AI Agent Integration: A Production-Ready Roadmap
Your team probably has the same problem I see in most growth-stage companies. Revenue is up, headcount is strained, and too many core workflows still depend on a few operators who know how to stitch systems together by hand. Sales ops exports data between the CRM and billing. Support managers triage tickets across inboxes and internal docs. Finance checks edge cases in spreadsheets because nobody trusts the automation enough to let it run unattended.
That's the moment when ai agent integration becomes real. Not as a demo in a sandbox, and not as another chatbot attached to your website. It becomes an operating decision about where software can plan, fetch context, use tools, and complete bounded work inside the systems your team already uses.
The market has moved faster than many operators realize. Enterprise adoption has already gone well beyond curiosity. According to McKinsey's 2025 state of AI research, 23% of respondents said their organizations are already scaling an agentic AI system somewhere in the enterprise, while another 39% said they had begun experimenting with AI agents. That changes the conversation. The question isn't whether agentic systems will show up in your category. It's whether your integration approach is disciplined enough to survive security review, operational reality, and KPI scrutiny.
Moving AI Agents From Experiment to Enterprise
Most companies don't fail with AI agents because the model is weak. They fail because they treat integration like a prompt engineering exercise instead of an operating model change.
That usually shows up in familiar ways. The team starts with a broad ambition like “automate support” or “build an AI SDR.” The first version can answer questions in a controlled demo. Then it hits real systems, real permissions, messy data, and real exception handling. Suddenly the work shifts from prompting to process design, system access, auditability, and ownership.
That's why ai agent integration should be viewed as enterprise plumbing, not feature theater. The agent has to fit into existing systems of record, existing approval logic, and existing accountability. If it can't do that, it stays stuck as a side project.
There's also a timing issue. Waiting for the market to “settle” sounds prudent, but it often creates a worse outcome. By the time leadership decides to move, competitors have already learned which workflows are safe to automate and which require tighter guardrails. Teams that started earlier usually haven't solved everything, but they've built operational muscle.
For companies trying to decide where to begin, a practical first step is to map agent work to business outcomes rather than model capabilities. A strong AI adoption roadmap for operational teams helps because it forces a harder question: where does autonomous or semi-autonomous execution create measurable advantage inside a real workflow?
Enterprise ai agent integration stops being experimental when a team assigns KPIs, owners, access boundaries, and rollback rules before the first production release.
The rest of the work is about doing that well.
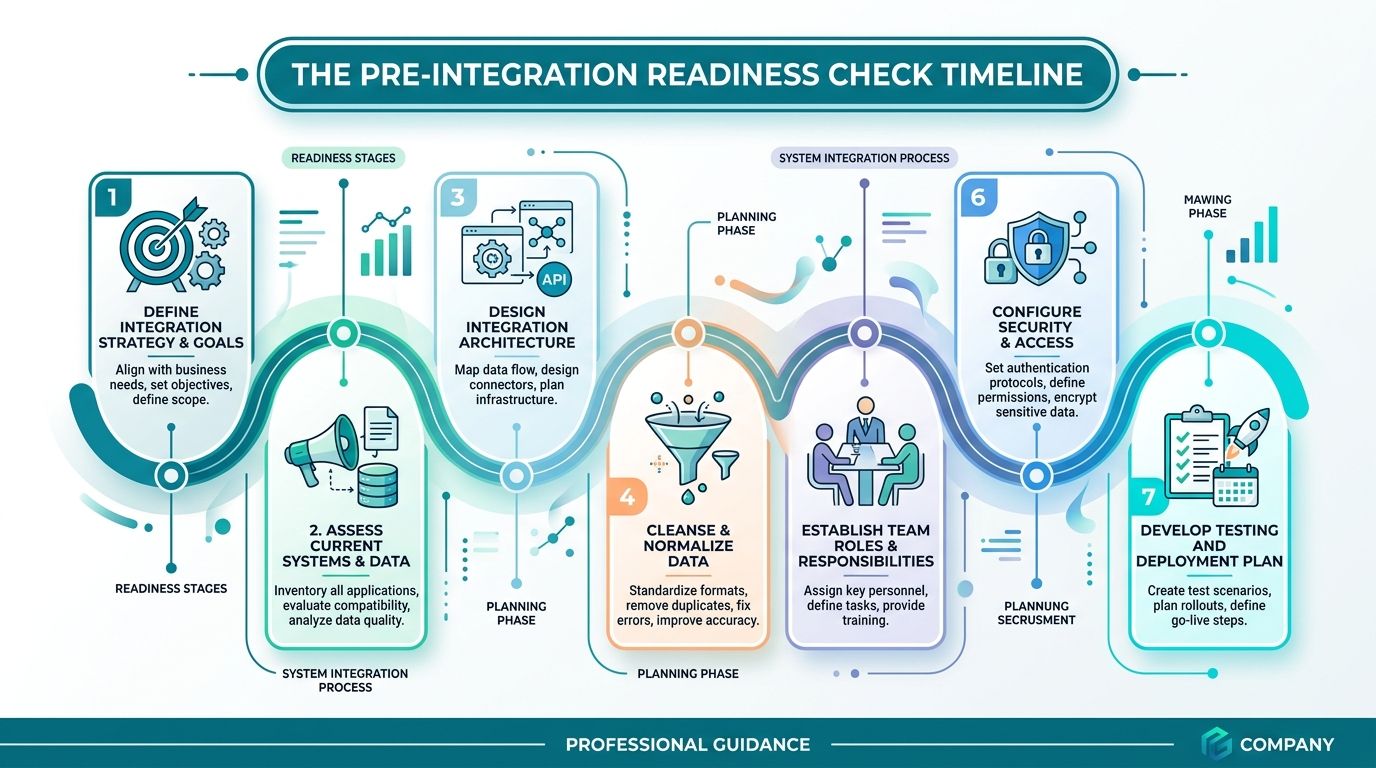
The Pre-Integration Readiness Check
A production agent shouldn't start with architecture diagrams. It should start with a readiness check that eliminates bad candidates early.
The best use cases are narrow, repetitive, high-friction tasks where a person currently has to gather information from multiple systems, apply a known policy, and then take a bounded action. That's the pattern. Not every workflow fits it, and trying to force a poor fit is one of the fastest ways to burn time.
Pick work that is repetitive and bounded
Strong candidates for ai agent integration usually share four traits:
- They happen often enough to matter: If a task is rare, the operational learning loop is too slow.
- The inputs are accessible: The agent can retrieve the right documents, fields, or events without heroic custom work.
- The output can be judged: A human can say whether the task was completed correctly, quickly, and safely.
- The blast radius is limited: If the agent makes a mistake, the error is reversible and doesn't create disproportionate risk.
Bad candidates look different. They involve long, open-ended chains of reasoning, vague success criteria, or too many hidden dependencies on human judgment. Those workflows can still become automatable over time, but they aren't where you start.
Set the KPI before you write the workflow
The most useful readiness exercise is brutally simple. Write down the business problem in one sentence, define the task boundary, and decide what success will mean operationally.
A practical pilot should measure:
- Task success rate: Did the agent finish the job correctly?
- Response time: Did cycle time improve or stay acceptable?
- Cost per task or lead: Is the workflow economically sensible?
- User satisfaction: Do operators trust the result enough to keep using it?
This isn't optional discipline. It's what prevents teams from celebrating a clever prototype that creates no durable business value.
One implementation guide makes the point clearly. A practical enterprise method is to start with a narrow, measurable pilot and test the agent on high-value, repeatable tasks. The same source notes that 68% of production agents execute 10 or fewer steps before needing human intervention, which is a strong signal to decompose longer workflows into shorter sub-tasks with defined handoff points, as discussed in this integration guidance on phased pilots.
Practical rule: If a workflow needs many dependent steps, split it into smaller jobs with checkpoints. Don't ask one agent to carry the entire process end to end on day one.
Run the first pilot in a contained environment
Strategic deployment typically starts in a single department, queue, or workflow lane. A sandbox is useful for technical testing, but a limited live environment is where valuable lessons appear. That's where you learn whether the source systems are stable, whether operators trust the outputs, and whether your exception paths are realistic.
A useful readiness checklist should answer questions like these:
- What exact task is the agent allowed to do?
- Which systems does it need to read from?
- Which systems can it write to, if any?
- When must a human approve or review?
- What logs will prove what happened?
- Who owns the KPI after launch?
Teams that want a structured version of that process often start with an AI readiness checklist for enterprise use cases, then refine it around one workflow instead of trying to score the whole company at once.
Designing Your Agent's Technical Architecture
Architecture choices decide whether the agent will remain maintainable six months from now. In this context, many teams either overbuild too early or choose the fastest possible path and create a brittle mess.
A useful way to think about ai agent integration is to separate the agent's reasoning layer from the execution layer. The model can decide what to do next, but production systems still need deterministic controls around tool access, retries, state, logging, and approvals. If you blur those layers together, debugging becomes painful.
Choose the right integration pattern
Different workflows need different integration patterns. There isn't a universal winner.
| Pattern | Best For | Complexity | Key Benefit |
|---|---|---|---|
| Direct API calls | Narrow workflows, fast pilots, few systems | Low | Quickest path to a usable first deployment |
| Event-driven architecture | Work triggered by system events, queues, or status changes | Medium | Better reliability and cleaner scaling across asynchronous workflows |
| Orchestration frameworks | Multi-step workflows with approvals, state, and multiple tools | High | Strong control over execution, retries, and observability |
Direct API calls are right when the workflow is tightly bounded. A support triage agent that reads a ticket, checks an account record, and drafts the next action often fits this model. It's fast to ship and easy to reason about. The downside is that complexity grows quickly once you add branching logic, retries, or multi-system dependencies.
Event-driven architecture works better when the workflow is triggered by something happening elsewhere. A new claim enters the queue. A customer document is uploaded. A billing anomaly appears. In those cases, queues, webhooks, and event buses usually create a cleaner contract than direct synchronous calls. They also reduce the chance that one downstream failure blocks the entire process.
Orchestration frameworks make sense when the agent needs state, guardrails, multiple tools, and explicit handoffs. In these situations, teams often adopt workflow engines, agent frameworks, or iPaaS-style orchestration to manage execution outside the model itself. It's more work up front, but it usually pays off for regulated or multi-team processes.
For teams mapping those trade-offs into broader system design, an API architecture guide for connected AI systems is a useful companion because the underlying design constraints are the same: contracts, reliability, and failure isolation matter more than elegance.
Don't confuse RAG with integration
A common mistake is to treat retrieval-augmented generation as the integration strategy. It isn't. RAG helps the model access the right knowledge at inference time. That can be valuable for policy lookup, document grounding, or internal knowledge access. But RAG alone doesn't solve execution, permissions, write actions, or process control.
Use RAG when the problem is mainly about context retrieval. For example, an internal agent may need to answer using current SOPs, contracts, or support articles. That's a retrieval problem.
Use stronger workflow engineering when the problem is about taking action. If the agent needs to update a CRM record, route a case, trigger a refund review, or create a task in an external platform, you need tool reliability and governance more than richer retrieval.
Fine-tuning or custom model training enters the picture later, and only when the workflow consistently fails because of domain-specific behavior that prompt design, retrieval, and process constraints can't fix. Organizations frequently pursue model customization too early, when the actual problem is poor workflow decomposition or weak data contracts.
Design for failures before you design for autonomy
A production architecture should answer these questions before release:
- What happens if a tool call times out?
- What happens if the upstream data is incomplete?
- What happens if the model selects the wrong next action?
- What happens if the target system changes its interface?
- What happens if confidence is ambiguous?
Those answers usually lead to a better design. You add checkpoints. You narrow tool permissions. You persist intermediate state. You route uncertain cases to humans instead of forcing the model to improvise.
The most stable agent systems aren't the ones with the longest action chains. They're the ones with the clearest boundaries between what the model may decide and what the system must enforce.
There's also a practical tooling decision. Some teams should build in-house. Others should use an integration platform, workflow engine, or managed orchestration layer. The right choice depends less on model sophistication and more on your internal tolerance for operating connectors, authentication, logs, and policy enforcement over time. One factual option in this market is AmasaTech, which states that its agentic AI services include an integration layer connecting business systems, repositories, event streams, and internal services through governed APIs. That kind of setup is useful when the problem is operational integration rather than model novelty.
Securing Agents and Ensuring Compliance
Most failed enterprise agent projects don't collapse at the demo stage. They stall when security, legal, or compliance teams ask a straightforward question: what exactly is this agent allowed to access and change?
That's where generic ai agent integration advice usually becomes shallow. It explains tool-calling, memory, and orchestration, then assumes your existing identity and access model will somehow stretch to cover autonomous actions across multiple applications. In practice, that assumption breaks quickly.

Traditional IAM is not enough
The core problem is simple. Human identity models were designed for employees logging into applications directly. Agents behave differently. They may retrieve information from one system, evaluate it against policy from another, then take action in a third. Shared service accounts and broad API keys are a tempting shortcut, but they create exactly the kind of privilege sprawl enterprises should avoid.
A recent Harvard Data Science Review piece on AI agents and leadership challenges highlights this gap, noting that identity and governance are now central concerns. The practical implication is that traditional IAM breaks down because agents need blended identities, just-in-time privileges, and scoped access instead of standing shared credentials.
Build access around scope, time, and auditability
A secure agent design usually follows a few rules.
- Scope each agent to one role and one workflow family: A claims review agent shouldn't also have permissions to alter customer billing records.
- Grant privileges just in time: The agent should receive only the minimum permissions needed for the current step, then lose them after execution.
- Separate read and write paths: Many workflows should start with read-heavy access and require explicit approval before any write action.
- Log every meaningful action: You need a durable trail of prompts, tool calls, retrieved context, decisions, and outputs.
- Design rollback paths: If the agent creates a record, routes a case, or triggers a downstream action, your team must know how to reverse it.
This is the practical shift. The key question is no longer whether the agent can reason. It's whether you can let it act safely inside ERP, CRM, ticketing, and data platforms without creating governance debt.
If your security model treats the agent like a human user with a broad role, you're not deploying an autonomous workflow. You're creating a privileged automation risk.
Compliance needs workflow controls, not generic policy text
Regulated environments need more than a policy page. They need technical controls that enforce policy at runtime.
That often means:
- Approval gates for sensitive actions
- Data minimization before the model sees context
- Policy checks before outbound actions
- Immutable audit trails for reviews and incidents
- Environment separation between pilot and production
For startups and growth-stage teams in regulated sectors, there's a legal design component too. Product, security, and counsel need a shared model for data handling, responsibility, and user disclosure. A practical reference point is AI legal consulting for startups, especially when the deployment touches customer data, regulated decisions, or externally visible automations.
Testing and Validating Agent Performance
Many engineering groups still test agents as if they were prototypes. They run a few scenarios, watch the outputs, and decide whether the experience “feels good.” That's not enough for production.
You need to test the agent at two levels. First, can it perform the narrow skills required in the workflow? Second, can the full system hold up when real tools, changing inputs, and failures show up together?

Measure tool use, not just final answers
A strong validation process isolates agent skills. Don't only ask whether the final output looked acceptable. Check whether the agent selected the right tool, called it with the right arguments, handled the response correctly, and recovered when the tool failed.
Useful operational metrics include:
- Tool selection accuracy
- Tool success rate
- Tool-call latency
- Tool efficiency
- Error frequency and recovery path
Integration quality often depends less on model eloquence and more on execution reliability. As covered in AIMultiple's review of AI agent performance and observability, one benchmark reports GPT-5.2 at 94.5% on tool-calling, yet 74% of organizations still rely primarily on human evaluation. That gap is a warning. Manual review is useful, but it doesn't scale as your workflow count grows.
Combine automated tests with human review
Good testing programs use both.
Automated tests should cover known cases, expected tool sequences, argument formatting, policy checks, and failure recovery. These are the tests you run on every change.
Human review should focus on ambiguity. Reviewers should inspect edge cases, unsafe behavior, poor handoff decisions, and situations where the agent looked plausible but made the wrong operational choice.
A simple testing stack often includes:
| Test layer | What it checks | Why it matters |
|---|---|---|
| Skill tests | Tool choice, extraction, classification | Catches narrow failures early |
| Workflow tests | End-to-end completion across systems | Verifies the agent can finish the real job |
| Failure tests | API outages, missing data, bad responses | Proves recovery design works |
Teams that already operate cloud test pipelines can adapt that discipline to agent workflows. A practical starting point is cloud testing practices for production systems, especially for repeatable validation and release gating.
Don't trust a passing demo. Trust repeatable logs, explicit thresholds, and failure tests that show how the agent behaves when the environment stops cooperating.
Deployment, Scaling, and Continuous Monitoring
Go-live is where many teams finally realize that ai agent integration is an operations problem. The agent may work in staging, but production introduces demand spikes, API variability, queue buildup, and subtle behavior drift that doesn't announce itself with a crash.
A safer release pattern is to treat agent launches like any other business-critical system change. Start with a limited release cohort, route only a subset of traffic or tasks to the new agent, and keep a fast rollback path. Some teams use canary-style rollout. Others prefer blue-green style releases or queue-level routing between old and new workflows. The exact pattern matters less than the principle: don't expose the whole operation to an unproven behavior change.
Scale the workflow, not just the model
A lot of teams focus on model throughput first. In practice, bottlenecks often show up elsewhere. External APIs throttle. Internal systems return incomplete records. Background jobs pile up. Human approval queues become the new constraint.
The right scaling plan usually addresses several layers:
- Concurrency control: Prevent too many agents from hitting the same downstream system at once.
- Queue management: Let work buffer safely instead of failing under load.
- Idempotent actions: Make sure retries don't create duplicate records or repeated actions.
- State management: Persist intermediate steps so the workflow can resume cleanly after interruptions.
- Cost discipline: Route only the work that benefits from agent reasoning. Deterministic steps should stay deterministic.
Monitoring has to detect decay, not just downtime
Traditional uptime monitoring won't catch the most common production failures. The service can be technically available while the agent's usefulness degrades.
Production monitoring should watch for:
- Shifts in task success rate
- Longer completion times
- Rising human handoff frequency
- More tool failures or retries
- Behavior drift after upstream system changes
This is why observability needs to be built into the workflow itself. You want traces for tool calls, intermediate decisions, approval events, and final outcomes. Without that, you won't know whether the problem came from the model, the orchestration layer, the source system, or a policy guardrail that fired too often.
Keep a human operations loop in place
Even mature agent systems need owners. Someone has to review error clusters, update prompts or policies, adjust workflow decomposition, and retire low-value automations that looked promising but don't hold up in practice.
The teams that scale agents successfully usually run them like product surfaces with SRE discipline. They don't assume stability. They monitor for it, test for it, and re-earn it after every release.
Measuring the True Business Impact of Your AI Agent
The hardest truth about ai agent integration is that technical sophistication doesn't matter if the workflow doesn't move a business KPI. A beautifully orchestrated agent that nobody trusts, or that saves no meaningful time, is still a failed deployment.
The useful scorecard is usually small. Did cycle time drop? Did throughput improve? Did exception handling get cleaner? Did the team reduce manual work in a part of the business that constrains growth? Those are the questions that survive after the launch excitement fades.
The best opportunities are vertical and workflow-specific
The strongest production outcomes usually don't come from generic “productivity agents.” They come from domain workflows with clear rules, clear systems, and clear economic value.
That's where the current market is heading. As described in NFX's analysis of AI agent marketplaces and vertical AI employees, the opportunity is splitting between horizontal agent BPO models and vertical specialist agents, and roughly half of agentic AI initiatives remain in pilot because teams haven't solved security, compliance, and scalability inside specific workflows.
That pattern matches what operators see on the ground. Insurance teams need claims support inside strict review paths. Fintech teams need compliance checks with auditable decisions. Legal teams need document workflows with source control and review gates. Manufacturing teams need issue routing tied to operational systems, not a standalone chat surface.
What lasting value actually looks like
When an agent creates durable value, a few things are true at the same time:
- The workflow is narrow enough to govern
- The architecture is stable enough to operate
- The security model is strict enough to approve
- The KPI is concrete enough to defend
That combination matters more than any single model choice.
The companies that get past pilot mode usually stop talking about “using AI” in the abstract. They talk about one operational workflow, one owner, one measurable baseline, and one rollout plan that can expand once the first lane proves itself. That's the right level of ambition. Specific enough to ship. Controlled enough to trust. Valuable enough to keep funding.
If you're evaluating AmasaTech for ai agent integration, the practical fit is outcome-driven deployment. That means starting with an AI audit, selecting a narrow workflow, tying the rollout to KPIs like throughput, cost, accuracy, or revenue impact, and building the governance and monitoring layer needed for production use. That approach tends to work better than broad “AI transformation” programs because it gives operators a contained path from pilot to scale.