: The workflow already creates waiting time for the business.
- Contained risk: The first deployment doesn't depend on fully autonomous legal judgment.
Examples include intake triage, first-pass contract classification, clause extraction for a defined agreement type, or repository search for recurring internal requests.
A practical planning reference is an AI adoption roadmap for operational teams, especially for sequencing pilots before broader rollout.
Define the right KPIs before you buy
If you only track whether users “like” the tool, you won't know whether it changed the process. The more useful KPI set covers both task efficiency and downstream impact.
| KPI | What it tells you | Why it matters |
|---|---|---|
| Review cycle time | How long a document takes to move through review | Shows whether AI removes waiting and manual lookup time |
| Error or exception rate | How often outputs need correction | Reveals whether speed is creating more rework |
| Matter throughput | How much work the team can handle with current resources | Connects AI to legal capacity |
| Search success | Whether users find the right document or clause quickly | Tests repository usefulness, not just model quality |
| Review quality | Whether important issues are flagged consistently | Protects against false confidence |
Build around validation, not blind automation
A durable rollout usually follows a phased structure:
Audit the data estate
Look at source systems, file quality, duplicates, labeling gaps, and permission structures. If the corpus is chaotic, the pilot should include cleanup.Choose narrow outputs
Don't ask the model to do everything. Ask it to classify a document type, extract specific fields, or retrieve grounded answers from an approved repository.Create a human review loop
Define what can be auto-routed, what needs legal validation, and what must trigger escalation.Instrument the workflow
Capture time-to-complete, reviewer overrides, search outcomes, and rework rates from the start.Scale only after the process improves
If users still copy results into spreadsheets or manually re-check everything, the AI hasn't changed the system enough to justify expansion.
A legal AI pilot earns the next budget only when it reduces total effort, not when it produces impressive screenshots.
What successful teams do differently
They treat implementation as an operations project, not a software install. They involve legal ops, IT, records, and security early. They define where the model is allowed to act. And they insist on evidence that the workflow got better, not just faster at one isolated step.
That's the difference between experimentation and ROI.
Navigating Compliance Pitfalls and Ethical Risks
Legal teams are right to be cautious. Document management touches privileged information, confidential negotiations, internal advice, regulated data, and evidentiary records. If AI introduces uncertainty into that environment without controls, the damage isn't theoretical.
A key concern is governance at scale. As Esquire Solutions reports in its discussion of AI adoption in corporate legal departments, 38% of corporate legal departments were already using AI daily and another 50% were considering it. The same source highlights why controls around version history, access, and model uncertainty are critical for preserving evidentiary quality and defensibility.
The real risks aren't all technical
Teams often prioritize addressing hallucinations initially. That matters, but it isn't the only risk. The more common problems are operational.
- Privilege leakage: Users paste sensitive content into tools without approved boundaries.
- Access drift: AI layers surface documents more efficiently than old systems, which makes permission design more important, not less.
- Version confusion: If summaries or extracted fields aren't tied clearly to source versions, people can act on stale information.
- Unclear accountability: Teams don't define who validates outputs or when escalation is required.
Governance that supports adoption
Overly rigid controls can kill usage. Loose controls create risk. The practical middle ground is a governance model that is specific, documented, and easy to follow.
A workable framework usually includes:
- Approved data boundaries: Define which repositories and document classes can be used by which models.
- Role-based access: Match AI access to existing matter and document permissions rather than creating a parallel shortcut.
- Auditability: Preserve logs of prompts, retrieval sources, output versions, and reviewer actions where appropriate.
- Human oversight: Require review for sensitive outputs, non-standard clauses, privileged material, and any result with low confidence.
- Escalation rules: If the model is uncertain or the issue is high impact, route it to a qualified reviewer.
If a legal team can't explain how an AI-generated summary was produced, what source it relied on, and who approved its use, it shouldn't be used in a sensitive workflow.
Defensibility comes from process discipline
The most defensible AI environments are usually the least theatrical. They don't promise autonomous legal reasoning. They focus on controlled retrieval, documented review steps, and traceable outputs.
That's also why security guidance matters. Teams should rely on established governance and technical controls instead of treating AI as a separate convenience layer. For organizations building internal policy around this, AI security best practices for enterprise deployment can help frame the questions legal, IT, and security need to answer together.
The goal isn't zero risk. Legal work never offers that. The goal is managed risk with clear accountability.
The Future of the AI Powered Legal Team
The future of legal document management isn't a law department run by bots. It's a legal team that spends less time hunting through files, less time repeating first-pass review, and more time on judgment, negotiation, and business counsel.
That's the central shift in how legal teams use AI for document management. The repository stops being a passive record and starts functioning like an accessible knowledge base. Search improves. Review becomes more targeted. Compliance support moves earlier. Legal work gets more scalable without flattening professional judgment.
The teams that benefit most won't be the ones that buy the most tools. They'll be the ones that do two things well. First, they'll measure whether AI changes real workflow outcomes. Second, they'll build governance that keeps adoption safe enough to scale.
Legal leaders don't need perfection before they start. They need a narrow use case, a defined review model, and KPIs that show whether total document lifecycle effort is going down.
AmasaTech helps organizations deploy AI in a way legal and operations teams can actually defend. If you're evaluating document intelligence, RAG, or workflow automation and want a partner focused on measurable outcomes instead of feature theater, explore AmasaTech.