
Agentic RAG Generative AI Integration: A How-To Guide
Your team likely already has a RAG prototype. It can answer policy questions, summarize docs, and pull snippets from a knowledge base. Then actual business requests arrive.
Support wants the assistant to check account status before answering. Ops wants it to pull data from a dashboard, compare it to an internal SOP, and recommend the next action. Compliance wants traceability, permissions, and a way to verify that the model didn't invent a step. That's the point where simple retrieval stops being enough.
Agentic rag generative ai integration matters when the job is no longer “find context and answer.” It matters when the system has to decide what to retrieve, which tool to call, how to verify the result, and when to escalate. That changes the architecture, the rollout plan, and the way you measure success. The right deployment doesn't start with bigger prompts. It starts with tighter orchestration, narrower scope, and business KPIs that prove the extra complexity is worth it.
Why Agentic RAG Is Your Next AI Upgrade

Basic RAG works well for a narrow class of problems. A user asks a question, the system retrieves relevant passages, and the model generates a response. That pattern is useful for FAQ bots, internal knowledge search, and document-grounded answers where the task is short and the path is obvious.
It breaks down when the request involves multiple steps, conflicting sources, or a required action. In those cases, one retrieval pass often returns either too much context, the wrong context, or context that still needs interpretation before a safe answer can be produced.
A key shift happened when the survey paper “Agentic Retrieval-Augmented Generation: A Survey on Agentic RAG” framed agentic RAG as a step beyond traditional RAG, using patterns like planning and tool use to dynamically manage retrieval instead of relying on static one-shot retrieval [arXiv survey on Agentic RAG]. That framing matters because it turns RAG from a retrieval accessory into an autonomous system design pattern.
What changes in practice
Traditional RAG is usually linear. Agentic RAG is conditional.
The system can inspect the request, decide whether retrieval is needed, choose the source, refine the query, call a tool, and validate the answer before it responds. That sounds subtle. Operationally, it's a major difference.
| Feature | Traditional RAG | Agentic RAG |
|---|---|---|
| Retrieval style | Single retrieval step | Iterative and adaptive retrieval |
| Decision logic | Mostly prompt-driven | Planner-driven with routing logic |
| Tool use | Limited or absent | Built to call tools and data sources |
| Handling multi-step work | Weak | Stronger fit for decomposed tasks |
| Verification | Often implicit | Explicit checks can be added before delivery |
| Best fit | Simple Q&A and search grounding | High-stakes workflows and task completion |
When the upgrade is justified
You don't need agentic RAG for every use case. If users ask straightforward questions against a stable corpus, standard RAG is often cheaper, faster, and easier to maintain.
Use the more advanced pattern when the work has these traits:
- Multi-step requests: The answer depends on intermediate reasoning, not just retrieval.
- Multiple systems: The assistant must combine unstructured content with APIs, SQL, or business tools.
- Verification requirements: The output needs a check before a user sees it.
- Operational completion: Success means finishing a workflow, not just returning a correct sentence.
Practical rule: If the system must decide, retrieve, act, and verify, you're no longer building a chatbot. You're building a controlled workflow.
That's also why many teams exploring agentic AI workflows in production end up redesigning more than the prompt. They redesign state management, tool permissions, fallback handling, and performance metrics.
Why leaders should care
This isn't just a technical upgrade. It's a business one.
A simple RAG assistant improves access to information. An agentic system can improve how work gets done. That's a different budget conversation. Accuracy still matters, but so do throughput, cost per resolved query, and whether the model can complete useful work without constant human rescue.
If your current assistant answers questions well but stalls on real operating tasks, agentic RAG is usually the next step.
Core Architecture and Orchestration Patterns
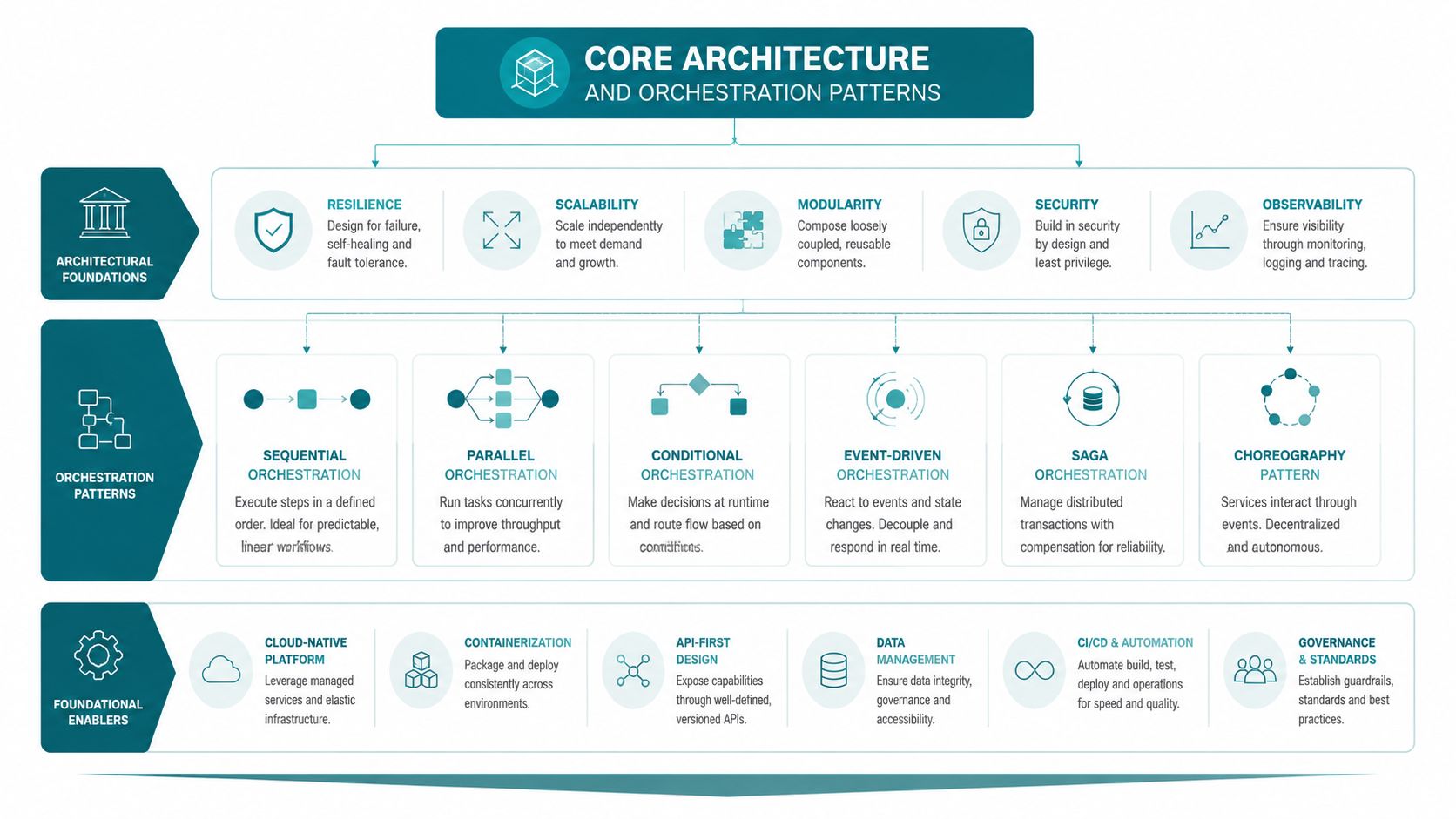
The cleanest way to think about agentic RAG is as a multi-stage control loop, not a retrieval feature. Expert implementations add a planning layer, verification before response delivery, and explicit validation gates around specialized subtasks [Rishabh Software on agentic RAG control loops].
A good production design behaves less like a single model call and more like a compact research team. One component scopes the problem. Others collect evidence. Another checks whether the answer is grounded enough to send.
The planner, retrievers, and critic
The planner handles triage. It classifies user intent, estimates task complexity, and decides the path. For a simple definitional query, it may skip expensive orchestration. For a messy operational request, it can split the problem into smaller steps.
The retriever layer shouldn't be one tool pretending to solve every problem. In practice, teams get better control when they separate retrieval modes:
- Vector search: Best for semantic lookup across long-form content
- Keyword or hybrid search: Better when exact terms, codes, or policy names matter
- SQL querying: Useful for structured business data
- API calls: Necessary when the latest state lives in operational systems
- Document parsers: Helpful for contracts, PDFs, and forms with uneven formatting
The critic or judge is the part many prototypes skip. That's a mistake. Before the final answer goes out, a judge node can test whether the generated response is supported by the retrieved material. It can also flag low-confidence cases for fallback or escalation.
A reliable agentic system spends effort before the answer, not after the complaint.
A practical orchestration loop
A production loop usually follows this sequence:
Intent routing
A lightweight model or rules layer checks what the user is asking and whether retrieval is required.Task decomposition
The planner breaks complex requests into sub-tasks such as policy lookup, account check, and next-step recommendation.Tool selection The orchestration layer picks the right source for each sub-task. Many systems either gain precision or waste tokens during this specific phase.
Evidence assembly
Retrieved passages, structured outputs, and tool results are normalized into a usable working context.Verification gate
The critic checks grounding, contradictions, and completion criteria.Response or escalation
The system answers, asks a clarifying question, or hands off to a person.
Where teams overbuild
The most common architectural failure isn't weak ambition. It's too much orchestration too early.
Multi-agent designs can improve grounding and cost control when they are scoped carefully. They can also create overhead fast. Every extra planning step, model call, and tool dependency adds latency and raises the odds of failure. If the router doesn't sharply constrain the path, the system spends too much time deciding what to do.
Here's the implementation pattern I recommend most often:
| Layer | What it should do | What to avoid |
|---|---|---|
| Routing | Quickly classify simple vs complex requests | Sending every query through a full agent loop |
| Planning | Decompose only when needed | Creating plans for obvious single-step tasks |
| Retrieval | Use source-specific tools | Forcing vector search to handle structured data |
| Verification | Check support before output | Treating generated fluency as evidence |
| Escalation | Stop safely on low confidence | Letting the system guess to avoid handoff |
The stack should match the economics
Architecture meets budget at this critical intersection. Use lightweight models for intent routing and early retrieval decisions. Reserve larger models for synthesis and edge cases. Keep state minimal. Cache where it helps. Add explicit timeouts to every external call.
If your team is also reworking service boundaries, API architecture for AI systems becomes part of the deployment, not a side concern. Agentic RAG fails without notice when tools have inconsistent schemas, weak auth patterns, or unreliable response contracts.
A good architecture doesn't make the system feel clever. It makes the system predictable.
A Phased Implementation Roadmap

Most failed deployments don't fail because the models are weak. They fail because the team tries to launch a broad assistant before deciding what business outcome it should own.
A better rollout is phased. Each stage should have a narrow scope, explicit KPIs, and a clear go or no-go decision.
Phase 1 audit and strategy
Start with one workflow, not one model.
Good candidates usually have clear demand, known data sources, and a measurable pain point. Examples include support case resolution, employee policy guidance, onboarding workflows, or analyst research tasks. Avoid broad “enterprise copilot” ambitions at this stage.
Use the audit to answer a few essential questions:
- Which task is expensive or slow today
- Which systems contain the required evidence
- What does a finished outcome look like
- Which KPI should improve first
- Where must a human stay in the loop
A useful deliverable at this stage is a workflow map with decision points, tool dependencies, and risk zones. If the process is simple and mostly informational, basic RAG may still be enough. If it requires iterative retrieval, tool use, or validation, agentic design is justified.
Teams planning broader transformation work often benefit from an AI adoption roadmap for staged deployment because the operating model matters as much as the stack.
Phase 2 pilot and iterate
The pilot should prove one thing. The system can complete a meaningful slice of work under controlled conditions.
Keep the first version narrow. One planner. A small set of tools. One critic gate. Limited user groups. Strong logging.
A solid pilot includes:
- A bounded use case: Don't combine support, analytics, and compliance in one release.
- A curated evaluation set: Use real tasks that reflect edge cases and failure modes.
- Explicit fallback paths: If a tool fails or confidence drops, route to a human.
- Trace capture: Log the plan, retrieved evidence, tool outputs, and final decision.
Decision test: If the pilot can't show a measurable lift on a single workflow, adding more agents won't fix it.
This phase also reveals hidden data problems. Missing metadata, poor document hygiene, inconsistent identifiers, and API gaps usually show up before prompt issues do.
Phase 3 scale and optimize
Only scale after the pilot produces stable behavior and a defendable KPI story.
At this stage, the work shifts from capability to operations. Harden permissions. Add environment-specific testing. Introduce better observability. Review latency budgets. Tighten escalation policies. Expand integrations one by one, not all at once.
The move to production usually requires these upgrades:
| Production need | What to implement |
|---|---|
| Reliability | Timeouts, retries, circuit breakers, graceful degradation |
| Governance | Permission-aware retrieval, trace logging, audit review |
| Cost control | Tiered model selection, caching, route constraints |
| Performance | Query optimization, source prioritization, async processing where appropriate |
| Change management | Versioned prompts, tool contracts, evaluation checkpoints |
The roadmap matters because agentic RAG is not a “flip it on” feature. It's an operating model. The fastest way to lose executive trust is to scale orchestration before proving control.
Designing Effective Agents and Data Strategies
Agent design and data strategy should be planned together. Many organizations separate them. One group writes prompts and tool specs. Another group manages search, metadata, and source systems. The result is predictable: smart agents with weak evidence, or good data trapped behind clumsy interfaces.
That separation becomes more costly as the market moves toward agents as a core layer. One industry source projects the AI agents market will grow from $7.84 billion in 2025 to $52.62 billion by 2030 and describes agentic systems as the control layer that makes generative AI more operationally useful [Kellton on agentic retrieval and AI agent market growth].
Design agents around job boundaries
Agents work better when each one has a narrow role, limited authority, and a clear definition of done.
Don't build a general “assistant agent” and hope prompts will create discipline. Instead, define roles such as request triage, policy retrieval, system lookup, or answer verification. Each role should have access only to the tools it needs.
A practical design checklist looks like this:
- Role clarity: Give each agent one job and one decision boundary
- Tool contracts: Use stable function schemas with predictable inputs and outputs
- State discipline: Store only the context needed for the next step
- Memory policy: Keep temporary task memory separate from long-term user memory
- Stop conditions: Define when the agent should answer, ask, retry, or escalate
If you want a quick way to pressure-test these patterns, reviewing concrete generative AI examples across business use cases is often more useful than reading abstract framework debates.
Match the retrieval strategy to the question
A strong agent still fails if the retrieval layer is blunt.
Vector search is useful, but it shouldn't be the only retrieval strategy. Business systems contain different types of truth. Policies live in documents. account status lives in applications. product hierarchies may live in relational data. connected decisions may depend on graph-like relationships across entities and events.
Use retrieval intentionally:
| Agent need | Data requirement |
|---|---|
| Semantic policy lookup | Chunked documents with clean metadata |
| Exact code or clause matching | Keyword indexing and fielded search |
| Customer or transaction checks | Structured APIs or SQL access |
| Connected relationship analysis | Graph-aware modeling or linked entities |
| Final answer grounding | Re-ranking and evidence packaging |
Re-ranking matters more than many teams expect. The first retrieval pass often finds related content, not the best supporting content. A second-stage relevance pass can improve the evidence that reaches the synthesizer and reduce unsupported conclusions.
Good agent behavior starts with data that has clear ownership, usable metadata, and stable access paths.
Prepare data for action, not just search
A lot of RAG work focuses on document ingestion. Agentic systems need more.
Prepare data with operational use in mind:
- Normalize identifiers: Product names, customer IDs, policy labels, and department terms should map consistently across sources.
- Add metadata that matters: Source type, freshness, access scope, document owner, and policy status all affect routing and trust.
- Separate authoritative sources: Mark which system is the source of truth for each kind of question.
- Version critical content: If a policy changes, the system should know which version applies.
The best agentic rag generative ai integration projects don't treat retrieval as a generic backend. They treat data access as part of workflow design.
Monitoring Performance and Ensuring Safety

Many teams still evaluate AI systems like chat demos. They read a few answers, decide the outputs look good, and call the pilot successful. That approach fails fast in production because agentic systems don't just answer questions. They attempt work.
A more useful standard is end-to-end performance. One published example defines task success rate as completed workflows without human rescue. If 162 of 200 onboarding workflows finish autonomously, the system reaches 81% task success [Sprinklr on task success rate in agentic RAG]. That framing is important because a factually correct answer can still be a business failure if the workflow doesn't complete.
Use a business dashboard, not just model metrics
Retrieval precision and recall still matter. They tell you whether the evidence layer is functioning. But they don't tell you whether the system solved the user's problem.
A stronger dashboard includes both technical and operational views:
- Task success rate: Did the workflow complete without human rescue?
- Time to completion: How long did the user wait for the outcome, not just the first token?
- Cost per resolution: What did the full orchestration path cost?
- Escalation frequency: How often did the system route to a person?
- Verification failure rate: How often did the critic reject the draft answer?
- Tool reliability: Which APIs or databases cause avoidable failures?
Many teams discover at this stage that a “high accuracy” assistant is still expensive or slow. A model can generate a grounded answer and still miss the operational target because a tool call failed, a permission was missing, or the workflow looped too long.
Build safety into the workflow
Safety in agentic systems isn't only about content moderation. It's also about execution boundaries.
An agent that can call tools, inspect records, and combine sources needs guardrails at each layer:
| Safety layer | What to enforce |
|---|---|
| Access control | Tool and data permissions by role and task |
| Retrieval boundaries | Source filtering based on sensitivity and relevance |
| Output checks | Verification against retrieved evidence before delivery |
| Escalation logic | Mandatory handoff for low-confidence or regulated cases |
| Audit logging | Full trace of plan, tools used, evidence selected, and outcome |
A practical monitoring setup should also capture the full agent trace. If a bad answer reaches a user, your team should be able to inspect the route taken, the tools called, the evidence returned, and the critic decision. Without that, debugging becomes guesswork.
Don't ask only “Was the answer correct?” Ask “Did the system finish the job safely, within budget, and with evidence we can inspect?”
For organizations building governance into AI programs, AI transformation progress monitoring is the right mindset. The deployment is not done when the agent responds. It's done when the team can measure reliability and intervene before small failures spread.
Watch the interoperability risk
Agentic RAG usually fails at the seams. The planning logic may be sound, but the workflow still breaks if the CRM, knowledge base, ticketing platform, and policy store don't interoperate cleanly.
One broader enterprise finding highlights why this matters. 87% of IT leaders rated interoperability as very important or essential, and lack of interoperability is cited as the second most common reason pilots fail after data quality, as discussed in the same Sprinklr analysis already cited above. That's not an abstract integration concern. It directly affects task completion, traceability, and cost.
Common Pitfalls and How to Mitigate Them
Agentic RAG is often described as a smarter version of RAG. That description is incomplete. It's also a more expensive operating model with more moving parts and more failure paths. One useful summary of the tradeoff is that the added layers of planning and multi-agent collaboration create hidden operational risks such as latency creep and tool brittleness, which means strict scoping and observability are necessary to keep the system from becoming fragile [agentic RAG operational tradeoffs in the arXiv HTML summary].
Latency creep
A system that plans, retrieves, retries, re-ranks, verifies, and then answers can become too slow for the business context.
The fix isn't “optimize later.” The fix is design discipline from the start. Put hard limits on loop depth. Route simple requests around the full orchestration path. Reserve larger models for synthesis, not every decision. Set time budgets at the workflow level, not just the model-call level.
Tool brittleness
Agents tend to look capable in demos because the tool path is clean. Production is messier. APIs throttle. Schemas change. Search indexes go stale. Permissions drift.
Mitigate that with controlled tool wrappers and graceful failure behavior:
- Timeout handling: Every tool call should fail fast and return a structured error
- Fallback logic: If a preferred source fails, route to a secondary path or escalate
- Contract testing: Validate tool schemas before release
- Freshness checks: Detect stale indexes or broken sync jobs before users do
Governance gaps
The final trap is governance debt. Teams can log prompts and outputs, yet still miss the actual audit trail because they don't capture the plan, source access, intermediate tool results, or validation decisions.
That creates trouble in regulated or high-stakes workflows. If a user asks why the system acted a certain way, “the model decided” is not an acceptable answer.
Use structured trace logging, role-based access to tools, and explicit review queues for sensitive cases. If a workflow can change records, trigger downstream actions, or expose internal policy guidance, it needs a visible chain of evidence and control.
The strongest agentic systems aren't the most autonomous. They're the ones that know when to stop, show their work, and hand off cleanly.
AmasaTech helps organizations turn AI plans into production systems tied to business outcomes, not demo metrics. If you're evaluating agentic RAG for a high-value workflow and want a partner that can audit readiness, define the right KPI, and build a phased rollout on secure infrastructure, explore AmasaTech.