
AI Workflow Enterprise Model Deployment: 2026 Strategy
The most popular advice on AI deployment is still wrong. It says the hard part is training the model, then treats production as an implementation detail.
In enterprise work, deployment is the product. A model that scores well in a notebook but doesn't fit approvals, handoffs, latency targets, audit requirements, or unit economics isn't an asset. It's an expensive prototype.
That gap is why ai workflow enterprise model deployment has to be run as a business system, not a data science milestone. The teams that get value don't start with model choice. They start with workflow fit, KPI ownership, compliance boundaries, operating cost, rollback design, and a clear path from pilot to production.
Why Most Enterprise AI Models Fail in Production
The failure pattern usually starts with a false assumption: if the model is good, adoption will follow. In practice, most enterprise failures happen long before users reject the output. They happen when the system can't survive real workflows.
The production gap is bigger than many executives expect. Research on enterprise AI deployment challenges reports that 46% of AI models never reach production, 40% of those that do degrade within the same year, and 95% of enterprise AI deployments fail to achieve their intended outcomes. Those numbers don't describe a modeling problem alone. They describe a delivery problem.
The actual causes are operational
Most broken deployments share a few traits:
- Weak workflow integration: Teams bolt a model onto the edge of the business instead of embedding it into the system where work already happens.
- No lifecycle ownership: The project has builders, but no operator who owns monitoring, retraining triggers, rollback, and business review.
- Accuracy without economics: Teams optimize model metrics and ignore handling cost, review burden, queue time, and user adoption friction.
- Poor system memory and context handling: Custom tools often fail because they can't retain needed context across steps or connect reliably to source systems.
A lot of AI programs also skip readiness discipline. They move from demo to procurement to pilot without a serious review of data quality, decision rights, and operational risk. If you're about to deploy into a live business process, use an AI readiness checklist for enterprise teams before choosing architecture.
Most enterprise AI failures don't come from a model being unusable. They come from the surrounding system being unfinished.
What works better than the build first mindset
The strongest enterprise deployments start narrow. They target one high-value workflow, define the business owner, map upstream and downstream dependencies, and decide what happens when the model is wrong.
That sounds less exciting than launching a broad AI initiative. It's also why some teams get durable results while others keep recycling pilots.
A practical rule is simple:
- Pick a workflow where output leads to a real action.
- Define the human review path before launch.
- Decide what data must be captured in production.
- Treat deployment as an ongoing operating model, not a one-time release.
If you get those four things right, the model has a chance to create value. If you don't, better training won't save the program.
Laying the Groundwork for AI Deployment Success
Enterprise deployment starts before any model training run. It starts with a decision: are you building a technical demo, or a business capability that can survive procurement, audit, handoffs, and scaling pressure?
The groundwork has three parts. Readiness, governance, and KPI design.

Start with a readiness audit
A readiness audit should be blunt. If the source data is fragmented, labels are inconsistent, or the target workflow is still changing every month, deployment will absorb that instability.
A useful audit asks:
- Where does the decision happen: Inside a CRM, claims platform, underwriting queue, support desk, or document review workflow?
- Who owns the process outcome: Not the model. The actual business result.
- What data is available at decision time: Not what exists somewhere in the warehouse.
- How will exceptions be handled: Who reviews, overrides, and records edge cases?
- What existing systems must connect: APIs, event streams, storage layers, logging, and identity systems.
For teams early in this process, a structured guide on preparing an organization for AI adoption is often more valuable than another model comparison.
Put governance on paper early
Governance is where many founders and ops leaders lose momentum because they wait too long. They assume governance is a large-enterprise concern, then discover late that no one has authority over model approval, retraining, access control, or audit evidence.
Use a lightweight ownership model with named roles:
| Decision area | Who should own it |
|---|---|
| Business KPI approval | Process owner |
| Model quality sign-off | ML lead or applied AI lead |
| Data access and retention | Security and data governance owner |
| Production release approval | Platform or engineering owner |
| Incident response and rollback | Operations and engineering together |
This doesn't need bureaucracy. It needs clarity.
Compliance and explainability aren't add-ons
For regulated sectors, explainability and traceability must be designed from the start. Coverage of 2025 EU AI Act enforcement data states that 45% of deployments fail audits due to untraceable agentic AI decisions. If your system influences approvals, risk scoring, compliance review, or customer-facing decisions, that should change your architecture choices immediately.
That means capturing:
- Decision lineage: Which model version ran, on what input, under which policy.
- Human intervention points: When an operator overrode the output.
- Prompt and retrieval controls: For generative systems, what context was used and how it was sourced.
- Audit logs: Enough detail for internal review and external examination.
Practical rule: If you can't explain how a production decision was formed, you haven't finished deployment.
Define KPIs that finance and operations both accept
Accuracy is necessary. It isn't enough.
The best deployment KPIs connect model behavior to business movement. Depending on the workflow, that might mean reduced manual review, faster decision turnaround, higher document throughput, fewer escalations, or lower exception handling cost.
A strong KPI set usually includes three layers:
- Model metrics such as precision, recall, or task-specific quality checks.
- System metrics such as latency, failure rate, and queue health.
- Business metrics such as throughput, unit cost, and conversion or retention effects.
When teams skip the third layer, they end up defending a model nobody can justify financially.
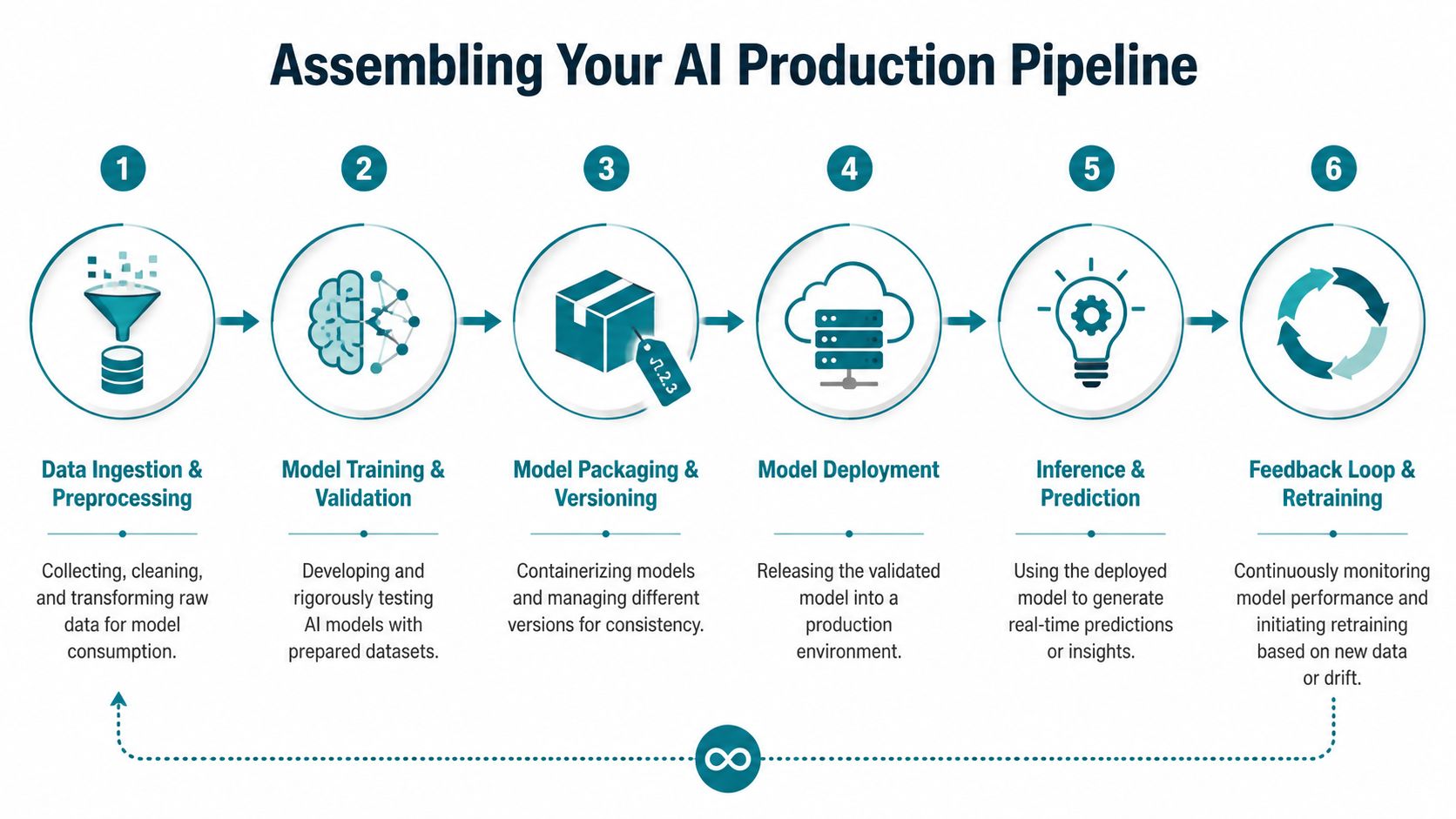
Assembling Your AI Production Pipeline
A production pipeline isn't just a path from training to serving. It's the control system that keeps an enterprise model reproducible, testable, secure, and maintainable after the first release.
The technical pieces matter, but each one should solve a business problem. Reproducibility lowers incident time. Versioning improves auditability. Better packaging reduces deployment risk. A good feature layer cuts rework and limits drift.
The feature store is less glamorous than the model and often more important
One of the most underfunded parts of enterprise ML is the feature store. Teams repeatedly rebuild logic for the same variables across notebooks, batch jobs, and serving code. That creates silent mismatch between training and production.
A centralized feature approach solves three problems at once:
- Consistency: The same feature definitions are used in training and inference.
- Traceability: Teams can version transformations and understand when changes happened.
- Speed: New models reuse existing feature work instead of rebuilding from scratch.
Without this layer, drift doesn't just happen in the model. It happens in the input logic, which is harder to detect and harder to explain after the fact.
Test the workflow, not just the model
Many teams test model quality. Fewer test the full workflow under realistic load and edge conditions.
For enterprise deployment, use multi-stage testing that includes:
- Unit testing: Validate transformation logic, schema checks, business rules, and helper functions.
- Integration testing: Confirm the model can interact correctly with APIs, queues, databases, document stores, and downstream applications.
- Performance testing: Measure response behavior under expected operational load.
- Regression testing: Catch breakage when prompts, features, dependencies, or infrastructure change.
- A/B or staged validation: Compare versions in controlled release conditions before broad rollout.
Production deployment guidance from Capella Solutions notes that effective deployment uses multi-stage testing, containerization that reduces image sizes by 40 to 60% and vulnerabilities by 50%, and targets performance metrics such as inference latency under 100ms and throughput greater than 1,000 predictions per second.
Those metrics won't apply to every workflow in the same way, but the principle does. Define service levels before release, not after complaints start.
Package the model like software that has to live with other software
Containerization matters because enterprise environments are messy. Local packages differ from staging. Drivers change. Security scans fail. A model that works only in a single environment isn't deployable.
Use Docker or another container standard to lock runtime dependencies, then keep images lean. Lightweight base images and multi-stage builds make releases easier to scan, promote, and roll back.
This also improves collaboration. Platform teams can treat the model service as a known artifact instead of a custom environment that only one ML engineer understands.
For organizations connecting model services into broader platforms, a strong API architecture for AI systems is often what separates a reliable deployment from a brittle one.
Build infrastructure for repeatability, not heroics
Kubernetes and Terraform are useful in enterprise AI because they make environments reproducible. Kubernetes gives you orchestration, health checks, scaling controls, and service management. Terraform gives you repeatable infrastructure definitions across environments.
That doesn't mean every company needs a giant platform team. It means the deployment should be rebuildable without tribal knowledge.
If your production model depends on one engineer remembering a manual sequence of steps, the deployment isn't production-ready yet.
A healthy pipeline has a simple property. New versions move through it the same way every time. That lowers risk, speeds approvals, and gives ops teams confidence that AI isn't bypassing engineering discipline.
Automating Deployment with MLOps and Continuous Monitoring
A deployed model starts decaying the moment production traffic touches it. User behavior shifts, source systems change, documents arrive in new formats, and business rules evolve. That's why static deployment pipelines don't last.
The right operating model combines CI/CD, GitOps, observability, and automated retraining into one managed loop.
GitOps makes AI releases auditable and reversible
In traditional software, CI/CD already gives teams faster and safer releases. In machine learning, the same logic applies, but with more moving parts. Data schema checks, model validation, feature compatibility, and environment consistency all need to be enforced before promotion.
A unified GitOps workflow using tools like Argo CD, Flux, or Jenkins X gives teams a stable release pattern. Firefly's enterprise AI workflow automation guidance says this approach can achieve about 40% faster time-to-market, automate about 50% of deployment steps, improve ROI visibility by 2 to 3x when models are aligned to business KPIs, and reduce rollback time by 70%.
The operational value is straightforward:
| Capability | Why it matters in production |
|---|---|
| Version-controlled environments | Fewer release surprises |
| Automated promotion rules | Less manual gatekeeping |
| Canary or shadow support | Safer validation in live conditions |
| Fast rollback | Lower incident exposure |
For teams balancing capability against cost, budget-conscious AI orchestration options become important. The best setup isn't the most complex one. It's the one your team can operate.
Monitor technical signals and business outcomes together
Monitoring fails when teams only watch infrastructure. CPU, memory, latency, and error rates matter, but they're not enough.
A production AI dashboard should combine:
- Technical health: latency, throughput, timeouts, queue depth, container restarts
- Model quality: confidence distribution, drift indicators, task-specific error patterns
- Business impact: approval cycle time, review load, escalation rate, document completion rate, cost per decision
That mixed view changes decision-making. A model might look technically healthy while it increases manual review without warning. Or it might consume more compute than expected while adding little process value.
The useful question isn't "Is the model running?" It's "Is the workflow performing better than before?"
Drift response should be designed before drift appears
Continuous monitoring only matters if it triggers action. The strongest production systems define thresholds and responses ahead of time.
A practical response design often looks like this:
- Detect deviation through schema drift, quality checks, or business KPI movement.
- Route alerts to the owner who can act, not just a generic engineering channel.
- Run shadow or comparison evaluation against a candidate retrained model.
- Promote or roll back based on pre-agreed acceptance rules.
- Capture evidence for audit and post-incident review.
For narrow, high-value workflows, automated retraining can work well when upstream data quality is strong and acceptance criteria are strict. In more regulated settings, retraining may need approval checkpoints before promotion.
Automation only works when ownership is explicit
A lot of teams install MLOps tooling and assume they've solved operations. They haven't. Tooling doesn't replace ownership.
Someone still has to own model health, business KPI review, release policy, and retraining approval. The more automated the pipeline becomes, the more important that ownership gets because failures move faster too.
Good MLOps doesn't remove humans from the loop. It places humans at the right control points and removes the repetitive work that causes inconsistency.
Strategic Rollouts and Continuous Business Optimization
A release strategy should match the cost of being wrong. That's the simplest way to choose between rollout patterns.
Teams often spend months building a strong model, then push it live with a weak go-live plan. That throws away much of the discipline built earlier. Enterprise rollout should reduce operational risk and expose financial truth quickly.

Compare rollout methods by risk and learning speed
Different deployment patterns solve different problems.
| Rollout method | Best use | Main advantage | Main trade-off |
|---|---|---|---|
| Shadow deployment | High-risk workflows where you want live validation without acting on outputs | Safe observation in real conditions | No immediate operational gain |
| Canary release | Workflows where a small share of traffic can test the new version | Limits blast radius while generating real usage data | Requires tighter monitoring and traffic control |
| Blue-green deployment | Systems that need clear cutover and quick fallback | Clean release switch and simple rollback path | Can increase environment overhead |
| Full replacement | Low-risk internal workflows with mature controls | Fastest to release | Highest exposure if assumptions are wrong |
Shadow mode is especially useful in regulated or revenue-sensitive processes. It lets teams compare predicted outcomes, latency, and exception rates before the model gains decision authority.
Track value after go-live or finance will question the program
Post-launch optimization should be run like portfolio management. Every production workflow needs a scorecard that business leaders can read without translation.
Useful review questions include:
- Did cycle time improve in the target workflow?
- Did manual review volume shrink or just shift elsewhere?
- Did the model create rework for another team?
- Are infrastructure costs staying within the expected operating range?
- Is the output quality stable enough to expand usage?
If those answers aren't visible, the deployment may still be technically healthy while commercially weak.
Total cost of ownership changes architecture decisions
Many AI programs struggle at this stage. Leaders approve the pilot based on obvious costs, then production introduces new ones. GPU consumption rises. Drift remediation takes staff time. Vendors become difficult to replace once prompts, retrieval logic, and model serving are tightly coupled.
A 2025 Gartner report cited in Coursera's deployment materials found that 68% of enterprise AI projects exceed budgets by 40 to 60%, driven by unaccounted GPU costs, data drift remediation, and vendor lock-in.
That should affect how you design from day one.
- Choose modular components: So you can replace parts of the stack without rewriting the workflow.
- Budget for monitoring and retraining: Production cost isn't just serving cost.
- Review cost per business outcome: A model can be accurate and still uneconomic.
- Prefer phased releases: They expose true operating cost before full-scale commitment.
A deployment can hit its technical target and still fail financially. Enterprise teams need both views on the same dashboard.
Your Phased Playbook from Quick Wins to Scaled AI
Most organizations shouldn't start with a broad enterprise platform build. They should start with a controlled workflow that produces a visible business result, then scale the operating model that made it work.
That matters because adoption is already widespread while scaling remains uneven. Arcade's 2026 workflow automation analysis reports that 88% of enterprises use AI, only 33% scale programs beyond initial pilots, and successful workflow automation delivers an average ROI of 240% within 12 months. The opportunity is real. The path is what trips people up.
Phase one focuses on a narrow quick win
Start with one workflow where the economics are easy to observe. Common candidates include document intake, internal knowledge retrieval, support triage, compliance review assistance, or a bounded chatbot tied to a real operation.
Keep the scope tight. Define the owner, approval path, exception handling, and success metrics before the first deployment.
Phase two standardizes the production system
Once one workflow is producing stable value, build the repeatable layer around it. Within this layer, formalize feature management, testing gates, deployment automation, monitoring, and release policy.
The goal isn't to create a massive platform for its own sake. It's to stop every new AI initiative from reinventing infrastructure, governance, and evaluation rules.
A practical AI adoption roadmap for scaling teams helps connect these early wins to broader operating change.
Phase three expands into deeper AI operations
Only after the first two phases are stable should most firms move into more complex systems such as agentic workflows, custom model programs, multi-model orchestration, and broader process automation.
By then, the organization should already know how to answer the questions that matter:
- Which KPIs justify this deployment
- What is the review and rollback policy
- What does production cost look like
- Who owns model performance after launch
That is what makes scaled AI possible. Not ambition alone, and not another pilot.
If you're evaluating an enterprise AI initiative and need a deployment plan tied to business outcomes, AmasaTech helps teams move from readiness audit to production rollout with an outcome-as-a-service model. That includes quick-win workflows, KPI-based delivery, secure deployment design, and long-term scaling for custom models, RAG systems, and AI agents.