
API Architecture for SaaS & AI A Founder’s Guide
Your product probably works fine in the demo.
A user signs up, the dashboard loads, the AI assistant answers a few prompts, and the integration with one partner looks clean enough. Then growth starts exposing the parts nobody talked about in the sprint review. Response times stretch. Engineers add one more endpoint to patch a workflow. A big prospect asks for audit logs, tenant isolation, and a custom integration. Suddenly the issue isn’t “the API.” It’s your api architecture.
That phrase sounds technical, but the business effect is simple. Your API architecture decides how easily your product can connect, scale, secure data, and absorb change without turning every roadmap item into a rewrite.
For SaaS and AI products, this matters earlier than most founders expect. Your API isn’t just a developer interface for third parties. It becomes the contract between your frontend and backend, between your orchestration layer and your model servers, between your app and every customer system you need to touch. If you're trying to build an AI-first company, the operating model has to support that reality from the start, not after launch. A useful framing is becoming AI-first as an operating shift, not just adding AI features on top.
Why Your API Architecture Defines Your Product's Future
In large enterprise environments, APIs account for more than 70% of web traffic, which is why they’ve moved from background plumbing to central control layers for scale, reliability, and risk management, as noted in this API trends analysis. That’s not just an enterprise concern. Startups inherit the same logic once integrations, automation, and AI workflows become core to the product.
A founder usually feels api architecture problems in business terms first. Sales cycles slow because enterprise buyers ask integration questions your team can’t answer cleanly. Cloud bills rise because services call each other inefficiently. Product velocity drops because every new feature has to work around brittle endpoints and inconsistent data shapes.
Think of the API as your operating contract
An API is the agreement that tells every system how to ask for something, what it will receive back, and what rules apply. If that contract is clear and stable, teams move quickly. If it’s vague, duplicated, or overloaded, small changes ripple across the company.
A useful analogy is the central nervous system. Your UI, mobile app, automation engine, billing service, analytics pipeline, and AI models all send signals through it. If the signaling is reliable, the body works. If signals are delayed, malformed, or blocked, the whole product acts unreliable even when individual parts are technically “up.”
Practical rule: Founders should treat API decisions like product strategy decisions, because they lock in cost structure, delivery speed, and security posture.
The second-order effects show up later
Bad api architecture rarely kills the first version. It punishes version two.
Common second-order effects include:
- Slower shipping: Engineers spend time translating between inconsistent endpoints instead of building features.
- Higher cost-to-serve: Chatty APIs create extra requests, repeated data fetches, and avoidable compute.
- Harder compliance reviews: Auditors and security teams ask how requests are authenticated, logged, and isolated by tenant.
- Fragile AI workflows: Agents and model pipelines depend on predictable interfaces. Unclear contracts create hard-to-debug failures.
The right architecture won’t make a weak product strong. But the wrong one can make a strong product expensive, slow, and difficult to trust.
Understanding Core API Concepts Without the Jargon
If API discussions feel abstract, use a restaurant model.
The customer is your app or partner system. The waiter is the API. The kitchen is your backend logic, database, or model server. The customer asks for something, the waiter carries the request to the kitchen, and the kitchen sends back a result.

That mental model is enough to understand most architecture conversations.
The pieces that matter most
An endpoint is a place where the waiter can take an order. In practice, it’s a URL or route such as “customers,” “invoices,” or “predictions.” Good endpoints describe business resources clearly. Bad ones expose internal confusion.
A request is the order itself. It includes what the client wants, any identifying details, and often proof that the client is allowed to ask. A response is what comes back, whether that’s customer data, a created record, a model prediction, or an error.
The method tells the server what kind of action is being requested. For non-technical founders, the shorthand is simple:
- GET: Fetch something
- POST: Create or submit something
- PUT or PATCH: Update something
- DELETE: Remove something
Payloads and status codes
The payload is the package of data moving in or out. In most web products, that’s JSON, which is readable enough for humans and easy for many systems to use. In AI systems, payloads can also involve larger or more structured data like embeddings, document chunks, or image references.
A status code is the waiter’s quick answer about what happened. “Success.” “You’re not authorized.” “That item doesn’t exist.” “Try again later.” You don’t need to memorize the codes. You do need to know that clean APIs communicate failure clearly, because unclear failures waste engineering time and frustrate customers.
Why founders should care about these basics
Once you understand endpoints, requests, responses, and payloads, technical debates become easier to evaluate. You can ask better questions:
| Question | What it reveals |
|---|---|
| Why are we making so many calls for one screen? | Data model and endpoint design |
| Why does this integration need custom logic? | Contract inconsistency |
| Why are retries causing duplicate actions? | Idempotency and request handling |
| Why is the model service slow? | Payload size, protocol choice, and backend orchestration |
If your team can’t explain an endpoint in plain business language, the design probably reflects internal implementation details instead of customer needs.
The best api architecture usually feels boring from the outside. Requests are predictable, responses are consistent, and the business logic is easy to reason about.
Comparing Major API Architectural Patterns
Choosing api architecture is less like picking the “best” language and more like choosing vehicles for different roads. A delivery van, a race car, a train, and a bicycle all move things. They just optimize for different constraints.
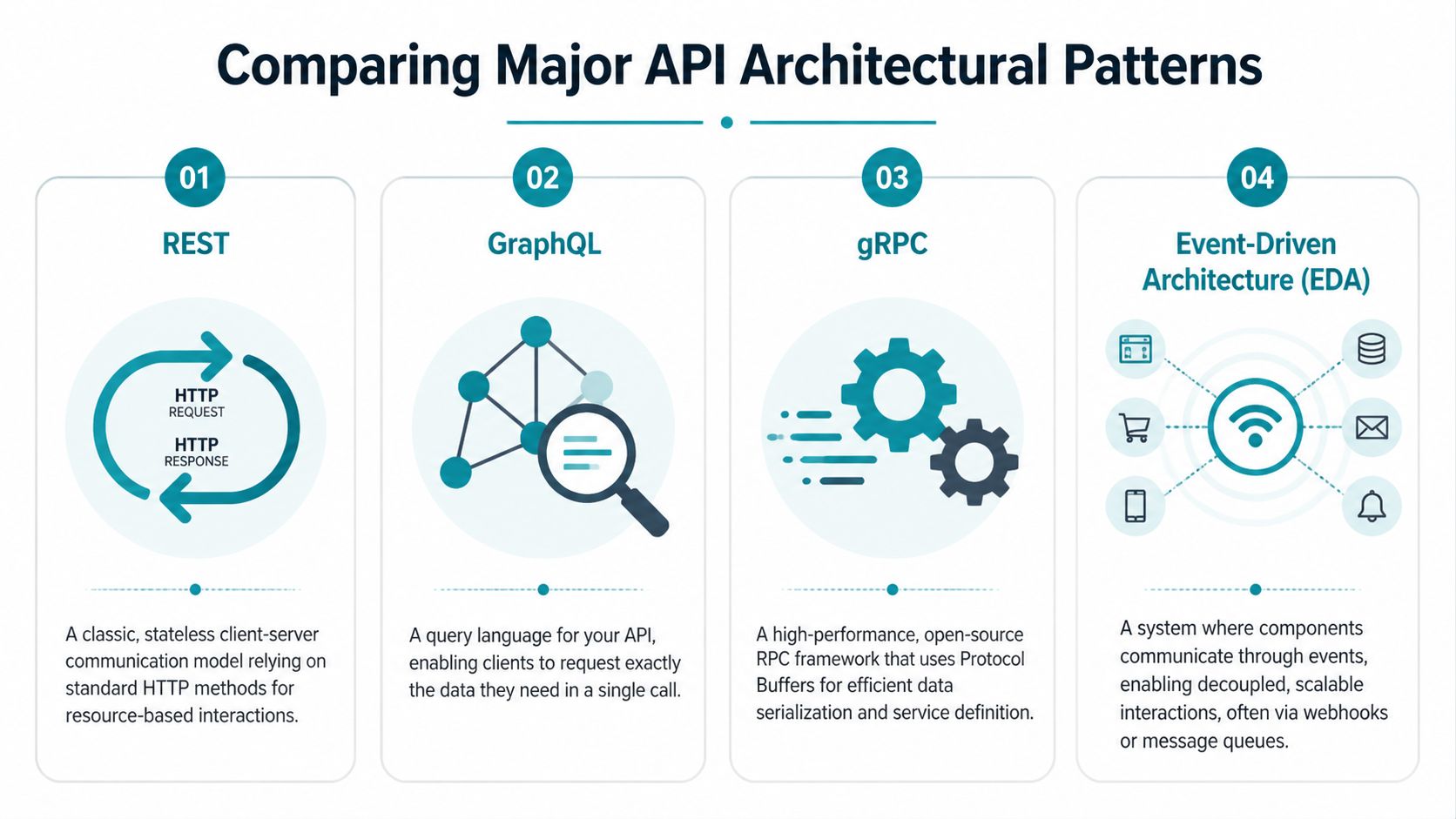
The four patterns most founders will run into are REST, GraphQL, gRPC, and event-driven architecture such as webhooks or message-based workflows.
REST works because almost everyone understands it
REST dominates API adoption, with 93.4% of API developers using it as their primary architecture style, making it the de facto standard for web API development according to Nordic APIs’ roundup of API economy statistics. That prevalence matters because standards reduce friction. Partners, contractors, and internal hires already know how to work with it.
REST treats data as resources. A customer is a resource. An invoice is a resource. A document extraction job is a resource. Clients use standard HTTP methods to create, fetch, update, or delete those resources.
REST usually fits when:
- You need broad compatibility: Public APIs, partner integrations, and customer-facing developer portals benefit from familiar patterns.
- Your domain maps cleanly to business objects: Accounts, users, orders, cases, tasks, and reports work well.
- Debugging speed matters: JSON requests and responses are easy to inspect with tools like Postman or Insomnia.
Where REST struggles is efficiency in complex interfaces. A single page may need several related objects, and the client may either fetch too much data or make multiple round trips to piece together one view.
GraphQL gives clients more control
GraphQL flips the model. Instead of the server defining many fixed endpoints, the client asks for exactly the fields it needs through a query.
That’s attractive in products with flexible interfaces, dashboards, or mobile apps where different screens need slightly different slices of data. A product team can evolve the frontend faster because it isn’t blocked every time it needs one extra field.
But GraphQL moves complexity to the server and governance layer. Teams have to think carefully about query depth, performance controls, and caching strategy. A bad GraphQL setup can become a buffet where every client grabs whatever it wants without anyone watching the kitchen load.
A founder should like GraphQL when frontend agility is the priority. A founder should be cautious when the backend team is small, observability is weak, or customer data access rules are already complicated.
gRPC is built for fast internal communication
gRPC behaves more like calling a function across systems than interacting with a classic web resource. It’s strongly typed, efficient, and usually best for service-to-service traffic inside your own platform.
AI products often derive real value as internal retrieval services, ranking layers, model routers, feature stores, and inference workers communicate with less overhead than a plain JSON-based setup.
The trade-off is practical, not philosophical. gRPC is harder to inspect manually, less natural for browser clients, and not usually what you want to expose as your main public developer API.
Use REST when humans and partner teams need something easy to understand. Use gRPC when machines inside your platform need to move fast.
Event-driven architecture reduces constant polling
Event-driven architecture lets systems communicate by publishing events instead of waiting for direct request-response calls every time. Webhooks are the simple example. Your system tells another system, “a payment settled,” “a document was processed,” or “a risk score changed,” and the receiving system reacts.
This works well when:
- Work is asynchronous: Document extraction, long-running imports, model training, and batch processing shouldn’t block a user request.
- You need looser coupling: A billing event can trigger notifications, analytics updates, and downstream workflows without every service knowing about every other service.
- Real-time reactions matter: Fraud alerts, inventory updates, and workflow triggers fit naturally.
What doesn’t work is using events as an excuse to avoid clear contracts. Teams sometimes build event-driven systems that are hard to trace, impossible to replay safely, and full of hidden dependencies.
A founder-friendly comparison
| Pattern | Best fit | Main strength | Main weakness |
|---|---|---|---|
| REST | Public APIs and standard SaaS workflows | Familiar, broadly supported, easy to debug | Can require multiple calls or return extra data |
| GraphQL | Complex UIs and client-driven data needs | Clients request exactly what they need | Harder caching and query governance |
| gRPC | Internal microservices and AI pipelines | Efficient, typed, high-performance communication | Less friendly for public clients and browser use |
| Event-driven | Async workflows and real-time reactions | Decouples services and supports reactive systems | Harder observability and failure handling |
The pattern that works in practice
Most good platforms don’t choose one pattern for everything. They combine them.
A common setup looks like this:
- REST for public and partner integrations
- GraphQL for frontend-heavy applications with variable data needs
- gRPC for internal high-performance services
- Events for asynchronous or cross-system workflows
That mix usually beats purity. The architecture should match the job, not a team’s favorite framework.
Essential Components of a Modern API Stack
Architecture style is only part of the picture. Production systems also need operating components that keep traffic organized, controlled, and observable.
A useful way to think about the modern stack is a building entrance. You need a front door, security desk, visitor rules, and a maintenance plan. Without those, even a nicely designed building becomes chaotic.

The front door and traffic control
An API gateway is the front door. It receives requests, routes them to the right services, applies common policies, and gives your team one place to manage cross-cutting concerns. Products like Kong, Apigee, AWS API Gateway, and NGINX commonly play this role.
Without a gateway, teams often reimplement the same rules in multiple services. That creates drift. One endpoint handles authentication one way, another uses a different header, and a third forgets rate limits entirely.
Rate limiting is your crowd control. It decides how much traffic a client can send and what happens when they exceed that limit. This isn’t only about abuse. It protects downstream systems from spikes, accidental loops, and one noisy tenant degrading service for everyone else.
Security and identity
Authentication answers, “Who are you?” Authorization answers, “What are you allowed to do?” Founders often hear both discussed as one topic, but they create different business outcomes.
Strong authentication gets the right actor into the system. Strong authorization keeps that actor inside the right boundaries. In multi-tenant SaaS, those boundaries matter constantly. A support user may view account metadata but not raw documents. An AI workflow may run one model but not a premium feature set. A partner integration may write claims updates but never read billing records.
A practical stack often includes:
- Identity provider: Tools such as Auth0, Okta, or Amazon Cognito handle login, tokens, and federation.
- Token validation at the edge: The gateway or a shared auth layer validates requests before they hit core services.
- Policy enforcement in services: Sensitive actions still need authorization checks close to the data.
Versioning and operational hygiene
APIs change. The mistake is pretending they won’t.
Versioning gives you a plan for change without breaking customers. Some teams version URLs, some use headers, and some evolve contracts carefully enough to avoid frequent explicit version jumps. The method matters less than the discipline. If product changes unexpectedly break integrations, your API becomes expensive to trust.
The rest of the stack supports reliability:
| Component | Business purpose |
|---|---|
| Gateway | Centralizes routing, policy, and traffic handling |
| Auth layer | Protects customer data and partner access |
| Rate limiting | Prevents overload and controls fairness |
| Observability tools | Help teams diagnose latency, failures, and misuse |
| Versioning strategy | Preserves trust while the product evolves |
For teams building AI systems, these components often sit inside a larger delivery environment that includes orchestration, monitoring, and deployment support. Firms such as AmasaTech’s service team work in that layer alongside cloud providers and platform tools, especially when the API is part of a broader AI deployment rather than a standalone developer product.
Architecting APIs for AI and Model Serving
AI products expose every weak API decision faster than traditional CRUD apps do.
A normal SaaS request might fetch a customer record or update a ticket. An AI request may move embeddings, document chunks, image references, tool calls, prompt context, and model outputs through several services before a user sees a response. If the interfaces between those components are bloated or inconsistent, latency compounds.

Internal speed matters more than founders expect
From an enterprise AI platform perspective, api architecture directly shapes latency, throughput, and observability. In particular, gRPC over HTTP/2 with Protocol Buffers typically reduces payload size by 30 to 50 percent versus equivalent JSON payloads and can cut latency by 20 to 40 percent in high-concurrency scenarios such as batch inference or real-time computer vision, according to LogicMonitor’s API architecture analysis.
That has a direct business meaning. Smaller payloads and fewer delays can lower cost-to-serve and improve user experience at the same time. If your product depends on near-real-time responses, protocol overhead stops being an engineering detail and becomes a product constraint.
Match the pattern to the AI workflow
Different AI workloads want different API behavior.
A chat assistant usually needs fast conversational turns, tool calls, and clear error handling. A RAG pipeline needs efficient retrieval and predictable contracts between retrieval, reranking, and generation layers. A computer vision service may need to handle larger payloads or references to media objects while preserving low latency. A document pipeline often works better asynchronously, because extraction, validation, and human review don’t always belong in one synchronous request.
Here’s a practical mapping:
- Public AI endpoint for customers: REST often works well because it’s easy to integrate and document.
- Frontend with variable data needs: GraphQL can help if the application pulls together jobs, outputs, confidence data, and user actions in one screen.
- Model-to-service communication: gRPC usually makes more sense for internal pipelines where performance is a hard requirement.
- Long-running AI tasks: Event-driven flows are cleaner than forcing clients to hold open connections while jobs complete.
A lot of AI teams try to solve a workflow problem with a model change when the actual bottleneck is request design, serialization, or service choreography.
Design around large payloads and async work
One frequent mistake is shoving everything through one request because it looks simple in the client. Upload the file, run OCR, classify it, enrich it, call an LLM, write the result, and return the final answer. That looks neat in a prototype. It becomes fragile under load.
Better designs separate concerns:
- Accept the asset or reference
- Create a job
- Track status through a stable endpoint
- Emit completion events or callbacks
- Store outputs in predictable resource structures
That pattern helps with retries, observability, and customer expectations. It also prevents timeout-heavy systems where one slow dependency makes the entire request fail.
For teams exploring this area, generative AI development services often include this exact translation layer between product requirements and model-serving design choices.
Observability is part of the contract
In AI systems, debugging means more than checking whether a request returned 200 or 500. Teams need to know which retriever responded, which model version served the request, what tools were called, and where latency accumulated.
That’s why model-serving APIs need correlation IDs, structured logs, and consistent request envelopes. If you can’t trace a bad answer across the pipeline, you can’t improve reliability in any disciplined way.
Good AI api architecture doesn’t just move data. It makes the movement inspectable.
Building for Scale Security and Compliance
Security and scale aren’t features you add once revenue arrives. They’re properties of the design. If you postpone them, the cost shows up later as blocked deals, production incidents, and painful rewrites.
That’s especially true in multi-tenant SaaS. A simple API can look safe in a single-customer pilot, then break down once many customers share infrastructure, permissions diverge, and regulated data enters the system.
The blind spots that catch growing SaaS teams
Security guidance often covers obvious issues such as unsecured endpoints, weak authentication, and missing rate limits. The harder problem is architectural. As noted in this discussion of API security blind spots, many teams still lack clear patterns for the nuanced security architecture needed in multi-tenant, data-rich SaaS platforms across healthcare, fintech, insurance, and legal environments.
That gap matters because multi-tenant systems are full of edge cases. A request may be authenticated correctly and still expose the wrong tenant’s data. A support workflow may have legitimate access to metadata but not to underlying files. An AI layer may be allowed to generate summaries but not reveal raw source text to every user role.
What secure design looks like in practice
Secure api architecture starts with boundaries, not controls pasted on top.
Use tenant-aware identifiers and authorization rules from the beginning. Make ownership explicit in the request path, token claims, or policy layer. Keep sensitive decisions near the data access point, not only at the edge. A gateway can reject clearly invalid traffic, but it can’t replace domain-aware authorization.
A strong design also includes:
- Idempotency for critical writes: Payment actions, document submissions, and workflow triggers shouldn’t duplicate because a client retried after a timeout.
- Structured audit logs: You need to know who accessed what, when, and under which tenant or policy context.
- Least-privilege service access: Internal services shouldn’t receive broad permissions just because they operate inside your network.
- Sensitive output controls: Model responses may need filtering, redaction, or policy checks before they leave the platform.
The most dangerous API failures aren’t always breaches. Sometimes they’re ordinary requests that returned too much data to an authorized user.
Compliance is an architectural question
Founders often hear “we’ll handle compliance later” as if compliance were paperwork. In practice, the review always lands on system behavior. Auditors and enterprise security teams ask how data is segmented, how access is logged, how secrets are handled, and how requests are traced across services.
If you’re building in payments, identity verification, healthcare operations, or regulated back-office workflows, those questions arrive early. A real-world example category is real-time fraud detection in payment workflows, where event timing, authorization scope, and logging discipline all affect operational trust.
Scale fails when security is inconsistent
Many scaling problems are really consistency problems. One service logs request IDs. Another doesn’t. One endpoint checks tenant membership. Another trusts a frontend parameter. One async worker masks sensitive fields. Another writes them to a debug log.
A scalable API platform needs a few non-negotiable habits:
| Design habit | Why it matters |
|---|---|
| Consistent auth patterns | Reduces edge-case failures and integration confusion |
| Unified logging and tracing | Speeds incident response and supports audits |
| Tenant-aware authorization | Prevents data leakage across accounts |
| Retry-safe operations | Avoids duplicate actions during network failures |
The companies that handle scale well don’t “bolt on” these patterns. They refuse to ship core interfaces without them.
Your Practical API Design and Migration Checklist
Most founders don’t need to redesign everything. They need a way to evaluate what already exists and decide what to fix first.
Use this checklist when you’re designing a new platform, cleaning up an inherited stack, or planning an AI product expansion.
Start with business-critical flows
Audit the requests tied directly to revenue, trust, and delivery. Don’t begin with the prettiest documentation. Begin with signup, billing, document intake, model inference, reporting, and partner integrations.
Ask:
- Which API flows directly affect customer experience?
- Which ones create support tickets when they fail?
- Which ones are required in enterprise security reviews?
If a flow is business-critical, give it the cleanest contract and strongest observability first.
Review the data model before adding more endpoints
Architectural choices around data granularity, pagination, and rate limiting affect cost and reliability. In particular, a significantly nested, over-normalized REST data model with many joins can increase median API latency by 50 to 150 percent versus a denormalized, document-style model, according to this API design discussion.
That should change how founders think about roadmap pressure. If every new screen requires several dependent fetches across overly fragmented resources, your product gets slower and more expensive as features expand.
A practical review looks like this:
- Resource shape: Are endpoints designed around business tasks or internal database tables?
- Round trips: Does one user action trigger too many dependent requests?
- Payload discipline: Are clients receiving fields they never use?
- Pagination: Can large collections be fetched safely and efficiently?
Decide what belongs where
Not every interface should use the same pattern.
Use this short decision table during design reviews:
| Question | Likely answer |
|---|---|
| Do external customers or partners need broad compatibility? | REST |
| Does the frontend need flexible field selection across many objects? | GraphQL |
| Do internal AI or microservice calls need lower overhead? | gRPC |
| Does the process run asynchronously or trigger downstream actions? | Event-driven workflow |
Migration priorities for an existing stack
If your current api architecture is already messy, don’t try to replace it all at once. Sequence the work.
- Stabilize contracts first so new changes stop increasing chaos.
- Add observability where requests are slow or hard to trace.
- Standardize auth and tenant checks before exposing more endpoints.
- Split synchronous and asynchronous workloads so long-running jobs stop degrading interactive flows.
- Refactor the highest-cost or highest-latency services before lower-impact cleanup.
For teams that want a broader operational review before making those calls, an AI readiness checklist is a useful companion because API quality and AI readiness usually rise or fall together.
The true test is simple. Can your team explain why each major API exists, who it serves, what it costs, and how it fails safely? If not, you don’t have an api architecture yet. You have a collection of endpoints.
If your product is hitting integration friction, rising inference costs, or security review delays, AmasaTech helps teams translate AI and SaaS requirements into workable platform architecture. That includes assessing readiness, designing production-grade API and model-serving layers, and aligning technical choices with measurable operating outcomes.
Published via Outrank