
AI Readiness Test for Insurance: Your 2026 Roadmap
You're probably in one of two situations right now.
Either your team has a shortlist of AI ideas for underwriting, claims, fraud, or service, and nobody agrees on where to start. Or you already tried a pilot, got a decent demo, and then hit the actual insurance problems: data split across policy admin and claims systems, legal review slowing everything down, and business leaders asking how any of this will reach production without creating audit risk.
That's why an ai readiness test for insurance matters. Not as a box-checking exercise. As a way to answer a harder question: can your organization operationalize AI safely, with controls that stand up to regulators, auditors, and the business owners who will be accountable for outcomes?
Why Most Insurance AI Initiatives Fail Before They Start
Insurance leaders rarely lack ideas. They lack a clean path from idea to controlled execution.
A claims executive wants triage automation. An underwriting leader wants faster intake. A service team wants a policy assistant that can search documents and answer internal questions. All reasonable. But before the model discussion even gets serious, the same issues show up: conflicting data definitions, unclear ownership, no approval path for model changes, and no agreement on what a “good” decision explanation looks like.

That's why I treat readiness as a business control, not a technology warm-up. A proper test tells you whether the organization can support AI in production, not whether a vendor can produce an impressive demo.
Readiness is a strategy question
A useful benchmark comes from a Datos Insights study on AI readiness in insurance, launched in Q3 2023, which frames readiness as tied to time-to-market, operational efficiency, and customer satisfaction across both P&C and L/A/B insurers. That's the important shift. The industry no longer treats readiness as experimentation. It treats it as operating capability.
If you're still discussing AI as a side project, you're already behind the core issue. The issue is whether your operating model can support repeatable AI delivery.
For teams still aligning around first principles, AmasaTech's overview of AI adoption in insurance is a good companion read because it highlights how quickly ambition runs into execution friction in this sector.
What actually kills projects
The projects that fail early usually don't fail because the model is weak. They fail because the organization can't answer basic operational questions:
- Who owns the decision: If underwriting, claims, legal, and IT all have partial authority, projects stall.
- Where the source data lives: If no one can trace inputs across policy, billing, claims, and third-party data, trust collapses.
- How outputs will be explained: If the team can't show why a recommendation was made, the business won't put it in front of adjusters or underwriters.
- What success means in operations: If nobody defines the workflow change, the pilot stays a demo.
Practical rule: If your first AI conversation starts with model selection instead of decision ownership, data lineage, and approval workflow, you're not starting an AI program. You're starting a prototype.
An ai readiness test for insurance is the filter that prevents that mistake. It forces the organization to surface hidden dependencies before budget, reputational risk, and internal credibility are on the line.
The Eight Pillars of AI Readiness in Insurance
Most readiness checklists are too generic for insurance. They ask whether you have data, talent, and tools. That's not enough. In this industry, the gating factor is often governance.
Industry guidance summarized in this analysis of AI risk in insurance makes that clear. Readiness is shifting away from model capability and toward the institution's ability to handle oversight, bias review, and explainability.
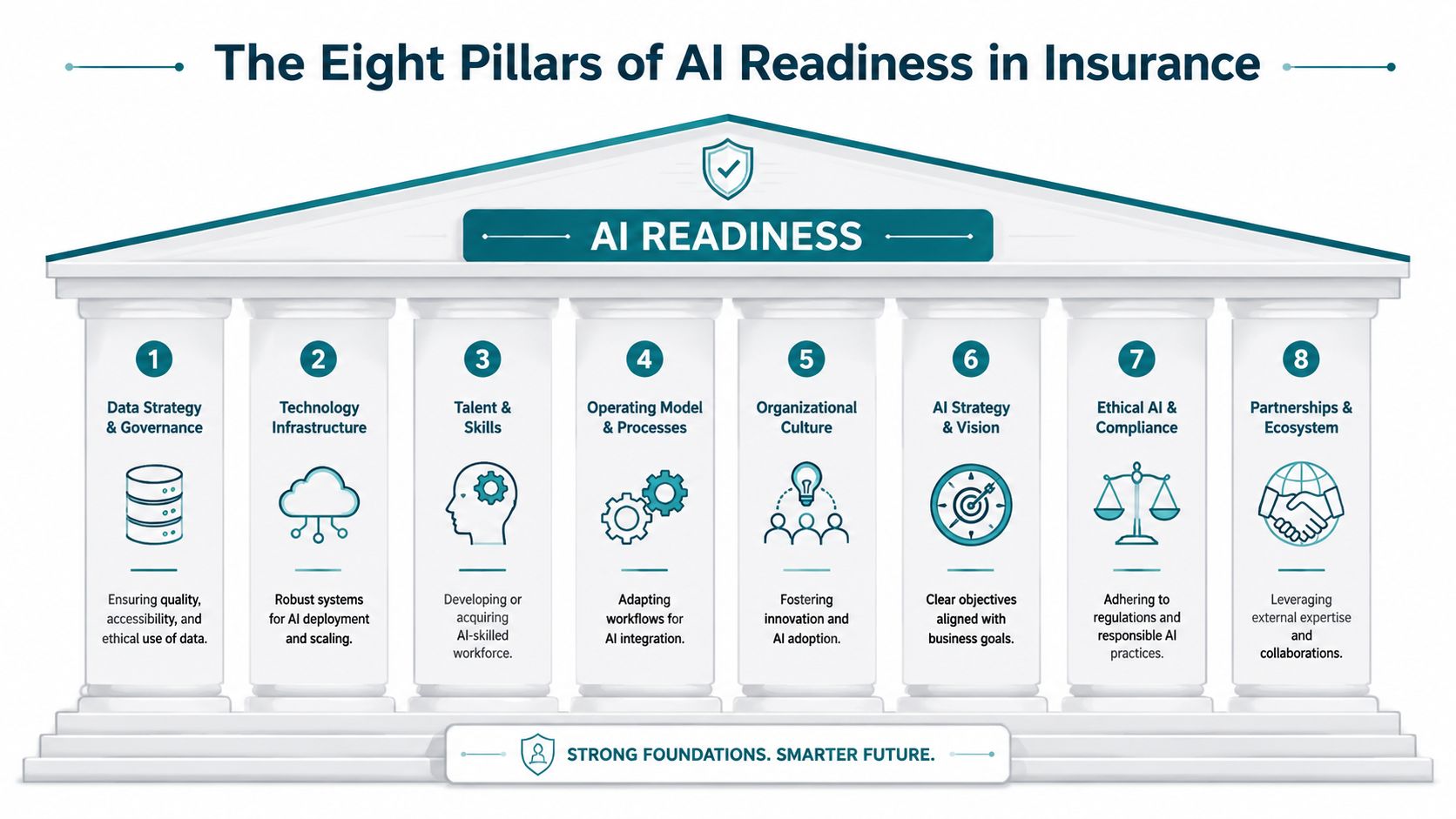
Pillar one and two
Data strategy and governance comes first because insurers don't just need data volume. They need lineage. If a claims severity signal or underwriting attribute influences a decision, the team must be able to show where it came from, how it was transformed, and whether duplicates or stale records distorted it.
Technology infrastructure is next. Production AI in insurance needs more than cloud access. It needs secure deployment paths, monitoring, rollback procedures, and support for ongoing model management. If your environment can't support controlled release and live observation, you're not production-ready.
Pillar three and four
Talent and skills matters, but not only in the data science team. Claims managers, underwriters, compliance leads, and product owners all need enough fluency to challenge outputs and escalate issues intelligently.
Operating model and processes determines whether AI becomes part of work or remains a side tool. Insurance firms need clear intake, approval, testing, release, and exception-handling processes. A model that recommends action but doesn't fit the adjuster workflow will be ignored.
A practical framework for assessing these capabilities appears in AmasaTech's guide to AI transformation readiness tools.
Pillar five and six
Organizational culture sounds soft until you watch a project stall because business leaders don't trust probabilistic outputs. Insurance teams are trained to control risk. If the culture treats model recommendations as suspect, adoption dies unless review paths and accountability are explicit.
AI strategy and vision keeps the effort disciplined. A strong strategy picks a narrow business problem, names an owner, and ties the work to operational metrics that matter in insurance. Without that, teams chase fashionable use cases instead of solvable ones.
Pillar seven and eight
Ethical AI and compliance is where most insurers underestimate the work. This is the pillar that covers explainability, customer disclosures, review rights, privacy handling, and documentation standards. In insurance, these aren't side concerns. They determine whether a pilot is acceptable to launch.
Partnerships and ecosystem matters because many firms won't build everything internally. The core question isn't whether you use vendors. It's whether vendor tools fit your control framework, integrate with your systems, and allow your team to retain operational accountability.
The strongest insurance AI programs don't start with “what can the model do?” They start with “what decisions are we willing to operationalize, under what controls, and with whose signoff?”
Those eight pillars create a readiness view that's actually usable. They reveal whether your biggest constraint is technical, organizational, or regulatory. In insurance, that distinction changes everything.
Your AI Readiness Questionnaire and Scoring Guide
A useful ai readiness test for insurance should feel less like a survey and more like an audit interview. The goal isn't to collect optimistic answers. It's to expose the gap between what the organization believes and what it can prove.
A practical audit sequence is outlined in this guide to what an AI readiness audit actually covers. It starts by inventorying use cases and owners, then checks data lineage, infrastructure readiness, and governance for explainability. That order matters. It prevents teams from debating tools before they've established accountability and data reality.
High impact questions by pillar
Use the questions below as a working self-assessment.
Data strategy and governance
- Can you trace a single input used in underwriting or claims from source system to reporting output?
- Do policy, billing, and claims teams use the same definitions for core fields?
- Can you identify where duplicate or stale records would affect model output?
Technology infrastructure
- Do you have an approved path to deploy AI into production, not just test environments?
- Can your team monitor model behavior after launch?
- Is there a rollback process if outputs create operational or compliance problems?
Talent and skills
- Do business owners understand what the model will and won't do?
- Do legal, compliance, and operations teams have named participants in AI reviews?
- Can internal teams challenge model output without waiting entirely on a vendor?
Operating model and processes
- Is every use case assigned to a decision owner?
- Do you have a documented review process for exceptions and escalations?
- Can frontline staff act on output without creating duplicate manual work?
Organizational culture
- Do managers trust decision-support systems enough to test them in live workflows?
- Are teams willing to surface failure cases early?
- Is AI being framed as workflow support rather than abstract innovation?
AI strategy and vision
- Is there a prioritized use case list tied to business problems?
- Has leadership agreed on what success looks like before build starts?
- Are pilots chosen because the data domain is strong, not because the use case sounds impressive?
Ethical AI and compliance
- Can you explain outputs in language suitable for regulators, auditors, and business users?
- Do you have approved documentation standards for model decisions?
- Is there a human review path for sensitive outcomes?
Partnerships and ecosystem
- Do vendor contracts support oversight, auditability, and change control?
- Can external tools integrate with core systems without manual workarounds?
- Do you retain internal ownership of decisions even when vendors provide models?
How to score answers
Score each pillar from 1 to 5.
| Domain | Score 1: Nascent | Score 3: Developing | Score 5: Leading |
|---|---|---|---|
| Sample AI Readiness Scoring Rubric | Ad hoc, undocumented, owner unclear | Basic structure exists, inconsistent execution | Controlled, documented, repeatable, business-owned |
Use that same rubric across all eight pillars. Then total the scores for an overall baseline and keep the pillar-level results separate.
How to keep the scoring honest
Don't score based on intent. Score based on evidence.
- Use artifacts: policy documents, data maps, approval workflows, release logs, exception procedures
- Interview multiple teams: claims, underwriting, IT, data, legal, compliance, operations
- Look for contradictions: a technology lead may say monitoring exists, while operations says no one reviews it
- Test one real workflow: choose one use case and walk the process end to end
If you want a simpler worksheet format before running a formal audit, AmasaTech's AI readiness checklist is a practical starting point.
Interpreting Your Score and Benchmarking Your Firm
A common insurance scenario looks like this. Leadership approves an AI pilot, the data team can build it, and legal is cautiously supportive. Then the effort stalls because no one can show data lineage across policy, claims, and third-party sources, or explain who owns model decisions once the pilot touches a live workflow. That is why score interpretation has to be stricter in insurance than in less regulated sectors.
Market benchmarks help, but only if they are read correctly. In an insurance industry survey summarized by Risk and Insurance, nearly 90% of executives said AI is a strategic priority, while only 22% had solutions in production. The same survey cited skills and resource constraints at 52%, data challenges at 40%, and a practical test of whether a firm can deploy one production-grade model with monitoring, explainability, and ROI tracking within 6 to 9 months. That gap matters. It shows how often insurers confuse interest with operational readiness.
A practical interpretation model
With eight pillars scored from 1 to 5, the maximum total is 40. Treat the total as a triage signal. Use the pillar pattern to decide whether a use case can move into controlled execution.
| Total score | Interpretation | What it usually means |
|---|---|---|
| 8 to 16 | High risk | Core controls are weak. Production use should wait until ownership, data controls, and approval paths are defined and tested |
| 17 to 28 | Mixed readiness | A narrow, low-risk use case may be feasible, but scale will expose unresolved control gaps |
| 29 to 40 | Operationally promising | A tightly scoped production use case may be realistic if the highest-risk pillars also score well |
The total can mislead. I have seen insurers score reasonably well overall and still fail the readiness test because one weak pillar blocked the whole program. In practice, governance, compliance, and data lineage carry veto power. A claims summarization tool with poor access controls is still a bad production candidate. A fraud model with weak escalation rules still creates risk, even if the model accuracy looks good in a sandbox.
What score patterns actually mean
Certain combinations show up repeatedly in insurance audits, and they point to specific failure modes.
High technical capability, low data governance
Teams can prototype fast, but production approval slows down once source quality, retention rules, or lineage questions surface.Clear strategy, weak operating ownership
Executive support exists, but no business unit is prepared to own exception handling, human review, or KPI accountability after launch.Strong infrastructure, weak compliance workflow
The platform is ready, but model approval, documentation, and change control are too immature for regulated use.Strong governance, weak business adoption
Controls are in place, but underwriting, claims, or care management teams do not trust the outputs enough to use them consistently.
Benchmarking your firm works best when you compare by operating reality, not by ambition. A regional P&C carrier should not benchmark itself against a global multiline insurer with a mature central data function. A better comparison is firms with similar product complexity, legacy system constraints, and regulatory exposure.
For that reason, I usually apply a simple threshold alongside the score. If the firm cannot put one low-risk, production-grade AI use case into operation within 6 to 9 months, with monitoring, documented review steps, and a clear business owner, readiness is still developing. That is not a failure. It is a signal to fix the blockers before more budget goes into pilots that cannot survive audit, compliance review, or frontline adoption.
A useful way to keep these gaps visible is to review readiness scores on the same cadence as delivery milestones. Teams that need that discipline often benefit from a simple AI transformation progress monitoring framework so remediation work stays visible after the initial assessment.
Example result profiles
Regional P&C carrier
This firm scores well on claims operations and business ownership, but poorly on data consistency across TPAs and core claims systems. The benchmark implication is straightforward. Start only if the first use case can run on a controlled subset of standardized data.
Life insurer with strong compliance controls
Governance is mature, but the business still has not aligned on where AI should fit into the operating model. That usually means the firm is safer than it is ready. The next step is a narrow use case with clear human review, not a custom model build.
Health plan exploring utilization review automation
The technology stack is capable, but appeal workflows, escalation rules, and documentation standards are immature. In a regulated area like utilization review, that score pattern points to decision support only. Full automation would create avoidable clinical, legal, and reputational risk.
Building a Prioritized AI Roadmap from Your Results
Once the score is clear, the next mistake is trying to fix everything at once. Insurance teams get the best results when they sequence the roadmap around risk, data reality, and operational ownership.
That usually means separating quick wins from structural work. Quick wins prove that the organization can launch responsibly. Structural work makes later use cases cheaper and safer.

Pick the first use case based on control, not excitement
A lot of insurers default to underwriting because it sounds strategic. That's often wrong.
As discussed in this insurance AI transformation analysis, many of the highest-value use cases are in claims handling, fraud detection, and utilization review. The practical implication is simple: choose the domain where data is mature enough and governance can support the stakes of the decision.
A simple prioritization lens
Use this matrix when deciding what comes first:
Fastest path to value
- Internal policy or claims knowledge assistant
- Claims document summarization
- Fraud investigation support with human review
Higher value, higher control burden
- Claims triage recommendations
- Underwriting intake automation
- Utilization review decision support
Delay until controls mature
- Automated denial decisions
- High-impact pricing recommendations without strong explainability
- Broad autonomous workflows in sensitive customer outcomes
If a workflow affects coverage, denial, prioritization, or financial outcome, the governance design should be drafted before the model design.
Match roadmap moves to readiness patterns
Different score profiles need different roadmaps.
| Readiness pattern | Quick win | Long-term move |
|---|---|---|
| Strong data, weak MLOps | Use a controlled document AI workflow with manual review | Build deployment, monitoring, and drift processes |
| Strong governance, weak use case focus | Run one narrowly scoped business workshop and pick one owner-led pilot | Build a formal intake and prioritization model |
| Strong talent, weak lineage | Standardize one domain's source data and definitions | Establish enterprise data governance for AI workflows |
| Strong infrastructure, weak culture | Launch internal copilots before customer-facing AI | Train business users and redesign workflows around review |
In practice, the roadmap should have three lanes.
Lane one
Control foundation includes approval workflow, documentation standards, review thresholds, and escalation paths. If these aren't defined, every later project becomes a negotiation.
Lane two
An operational pilot represents a single use case featuring a defined owner, restricted scope, and quantifiable operational outcome. For this stage, engaging an external audit partner or implementation support serves as a viable option among others. For instance, AmasaTech's AI adoption roadmap approach centers on an upfront audit, then phases quick-win deployments like chatbots or document workflows before more advanced model programs.
Lane three
Platform and scaling work includes reusable data pipelines, monitoring, and model governance. This isn't glamorous, but it determines whether your second and third AI initiatives get easier or harder.
That's the roadmap. Not a pile of pilots. A sequence that lowers risk while building institutional capability.
Taking the First Step on Your AI Journey
A claims leader greenlights an AI pilot to speed up document intake. Six weeks later, the work stalls. No one can confirm which source data is approved, compliance has not signed off on the review process, and the business owner assumed IT was handling model oversight. That pattern is common in insurance, and a self-assessment helps surface it before time and budget are spent in the wrong place.
A good self-test exposes what is blocking execution. In insurance, the blocker is often not interest or budget. It is weak lineage in claims or policy data, unclear approval rights, fragmented ownership across business and compliance, or governance that exists on paper but not in day-to-day operations.
That matters because internal teams are close to the work. They often normalize manual exceptions, inherited workarounds, and informal approvals. A control does not count because someone handled a similar issue once. It counts when the rule is defined, evidence is retained, and the operating team can follow it under pressure.
This is why firms that want production AI, not another contained pilot, usually need a formal audit. The goal is not to create more process. The goal is to test whether one use case can move into production with clear ownership, defensible controls, and a review path that stands up to legal, compliance, and operational scrutiny.
External benchmarking adds another layer of discipline. The Evident AI Insurance Index tracks insurers through publicly visible signals across Talent, Innovation, Leadership, and Transparency. That is useful because the market is starting to judge AI maturity based on demonstrated capability, not internal confidence scores.
Use that external view as a reference point, then return to your own operating reality. The fundamental question is simple. Can your firm support one production-grade AI use case without creating preventable risk for policyholders, regulators, or frontline teams?
If the answer is unclear, the next step is a deeper readiness audit of governance, data, operating model, and deployment controls. AmasaTech helps insurers turn a rough self-assessment into a structured AI audit for insurance workflows. The work focuses on identifying the safest high-value use case, exposing the blockers early, and building a roadmap that business, compliance, and operations teams can support.