
AI MVP Development: Roadmap to Success
A lot of founders reach the same point at the same time. They have a credible product idea, they can see where AI could amplify results, and then the project stalls because every next step feels expensive, technical, and easy to get wrong. The questions pile up fast. Do you need your own model? Is your data good enough? Should you prototype with APIs first? What happens if the demo works but the product falls apart in production?
That’s exactly why ai mvp development matters. It gives you a way to test the core assumption before you commit to a large build, a large team, or a long roadmap. It also matches where the market is heading. The global AI-driven MVP market was valued at USD 288 million in 2024 and is projected to reach USD 541 million by 2031, while 83% of companies prioritize AI in 2025, according to Intel Market Research’s MVP development outlook.
The pressure is real, but the answer isn’t to bolt AI onto everything. The answer is to make disciplined choices early. If you're still figuring out whether your organization is ready to move, this guide on preparing for AI adoption is a useful starting point.
From AI Idea to Actionable Plan
A founder usually doesn’t start with a scoped problem. They start with a broad ambition.
“AI for customer support.”
“AI for healthcare operations.”
“AI for smarter procurement.”
“AI for personalized learning.”
None of those are product scopes. They’re themes. If you build from a theme, your team keeps adding assumptions, features, integrations, and edge cases until the MVP becomes a full platform in disguise.
The better move is narrower and less exciting on paper. Pick one painful job, one user moment, and one decision that AI can improve. That’s what turns an AI idea into an actionable plan.
Start with the decision, not the model
If a support lead wants faster triage, your MVP might classify inbound tickets and suggest a response draft. If a clinic manager wants less admin work, your MVP might summarize patient intake notes into a structured handoff. If a sales ops team wants better follow-up, your MVP might rank leads by likelihood to convert.
Those are different products, even if they all use language models.
Practical rule: If your MVP can't be described as one user doing one task better in one workflow, it's still too broad.
A common pitfall for many first-time teams is overreaching. They discuss GPT, LAG, RAG, embeddings, vector stores, orchestration layers, and fine-tuning before they’ve written a clear sentence about the job to be done. The technology stack should follow the business constraint, not the other way around.
What a strong first plan looks like
A useful AI MVP plan has four parts:
- A specific user problem. Not “improve productivity,” but “reduce the time support agents spend writing repetitive replies.”
- A trigger point in a workflow. The exact moment the AI feature appears.
- A measurable business effect. Faster handling, lower manual effort, better response consistency, higher conversion, or fewer escalations.
- A bounded operating environment. Which users, which data, which channels, and which edge cases are excluded.
That last point matters more in AI than in standard software. AI systems are probabilistic. They don’t just fail by crashing. They fail by sounding right when they’re wrong. A narrow scope gives you a way to evaluate outputs in context instead of arguing abstractly about whether the model is “good.”
Phase 1 Frame the Problem and Your Data Strategy
The most impactful work in ai mvp development happens before engineering starts. Teams lose months because they begin with “build an AI assistant” instead of defining a single use case, a valid dataset, and clear success conditions.
Successful AI MVPs reduce scope creep, which affects up to 70% of traditional projects, by tightly defining a single use case and measurable constraints upfront. That approach can raise success rates to 40% to 50%, based on TechMagic’s AI MVP development analysis.
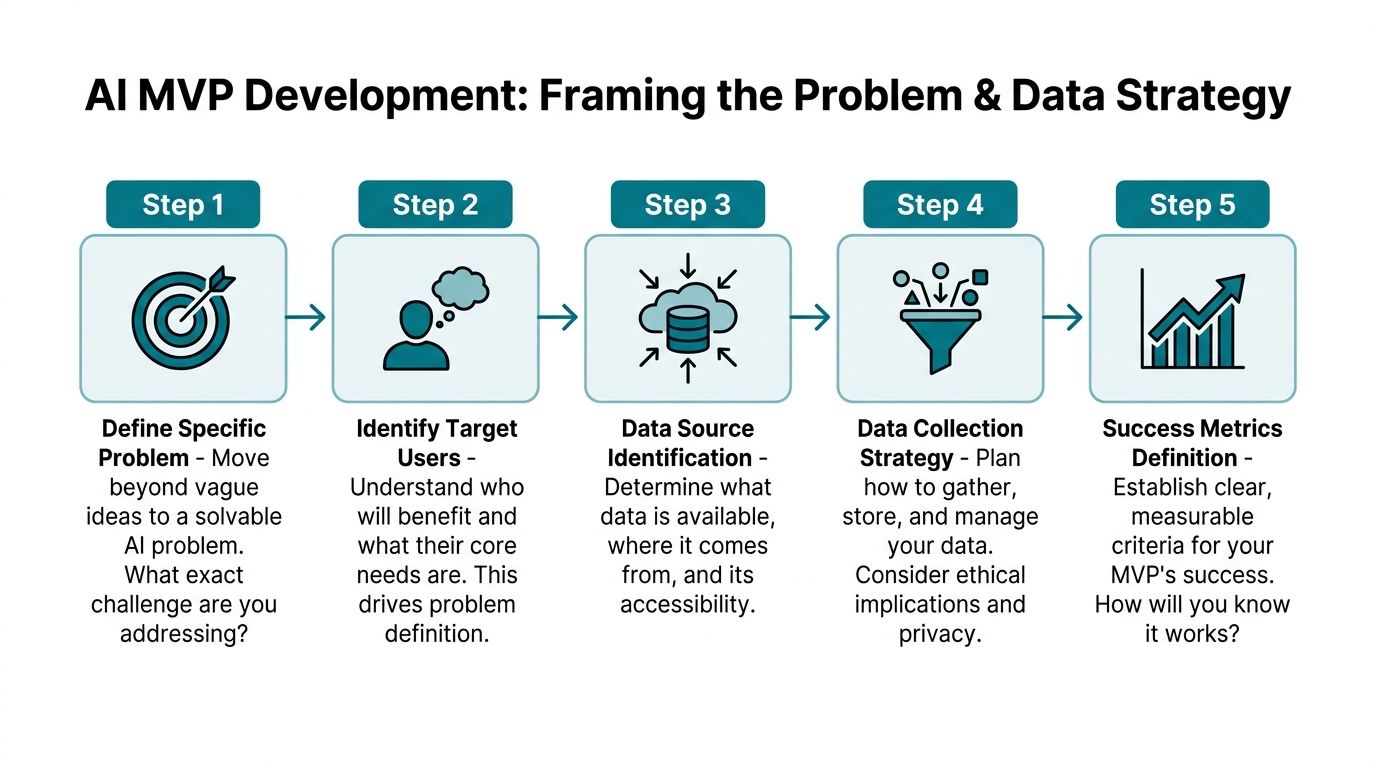
Write a one-page problem statement
You don’t need a long strategy document. You need a one-pager your product lead, ML engineer, designer, and founder can all read and interpret the same way.
Include these elements:
User and workflow
Name the user and the exact workflow step. “Support agents handling billing tickets” is stronger than “customer service.”Core pain point
Define what slows them down or causes mistakes. Keep it operational.Why AI is justified
AI should help with classification, extraction, generation, prediction, or ranking. If standard rules can solve the task reliably, use rules.Success metric
Decide what “working” means before launch. This could be time saved, acceptance rate of suggestions, user retention, or reduced manual review.Constraints
Set limits on latency, budget, privacy, compliance, and human review.
A team that can’t fill in those five fields clearly isn’t ready to prototype yet.
Decide whether your data is good enough
Founders often ask whether they have enough data. The practical question is different. Do you have enough relevant data to test the workflow credibly?
For a first MVP, “good enough” data usually has these traits:
- Task relevance. It reflects the exact problem you want to solve.
- Usable structure. You can clean it, label it, or retrieve from it without heroic effort.
- Representative variation. It includes the common cases users will encounter.
- Permission to use it. Legal access matters as much as technical access.
If your data is thin, you still have options. You can start with manual labeling, synthetic scaffolding used carefully for testing, retrieval over existing documents, or a human-in-the-loop workflow where the AI assists rather than automates.
Bad AI MVPs pretend data problems are model problems. Good AI MVPs surface data risk early and design around it.
Three data decisions that shape feasibility
Proprietary data or public model knowledge
If your use case depends on internal documents, policy rules, product catalogs, contracts, or domain-specific terminology, don’t assume a general model already “knows” enough. In that case, retrieval and grounded prompts often beat a generic chat interface.
Labeling effort or heuristic shortcuts
Some teams need labeled examples to evaluate outputs properly. Others can use business rules, existing categories, or user actions as proxies. The key is to choose a labeling approach that matches the MVP scope instead of trying to create a perfect long-term dataset on day one.
Clean now or learn first
If a dataset needs a full data engineering program before anyone can test the core workflow, the MVP scope is usually too ambitious. Tighten the use case until you can validate value with a smaller clean subset.
A practical way to pressure-test this stage is to run your scope against an AI readiness checklist. If basic questions about data ownership, review flow, or success metrics still feel fuzzy, don’t move to model work yet.
Phase 2 Prototype the Model and Minimal Architecture
Once the problem and data strategy are clear, the next mistake is overbuilding. Teams jump from “we validated the use case” to “let’s architect for everything we might need later.” That burns time before the first meaningful user signal arrives.
Your prototype should prove one thing. Can this AI feature create enough value in a real workflow that users want it to exist?

Choose the simplest model that can win
In early ai mvp development, model selection is usually a trade-off between speed, control, cost, and predictability.
Use this decision lens:
| Situation | Better first move |
|---|---|
| You need fast validation for text generation or summarization | Use a hosted pre-trained model via API |
| You need domain-grounded answers from internal documents | Use retrieval with a pre-trained model |
| You need repeatable classification on a narrow task | Start with a lightweight model or simpler NLP pipeline |
| You have strict control needs and stable labeled data | Consider fine-tuning after baseline validation |
That’s why many teams should begin with pre-trained systems such as GPT-style APIs, Llama-based options, or BERT-family models rather than building from scratch. You want to learn whether the workflow is valuable before investing in custom training.
A lightweight model can be the smarter choice when latency matters, when the task is narrow, or when cost per query has to stay low. A larger generative model can be the right choice when the output needs flexibility, but it also introduces more variation and more oversight requirements.
Build the thinnest architecture that still supports learning
“Minimal architecture” doesn’t mean sloppy. It means every component exists because it helps you test the hypothesis.
Keep the first stack lean:
Frontend
A basic web interface, internal tool, or embedded workflow surface. It only needs enough UI to let users complete the task and give feedback.Application layer
Prompt logic, business rules, guardrails, logging, and fallback behavior live here.Model layer
This could be an API-based LLM, a small classifier, or a retrieval pipeline.Data and analytics
Store inputs, outputs, user actions, and review outcomes so you can learn from usage.Human review path
In many MVPs, users need a way to correct, accept, reject, or override the AI.
What to avoid early
Don’t add a full multi-agent system because it looks impressive in a demo. Don’t build custom orchestration if simple service calls and clear logging will do. Don’t optimize for broad scale before you’ve tested repeated usage in a narrow audience.
Prototype architecture should answer product questions first. Scale questions come next.
If inference cost is already visible as a concern, or if you’re evaluating where orchestration complexity pays off, this breakdown of ways to save on AI orchestration services helps frame the trade-offs.
A good prototype is inspectable
A fragile prototype hides too much. A useful prototype lets your team inspect:
- the prompt or model input
- retrieved context
- output quality
- user acceptance or rejection
- failure cases by category
That visibility matters because AI products don’t improve through intuition alone. They improve when teams can trace bad outputs back to a broken assumption in prompts, retrieval, data quality, or workflow design.
Phase 3 Integrate, Validate, and Iterate with Users
The moment your AI touches a real user workflow, the standard for success changes. Model quality still matters, but now the harder question is whether the product saves time, reduces effort, or improves decisions enough to earn repeated use.
This phase is where founders make several expensive decisions in quick succession. Where should the AI appear in the workflow? What level of confidence is good enough to show a suggestion without review? Which failures are acceptable in an MVP, and which ones break trust immediately? Strong teams answer those questions deliberately instead of treating integration as a thin layer on top of the model.
Separate technical validation from business validation
Treat these as two different gates.
Technical validation checks whether the system performs within the bounds you set. Business validation checks whether the workflow change is worth adopting in the first place. A team can pass the first gate and still fail the second.
For example, a support copilot may generate solid drafts in testing, then underperform in production because agents have to stop, verify, edit, and explain the response. In that case, the problem is not only output quality. The actual issue is that the product adds friction at the wrong point in the job.
External benchmarks can help frame early expectations. SmartData’s AI MVP guide gives example targets for model quality, cost, and retention, and notes that lightweight models such as DistilBERT can perform well on suitable NLP tasks with modest labeled datasets. Use benchmarks as a reference point, not a decision rule. The right threshold depends on the cost of an error, the availability of human review, and how often users can tolerate a weak suggestion before they stop trusting the feature.
Put the AI inside a real job
The fastest way to learn is to place the AI in a narrow, repeated task that already exists.
Good MVP placements usually look like this:
- A support agent sees a suggested reply before sending
- An analyst receives a draft summary before publishing
- An operations lead reviews anomaly flags inside an existing dashboard
- A customer sees an assistant only for one repetitive question type
These setups work because they constrain the problem. They also make the decision framework clearer. If user trust is low, show suggestions instead of automating action. If review effort is too high, reduce the scope until the AI handles only the cases where it is reliably helpful. If latency interrupts the task, switch to a smaller model or change when the output appears.
A narrow customer service workflow is often a good example of this trade-off. Our guide to AI for customer service workflow automation shows how placement, review design, and escalation paths shape adoption as much as the model itself.
After teams collect the first round of usage, this kind of walkthrough helps clarify what to observe in practice:
Collect feedback that changes decisions
Early feedback should help you decide what to tighten, remove, or keep manual. It should not become a vague list of feature requests.
Track quantitative signals such as acceptance rate, completion rate, repeat usage, latency, manual overrides, and rejection patterns. Pair those with qualitative input from short interviews, tagged rejection reasons, and direct observation. When a user says, "I still have to check every answer," that is more actionable than a generic satisfaction score.
I usually look for one of three patterns first. The feature helps and users return to it. The feature is occasionally useful but too inconsistent to become habit. Or the feature works in theory and gets ignored because it appears at the wrong moment. Each pattern leads to a different decision. Improve reliability, reduce scope, or change workflow placement.
Iterate on failure modes, not wish lists
Founders often ask what users want next. In this phase, a better question is what failed, for whom, and under what conditions.
Review sessions should classify failures like this:
| Failure type | What it usually means |
|---|---|
| Wrong answer | Retrieval, prompt design, or source data issue |
| Slow response | Model choice, infrastructure, or unnecessary processing |
| Useful but not trusted | Missing evidence, weak explanation, or unclear UX |
| Accurate but ignored | Wrong placement in workflow |
| Good in demos, weak in practice | Production inputs differ from test cases |
That classification keeps iteration grounded in product decisions. A wrong answer might justify better retrieval. An ignored answer usually points to workflow design, not model tuning. Slow responses may mean the team chose model sophistication over task fit too early.
Users rarely say, “your retrieval chain is weak.” They say, “I still have to double-check everything.” That is the signal to work from.
The teams that improve fastest are disciplined here. They fix repeated failure modes, keep the review loop tight, and resist adding complexity until users come back without being pushed. That is the point where an AI MVP starts to behave like a product instead of a demo.
Planning Your AI MVP Timelines Budgets and Team
Founders usually underestimate two things at once. They underestimate how quickly a narrow AI MVP can be built, and they underestimate how much decision quality affects budget.
With AI-powered tools, simple AI MVPs can be built in 4 to 6 weeks, intermediate predictive systems in 8 to 12 weeks, and complex solutions in 3 to 6 months, according to Galaxy Weblinks’ AI MVP reality check. The same source notes that tools like GitHub Copilot can boost development speed by 2x or more.
Timeline depends on what is already true
The fastest projects usually share a few conditions. The use case is narrow. The workflow is known. Data already exists. A founder can make decisions quickly. The team is willing to use pre-trained components instead of insisting on custom systems too early.
The slowest projects usually have the opposite traits. Broad scope, multiple stakeholders, unclear data ownership, compliance surprises, and architecture debates before real validation.
AI MVP Resource Planning Guide
| MVP Complexity | Estimated Timeline | Estimated Budget (USD) | Core Team Roles |
|---|---|---|---|
| Simple AI assistant or chatbot | 4 to 6 weeks | Budget varies by data complexity, model usage, integration depth, and compliance needs | Product manager, full-stack developer, AI/ML engineer |
| Intermediate predictive or recommendation system | 8 to 12 weeks | Budget varies by data preparation effort, model evaluation needs, and workflow integration | Product manager, AI/ML engineer, data engineer, full-stack developer |
| Complex deep learning or multi-workflow AI product | 3 to 6 months | Budget varies significantly based on infrastructure, monitoring, security, and domain requirements | Product manager, AI/ML engineer, data engineer, full-stack developer, DevOps or platform engineer, domain expert |
No reliable budget figures were provided in the verified data beyond funding references unrelated to build cost, so any honest estimate has to stay qualitative. In practice, budget pressure usually comes from four places: data preparation, inference usage, engineering time, and compliance or security overhead.
Build the smallest team that can make decisions
A lot of AI MVPs don’t fail from lack of talent. They fail because nobody owns the trade-offs.
At minimum, you usually need:
Product owner
Someone has to define scope, reject distractions, and decide what the MVP will not do.
AI or ML engineer
This person handles model behavior, evaluation, prompt logic, retrieval, or lightweight training choices.
Full-stack developer
They connect the model to a real user interface and instrument the product for learning.
Then add roles only when the product demands them. Data engineers matter when source data is fragmented. Platform or DevOps support matters when deployment, security, and observability become active constraints. Domain experts matter when outputs require specialized review, especially in healthcare or regulated environments.
The leanest effective AI MVP team is not the smallest possible team. It’s the smallest team that can resolve product, data, and engineering decisions without stalling.
A realistic plan also leaves room for iteration. The first prototype isn’t the product. It’s the instrument you use to discover whether a product should exist in this form at all.
Common AI MVP Pitfalls and How to Avoid Them
Most AI MVP failures don’t happen because the original idea was bad. They happen because the team follows instincts that sound sensible but create expensive fragility.
One of the clearest examples is scale failure. Up to 80% of AI prototypes fail to scale to production, not because of the model itself, but because of systemic issues like data fragmentation, infrastructure limits, and missing MLOps for monitoring drift, according to GeekyAnts’ analysis of AI MVP roadblocks to production.

Pitfall one chasing perfect data
Teams often delay launch because the dataset isn’t complete, consistent, or beautifully labeled. That instinct can make sense in a research environment. It’s often harmful in product development.
If the workflow can be tested with a smaller high-signal subset and a human review layer, launch that version first. You need evidence about user value, not a pristine data warehouse.
A better question than “is the data perfect?” is “can we produce outputs that users can evaluate inside a controlled workflow?”
Pitfall two choosing model complexity for status
A bigger model can make a better demo. It can also increase cost, latency, unpredictability, and dependence on prompt tricks. For many first MVPs, a simpler retrieval flow, classifier, or smaller language model is the better product decision.
Use complexity only when the use case forces it.
Signs you’re overcomplicating the model
- The task is narrow but the stack is sprawling
- Your team can’t explain failures without reading logs for an hour
- The product depends on multiple AI steps before delivering one user action
- Latency is becoming part of the user complaint
- You’re defending architecture choices that no user has validated
Pitfall three building a demo instead of an operating product
A demo can hide weak assumptions. It uses handpicked inputs, a happy path, and a presenter who explains away mistakes. Production doesn’t.
That’s why your MVP needs basic operational habits from the beginning:
| Day 2 need | Why it matters |
|---|---|
| Logging | You need to inspect failure patterns |
| Output review | You need a path for correction and trust-building |
| Drift awareness | Model behavior changes as inputs change |
| Cost visibility | Good usage can still become bad economics |
| Ownership | Somebody must decide when to retrain, adjust prompts, or tighten scope |
An AI MVP becomes a product when the team can explain how it behaves on bad days, not only on good ones.
Pitfall four ignoring legal and domain constraints until late
This gets especially risky in regulated categories, but it applies more broadly. If your feature touches contracts, health information, financial workflows, hiring, or formal advice, governance can’t be an afterthought.
You don’t need to freeze innovation. You do need clear boundaries, review flows, and documented responsibility. For startups handling sensitive workflows, this perspective on AI legal consulting for startups is worth considering early rather than after a launch scare.
What usually works better
The strongest AI MVPs share a different posture:
- They narrow scope aggressively
- They use humans where confidence is low
- They track failure categories, not vanity outputs
- They keep architecture inspectable
- They prepare for production concerns before the pilot becomes popular
That’s what separates a fragile proof of concept from a product foundation.
Frequently Asked Questions about AI MVP Development
1. What is an AI MVP?
An AI MVP is the smallest version of a product that uses AI to solve one meaningful user problem in a real workflow. It’s not just a prototype with a chatbot added. It should produce usable outputs, allow feedback, and generate evidence about whether the feature creates business value.
2. How is ai mvp development different from regular MVP development?
The biggest difference is uncertainty. Traditional software usually follows deterministic rules. AI systems produce probabilistic outputs, which means the team has to validate not only whether the feature works, but how reliably it works, where it fails, and whether users trust it. Data quality, evaluation design, and human review matter much earlier.
3. How long does it take to build an AI MVP?
It depends on scope and complexity. Verified benchmarks show that simple AI MVPs can be built in 4 to 6 weeks, intermediate systems in 8 to 12 weeks, and more complex solutions in 3 to 6 months, as noted earlier in the planning section.
4. How much does an AI MVP cost?
There isn’t a single honest number for this without inventing one, and that would be misleading. Cost depends on the quality and availability of data, model usage, engineering effort, UI complexity, compliance requirements, and whether your team is building a narrow assistive workflow or a broader AI product. The best way to control cost is to reduce scope early and avoid unnecessary custom model work.
5. Do I need to train my own model?
Usually not for a first MVP. It's generally best to start with a pre-trained model, a lightweight task-specific model, or a retrieval-based workflow. Custom training becomes more sensible when the use case is stable, your data is strong, and the business case justifies greater control.
6. What data is enough to start?
Enough data means enough relevant examples to evaluate the core workflow credibly. It doesn’t mean complete enterprise-wide data readiness. If you can support a narrow use case with representative inputs and user review, you can often start learning without waiting for a perfect dataset.
7. What should I measure first after launch?
Track both technical and business signals. Technical measures can include output quality, latency, and inference cost. Business signals include repeat usage, acceptance rate, completion rate, and whether the feature reduces a real bottleneck for users.
8. Why do so many AI MVPs fail after a strong demo?
Because a demo can hide data fragmentation, poor workflow fit, missing observability, and lack of ownership after launch. Real products need monitoring, review loops, and clear operational decisions once users begin relying on them.
9. Should my first AI MVP be fully autonomous?
Usually no. In most first releases, an assistive workflow is safer and more informative than full automation. Human-in-the-loop systems help you manage risk, improve trust, and gather better training and evaluation signals.
10. How do I choose the right AI development partner?
Look for a team that can do more than integrate an API. You want product thinking, engineering depth, practical experience with data and model trade-offs, and enough discipline to stop you from overbuilding. A good partner will challenge your scope, not just accept it.
If you're planning an AI MVP and want a team that can help you scope it properly, build it fast, and prepare it for real-world scale, Amasa Tech works with startups and enterprises to design and deliver AI-first products that create long-term advantage.