
Test The Cloud: Your Guide To Flawless Deployment
Launch week changes the way teams think. The dashboard looks green, the deployment plan is signed off, and yet nobody in leadership is asking the easy question anymore. They're asking the hard ones. Will the app stay fast under real traffic, will a misconfiguration expose customer data, and will this cloud bill still look reasonable after the first billing cycle closes?
That's the moment when “it works in staging” stops being useful.
The problem isn't a lack of effort. Teams commonly conduct unit tests, a few integration checks, and perhaps a load test before go-live. What they usually don't have is a single framework that treats performance, security, resilience, and cost as one system. That's where cloud launches get risky. One team tunes speed, another handles access controls, finance watches spend, and nobody validates how those pieces behave together under pressure.
That gap matters. Industry data reveals that 1 in 3 cloud migrations fail entirely, with only 25% of businesses successfully meeting their migration deadlines, according to Auxis on cloud migration pitfalls. If you're about to test the cloud before a major launch or migration, the right move isn't adding more scattered checks. It's building one decision-making system that tells leadership what's safe, what's fragile, and what needs to change before customers feel it.
Your Cloud Launch Is Imminent Are You Confident?
A founder usually notices the same pattern a few days before launch. Engineering says the core flows are working. Product wants the release out the door. Operations is nervous about observability gaps. Security still has open questions. Finance wants to know whether the new architecture will behave the way the budget model assumed.
Those tensions are normal. What causes trouble is pretending they're separate problems.
A cloud deployment can pass feature validation and still fail in practice. Authentication can work in isolation but break when rate limits kick in. A background job can look harmless until it competes with customer-facing traffic. A storage policy can be technically correct but noncompliant with what legal or enterprise buyers expect. Leaders don't need optimism in that moment. They need evidence.
What leadership is really asking
When executives say, “Are we ready?”, they usually mean four things:
- Performance under pressure: Will response times hold when real traffic arrives?
- Security posture: Are permissions, secrets, endpoints, and third-party connections locked down?
- Operational resilience: What happens if a dependency slows down or fails?
- Financial control: Will scaling behave predictably, or will spend surge without warning?
That's why the right approach to test the cloud isn't a final QA pass. It's a structured pre-launch discipline that connects technical behavior to business risk.
Don't ask whether the platform works. Ask whether it keeps working when demand, failures, and cost pressure all show up at once.
A practical way to start is to put the launch through the same lens you'd use for any major transformation program. That means defining the desired outcomes, assigning owners for each risk domain, and forcing every test to answer a decision that matters. Teams that need help framing that journey often benefit from a broader AI adoption roadmap for operational change, especially when cloud deployment supports AI products or data-heavy workloads.
What a real framework changes
A real framework changes the conversation from “we ran tests” to “we understand failure modes.”
It gives engineering a way to prove readiness, security a way to verify control coverage, finance a way to validate usage assumptions, and leadership a way to sign off with fewer blind spots. That's what de-risks launches. Not more activity. Better coordination.
Defining Success Before You Start Testing
A cloud test plan fails early when nobody agrees on what a successful launch looks like. Engineering tracks latency, security reviews controls, finance watches spend, and leadership asks a different question: can we launch without creating operational risk we do not understand?
Define success before the first script runs.
That means setting a small set of launch criteria that connect technical behavior, resilience, security posture, and cost boundaries to an actual go or no-go decision. If those criteria are fragmented by team, testing turns into parallel activity instead of one readiness framework.
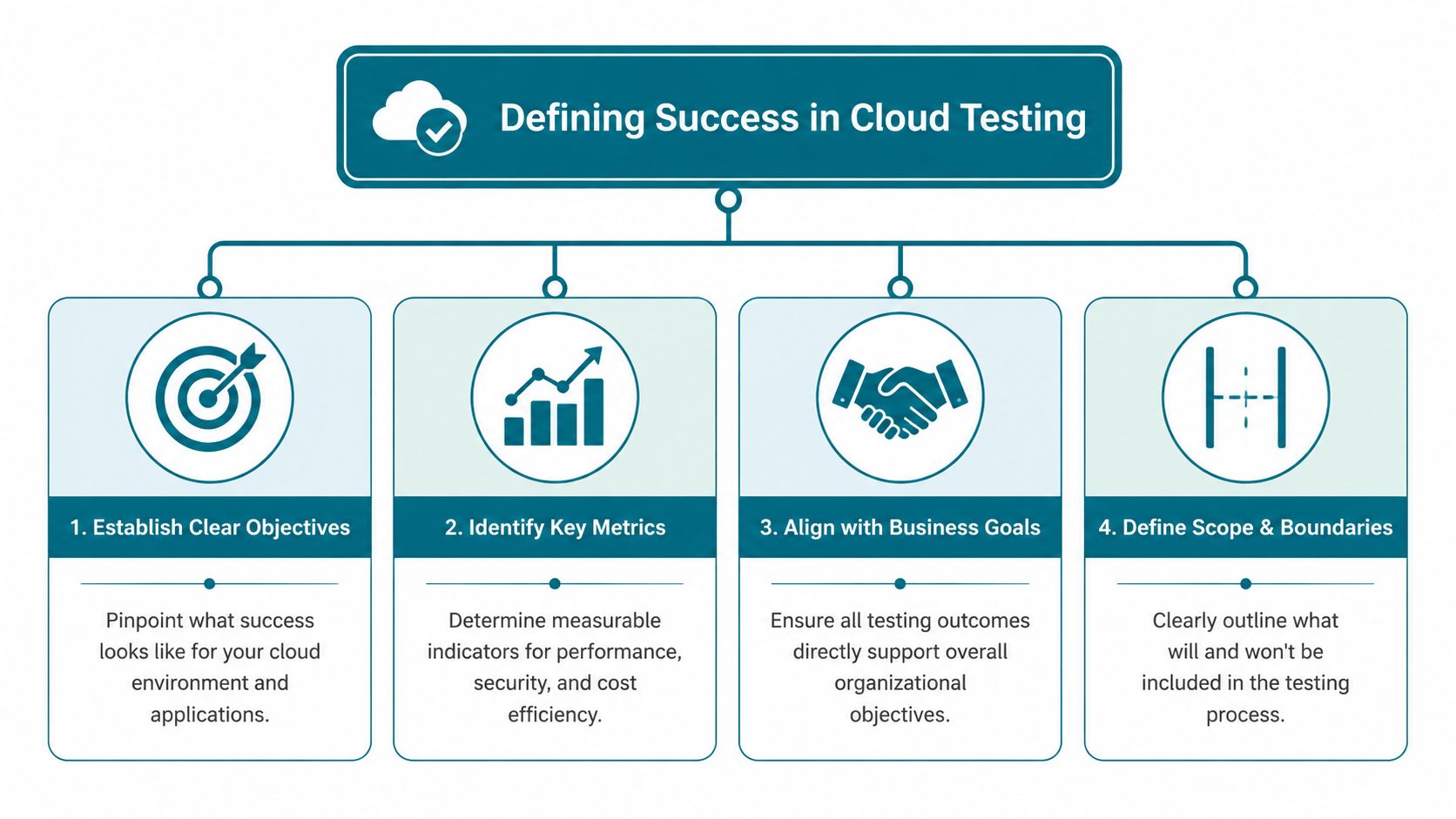
Build KPIs in three layers
Useful cloud KPIs usually fall into three layers. Each one exists for a different decision-maker, but they need to work together.
| KPI Layer | What to define | Why it matters |
|---|---|---|
| Technology | Response time targets, downtime tolerance, release quality, defect trends | Gives engineering a clear production standard |
| Business | Time-to-market, feature delivery cadence, customer experience outcomes | Helps product and leadership judge whether the launch creates the expected value |
| Finance | Spend efficiency, cost trends, savings from optimization | Lets finance and operations test whether the platform is sustainable under real usage |
At the technology layer, set hard thresholds. Define acceptable latency for the user journeys that matter, recovery expectations for key services, and the amount of disruption the business can tolerate. AWS recommends choosing cloud KPIs that tie platform metrics to business outcomes, rather than tracking infrastructure health in isolation, in its guidance on cloud success KPIs.
At the business layer, avoid vanity metrics. A release cadence target only matters if it supports a commercial goal such as faster onboarding, better conversion, or fewer customer-facing incidents after launch. This is the layer leadership will use to approve the rollout, so every KPI needs a clear owner and a decision attached to it.
At the finance layer, define acceptable cost behavior before the environment scales. Set limits for baseline spend, peak-event spend, and unit economics for the workload. Google Cloud's framework for cost optimization is useful here because it pushes teams to test whether architecture choices, autoscaling policies, and storage patterns behave as expected under load, not just whether the monthly bill looks reasonable after the fact.
Turn vague goals into testable questions
The fastest way to improve test quality is to rewrite each launch goal as a question the team can prove or disprove.
- Fast enough for launch becomes “Do the highest-value transactions stay within the agreed response threshold during expected and peak demand?”
- Secure enough for enterprise customers becomes “Do identity, network, logging, and data access controls meet internal policy and audit requirements?”
- Resilient enough for production becomes “If a dependency slows down, fails, or returns bad data, does the platform degrade in a controlled way?”
- Affordable enough to scale becomes “Does usage at normal and peak volumes stay inside the cost model approved by finance?”
This changes the quality of the test program. Teams stop collecting metrics for reporting and start gathering evidence for decisions.
Practical rule: If a KPI cannot trigger a launch decision, it is not a KPI. It is background telemetry.
Define scope before people over-test
Poor scope definition wastes time in two directions. Teams either test everything and learn very little, or they test the easy paths and miss the workflows that will create the biggest outage, security issue, or cost spike.
Set the boundaries up front. Name the systems in scope, the regions that matter, the critical user journeys, the third-party dependencies, the data flows, and the environments that must be certified for launch. Name the exclusions too, because excluded systems still create assumptions that need executive sign-off.
For early-stage teams or programs that are still tightening operating discipline, an AI readiness checklist for cloud deployment planning can help turn broad launch goals into specific test criteria, ownership, and approval gates. That structure matters because a unified testing strategy only works when every phase measures against the same definition of success.
Confirming Every Component Works Together
Most cloud failures don't begin with spectacular crashes. They begin at the seams. An API contract drifts. A retry policy floods a dependency. A queue consumer processes stale payloads. A token expires earlier than expected in one environment but not another.
That's why integration validation comes before aggressive performance work. If the system isn't logically sound, scale tests produce noise instead of insight.
Start with dependency mapping
A common mistake in cloud migration is assuming the architecture diagram reflects the actual system. It rarely does. Hidden performance bottlenecks often surface 3 to 6 months into a migration because teams missed system dependencies, as described in CloudOptimo's review of migration pitfalls.
Dependency mapping should be specific, not aspirational. Inventory every connection that can affect behavior:
- Service-to-service calls: Internal APIs, event buses, message queues, scheduled workers
- External dependencies: Payment gateways, identity providers, analytics tools, file processors
- Data paths: ETL jobs, replication logic, caching layers, search indexes
- Control-plane dependencies: Secrets management, CI/CD hooks, observability agents, feature flags
What matters isn't just whether these components exist. It's whether the team knows what happens when one of them slows down, returns malformed data, or disappears for a few minutes.
Validate the seams, not just the features
A mature test the cloud process focuses on end-to-end behavior. Don't stop at “request returns 200.” Check whether the full business transaction completes correctly across all systems that touch it.
A practical validation set usually includes:
Authentication and authorization flows
Verify token issuance, expiry handling, permission boundaries, and service identities across environments.API contract integrity
Confirm schemas, required fields, versioning behavior, and backward compatibility. One mismatched field can break downstream processing unnoticed.Data consistency checks
Track a transaction from ingress to storage to reporting output. Make sure values, timestamps, and statuses remain consistent across services.Failure handling paths
Force third-party timeouts, partial writes, duplicate events, and delayed callbacks. Good systems fail visibly and recover predictably.
If your stack is API-heavy, a clean API architecture approach for modern platforms gives teams a better base for this kind of validation.
The cloud doesn't remove complexity. It distributes it across more services, more policies, and more assumptions.
What works and what doesn't
What works is testing with production-like identity rules, realistic payloads, and the actual integration patterns your application uses. What doesn't work is mocking every external dependency and then acting surprised when the actual system behaves differently.
What works is tracing business flows across service boundaries. What doesn't work is handing each microservice team a separate checklist and assuming the overall platform is fine.
The best integration test suites feel a little uncomfortable. They expose how much of the system depends on things nobody documented well enough. That discomfort is useful. It's far cheaper before launch than after.
Pushing Your Environment to Its Limits
Two weeks before launch, the dashboards often look reassuring. Core transactions pass. Autoscaling triggers. Average latency stays within target. Then a realistic spike hits, queues start to back up, retries pile on more traffic, and a dependency that looked fine in isolation turns into the first customer-facing incident.
That is why performance testing has to answer an operating question, not just produce a chart. The point is to see how the whole platform behaves under pressure, including application code, managed services, network paths, scaling rules, background jobs, and the cost of keeping the system stable while demand changes.

Use the right test for the right question
Different test types expose different risks. Running only one usually gives leadership the wrong kind of confidence.
| Test type | Main question | What to watch |
|---|---|---|
| Load test | Can the platform handle expected traffic? | Response time, throughput, resource use |
| Stress test | Where does it break, and how does it fail? | Error rate, saturation points, recovery behavior |
| Soak test | Does it remain stable over time? | Memory growth, queue buildup, long-tail latency |
Load testing checks whether expected demand fits the architecture you built. It helps validate response targets, concurrency assumptions, cache behavior, and infrastructure sizing.
Stress testing goes past planned demand on purpose. The useful output is not a pass result. It is a clear break point, a record of what saturated first, and evidence that the platform degrades in a controlled way.
Soak testing catches the problems short test windows hide. Connection leaks, slow memory growth, retry storms, queue drift, and storage churn often appear only after hours of sustained activity.
A mature test program connects all three. Performance, resilience, and cost are tied together in the same run. If the environment survives a spike only by scaling to an expensive footprint or by delaying async work until later, that result belongs in the decision record.
Track the metrics that expose operational risk
Average response time is rarely the metric that hurts you first. Tail latency, saturation, backlog growth, and recovery time usually tell the full picture.
A practical scorecard includes:
- P95 and P99 latency: Customer pain shows up in the tail long before averages look bad.
- Throughput by transaction type: Read-heavy and write-heavy paths fail differently.
- Error rate under load: This shows whether the platform remains logically stable as pressure rises.
- CPU, memory, disk, and connection pool pressure: Saturation at any layer removes headroom fast.
- Queue depth and drain rate: Backlog is often the first sign that the system is losing the race.
- Scale-out and scale-in behavior: Fast scaling helps only if sessions, caches, and workers recover cleanly.
As noted in Google Cloud's guidance on performance testing for web applications, useful testing mirrors realistic traffic patterns and measures the full system, not just the front end. That matters in cloud environments because a passing user-facing test can still hide a database bottleneck, exhausted NAT capacity, or a worker tier that imperceptibly falls behind.
Build tests around business traffic, not synthetic symmetry
Flat traffic curves almost never happen in production. Real systems get hit by bursts after notifications, reporting deadlines, regional peaks, batch imports, and retry behavior from other services.
A serious performance run should include:
- Real user journeys: Login, search, checkout, upload, report generation, or whatever drives revenue and support volume.
- Uneven concurrency: Sudden spikes, sustained busy periods, and partial recovery windows.
- Background activity: Scheduled jobs, event consumers, cache refreshes, admin workflows, and third-party callbacks.
- Data realism: Payload sizes, object counts, and query patterns that reflect production, including outliers.
- Scaling events: New instances joining, old ones draining, and caches warming under live demand.
A passing load test that ignores asynchronous work gives leadership confidence the platform has not earned.
Teams often focus on the load tool and spend too little time on workload design. I have seen expensive test rigs produce weak answers because they modeled a perfectly clean request pattern that no customer would ever generate. If you are comparing deployment models or trying to estimate orchestration overhead before launch, this review of budget-conscious AI orchestration solutions for cost-aware environments can help frame those environment assumptions.
Read results like the team that will get paged
A test run is useful only if the findings change operational decisions.
If latency stays within target but compute runs hot for the whole window, the platform has little room for an unplanned traffic jump. If autoscaling restores service after several minutes, the rule may work technically while still failing the customer experience. If the application keeps error rates low because retries mask upstream failures, support tickets will arrive before your dashboard shows a major outage.
The strongest teams review performance results next to resilience signals, security controls, and cost data. That unified view is what turns testing into launch evidence instead of a collection of separate checks.
Auditing for Security and Compliance Gaps
A cloud platform that performs well but exposes data, credentials, or excessive permissions isn't production-ready. Security testing has to sit inside the same operating framework as performance and resilience, not outside it as a final approval ritual.
The teams that get into trouble usually make one of two mistakes. They either rely only on automated scanners, or they rely only on annual manual review. Both approaches leave blind spots.

Security testing needs layers
A practical cloud security audit should combine several forms of validation.
Automated vulnerability scanning
Run scanners against images, dependencies, and exposed services. This catches known weaknesses quickly and should happen continuously in CI/CD, not just before launch.
Configuration audits
Cloud incidents often start with bad defaults or rushed changes. Review identity policies, storage permissions, secret handling, logging configuration, public exposure, encryption settings, and network boundaries. In many environments, the highest-risk issue isn't exotic exploitation. It's ordinary misconfiguration.
Manual penetration testing
Manual testing matters because human testers chain findings together. They check how a weak permission model, a missed validation rule, and an overexposed endpoint interact. Automated tools are good at pattern detection. They're weaker at business logic abuse.
Compliance is an engineering concern
SOC 2, HIPAA, and GDPR aren't just legal labels. They translate into operational requirements around access control, logging, retention, data handling, and change management. If your environment can't prove those controls are consistently enforced, compliance work turns into a scramble every time a customer asks for assurance.
A useful audit asks questions like these:
- Access review: Who can reach production data and why?
- Change traceability: Can you show what changed, when, and who approved it?
- Evidence retention: Are logs complete, protected, and easy to retrieve?
- Data handling: Do storage, backup, and transfer paths align with policy?
If your company is building regulated AI or customer-facing software, legal and compliance planning for AI startups is a useful companion to technical security work.
Security testing should create operational evidence, not just a list of vulnerabilities.
What actually breaks in cloud environments
The failures I see most often are boring in the worst possible way. Service accounts have broader permissions than they need. Logs exist but don't capture the events investigators will want later. Secrets rotate inconsistently between environments. Staging has looser controls, then deployment automation carries those assumptions into production.
Security work becomes far more effective when teams test the cloud with realistic workflows, realistic identities, and realistic attacker paths. That means validating not just whether a control exists, but whether the control still holds when deployments accelerate, dependencies change, and teams are under time pressure.
Validating Resilience and Cost Efficiency
The week before launch is where weak cloud designs get exposed. A failover test passes in isolation, the cost model looks reasonable in a spreadsheet, and leadership assumes the platform is ready. Then a dependency slows down under real traffic, autoscaling overreacts, retry volume spikes, and the first production incident arrives with a larger bill than expected.
Resilience and cost need to be tested as one operating model because the same design choice often affects both. Aggressive retries can protect availability for a few minutes and still multiply downstream load. Extra buffer capacity can reduce customer impact and still leave finance with no explanation for why spend doubled overnight.
Test the trade-off, not each domain in isolation
A useful validation plan asks two questions at the same time: does the service stay within its recovery target, and what does that recovery behavior cost?
| Area | Core question | Failure pattern if ignored |
|---|---|---|
| Resilience testing | Can the system absorb faults and recover predictably? | Minor faults turn into customer-visible outages |
| Cost validation | Does the architecture control spend under stress and recovery? | Incidents trigger waste, overscaling, or surprise bills |
That framing matters because cloud failures are rarely clean. A queue backlog can drive up compute, storage, and support load in the same hour. A regional impairment can push traffic into healthy zones and expose scaling policies that looked fine during normal demand.
Run failure exercises that reveal operating behavior
Controlled disruption is the fastest way to find out whether the platform is engineered to recover or just engineered to pass happy-path testing.
Start with a small set of scenarios that map to real business risk:
- Dependency slowdown: Inject latency into an upstream API and verify timeout budgets, retry limits, and fallback responses.
- Capacity loss: Remove nodes or containers during active traffic and confirm that load shifts cleanly without exhausting connection pools or saturating remaining instances.
- Backlog growth: Pause downstream consumers and measure whether queues drain predictably once processing resumes.
- Configuration churn: Rotate secrets or replace instances midstream and verify that applications reconnect without manual intervention.
The point is not to create chaos for its own sake. The point is to measure whether the system degrades in a controlled way, preserves data integrity, and returns to a stable state without a senior engineer stitching it back together by hand.
A resilience test is incomplete if it proves recovery time but ignores the resource spike and spend spike required to get there.
Validate cost using the same scenarios
Cost validation is strongest when it uses the same test events as resilience testing. That is how teams see the full consequence of a design decision.
Watch for four patterns:
Scaling that arrives late and exits late
Slow scale-out hurts users. Slow scale-in burns money long after demand falls.Recovery logic that multiplies load
Retries, duplicate processing, and repeated warm-up cycles often cost more than the original failure.Shared infrastructure that hides expensive workloads
Batch processing, analytics jobs, and customer traffic should not all ride the same scaling profile if one of them can distort the bill for the others.Poor cost attribution during incidents
Teams need to connect spend changes to a test event, a deployment, or a traffic pattern. If they cannot do that in preproduction, they will not do it under pressure in production.
The FinOps Foundation guidance on unit economics and workload optimization is useful here because it pushes teams to tie cloud spend to service behavior rather than reviewing invoices after the fact: https://www.finops.org/framework/capabilities/workload-optimization/
What works in practice
Test resilience and cost together in production-like conditions with the same telemetry, the same workload profile, and the same success criteria. If a dependency failure causes autoscaling to surge, that result belongs in one report, not split between SRE and finance. If recovery requires temporary overprovisioning, leadership should see the trade-off clearly and decide whether the customer protection is worth the operating cost.
Architecture diagrams do not answer those questions. Controlled stress, failure injection, and clear cost attribution do.
From Test Results to Actionable Next Steps
Test programs fail at the final step more often than teams admit. They generate evidence, but they don't turn it into decisions. Leadership gets a pile of charts. Engineers get a long issue list. Security gets separate findings. Finance gets a cost warning with no operating context.
That's not a cloud testing strategy. That's documentation drift.
Consolidate findings into one risk narrative
The strongest way to report results is to combine all domains into one executive view. Performance, security, resilience, and cost aren't independent. A scaling delay can create both latency risk and cost waste. A security control gap can slow releases and affect enterprise sales. A dependency bottleneck can hit both uptime and support load.
Use a simple reporting format like this:
| Testing Domain | Status (Red/Yellow/Green) | Key Finding / Risk | Business Impact | Recommended Action |
|---|---|---|---|---|
| Performance | ||||
| Security | ||||
| Resilience | ||||
| Cost Efficiency | ||||
| Integrations |
This works because it translates technical output into operating language. Executives don't need every chart. They need to know where launch risk sits, what it could affect, and what the team recommends next.
Prioritize by business exposure, not by annoyance
Not every test finding deserves the same urgency. Prioritize in this order:
- Customer-facing failures first: Broken transactions, major latency issues, data exposure risk
- Operational fragility next: Weak observability, unreliable failover, poor dependency handling
- Economic inefficiencies after that: Wasteful scaling, idle resources, expensive architectural habits
- Nice-to-have improvements last: Cleaner dashboards, noncritical tooling upgrades, reporting polish
A good remediation plan assigns an owner, defines the expected outcome, and sets a retest condition. If you can't explain what evidence would close the issue, the action item is still too vague.
Write the report leadership will actually use
An effective executive summary is short and blunt. It should include:
Launch recommendation
State whether the environment is ready, ready with conditions, or not ready. Don't bury the answer.
Top risks
List the few issues that matter most. Avoid mixing critical launch blockers with routine cleanup items.
Business implications
Spell out what each issue could affect, such as customer experience, compliance posture, release confidence, or cloud spend.
Immediate next actions
Name the owner and the validation step required before launch or before the next release.
If a report doesn't change a decision, it's only a record of activity.
Keep testing continuous
The most reliable teams don't treat test the cloud as a one-time pre-launch event. They turn it into an ongoing operating loop. New features change load patterns. Vendor updates change dependencies. Cost profiles drift. Permissions sprawl. Runtime behavior evolves.
Continuous testing doesn't mean repeating every full exercise every week. It means setting triggers for retesting. Significant architecture change, new integrations, major feature releases, scaling rule changes, and compliance-sensitive updates should all reopen the relevant test path.
That's how cloud confidence is built. Not from a single heroic push before launch, but from a repeatable system that keeps proving the platform deserves trust.
If you want help building that kind of operating system around cloud and AI delivery, AmasaTech works with teams to audit readiness, define outcome-based KPIs, and turn cloud, AI, and deployment complexity into measurable production results.