
AI Agent Development Cost: A 2026 Budget Guide
A VP approves an AI agent budget after seeing a polished demo. Two weeks later, the delivery team asks about CRM access, document quality, approval rules, security review, and who owns exceptions when the agent makes the wrong call. The estimate changes fast. That gap is where many first budgets go off track.
The issue is scope definition. “AI agent” can describe a lightweight internal assistant, a support agent with retrieval, a workflow agent tied to Salesforce or HubSpot, or an enterprise system with permissions, audit logs, human review, and monitoring. Those are separate builds with different engineering effort, risk, and operating cost.
A useful ai agent development cost conversation starts with the work required to make the agent dependable in your environment. Model access is only one line item. Budget usually grows around integration work, data preparation, testing, security controls, observability, and the level of autonomy the business wants to allow.
This is also why published price ranges feel so inconsistent. Vendors often quote different endpoints of the same market. A quick pilot can be inexpensive. A production-grade agent that touches core systems and has to perform reliably under real business conditions is a larger investment.
I tell clients to treat the first estimate as a budgeting exercise, not a shopping exercise. The better question is how much capability, reliability, and integration the business needs in phase one, and which parts can wait. That is also where the right delivery partner matters. An offshore team like AmasaTech in India can reduce build cost substantially for enterprise-grade agents, but the savings only hold if the team can handle architecture, QA, security, and integration depth at the same standard you would expect from a senior local consultancy.
Decoding Your First AI Agent Budget
Most first budgets break because the business scopes the aspiration, not the operating reality.
A founder may want an agent that answers questions, updates records, reasons through edge cases, and works across email, Slack, CRM, and internal documents. That sounds like one system. In delivery terms, it often means prompt design, retrieval architecture, data cleanup, integration work, test harnesses, role-based access, monitoring, and change management.
That’s why the market shows both small and large numbers. A simple MVP can be useful, but it won’t include everything a production deployment needs. Altamira’s analysis places basic pilots at $5,000 to $10,000, while production-ready enterprise deployments commonly sit in the $50,000 to $200,000 range, with implementation timelines often stretching across 3 to 6 months.
What buyers usually miss
- You’re not paying only for model access. You’re paying for workflow logic, system behavior, reliability, and business fit.
- Integrations change everything. Connecting an agent to CRM, databases, APIs, and internal tools is where many budgets expand.
- Production costs differ from demo costs. A prototype can look impressive before security, edge cases, and error handling are addressed.
- Operations matter after launch. API fees, platform fees, and maintenance don’t disappear once the first version is live.
Practical rule: If the agent will touch customer data, make decisions inside a business workflow, or trigger downstream actions, budget for a system, not a chatbot.
A good budget isn’t the cheapest quote. It’s the one that reflects the actual work needed to deploy something your team can trust.
The Seven Core Drivers of AI Development Cost
A finance lead approves a modest AI pilot. Six weeks later, the full budget discussion starts because the agent now needs access controls, clean source data, CRM actions, audit logs, and testing against edge cases. That gap explains why generic price ranges are so hard to trust.
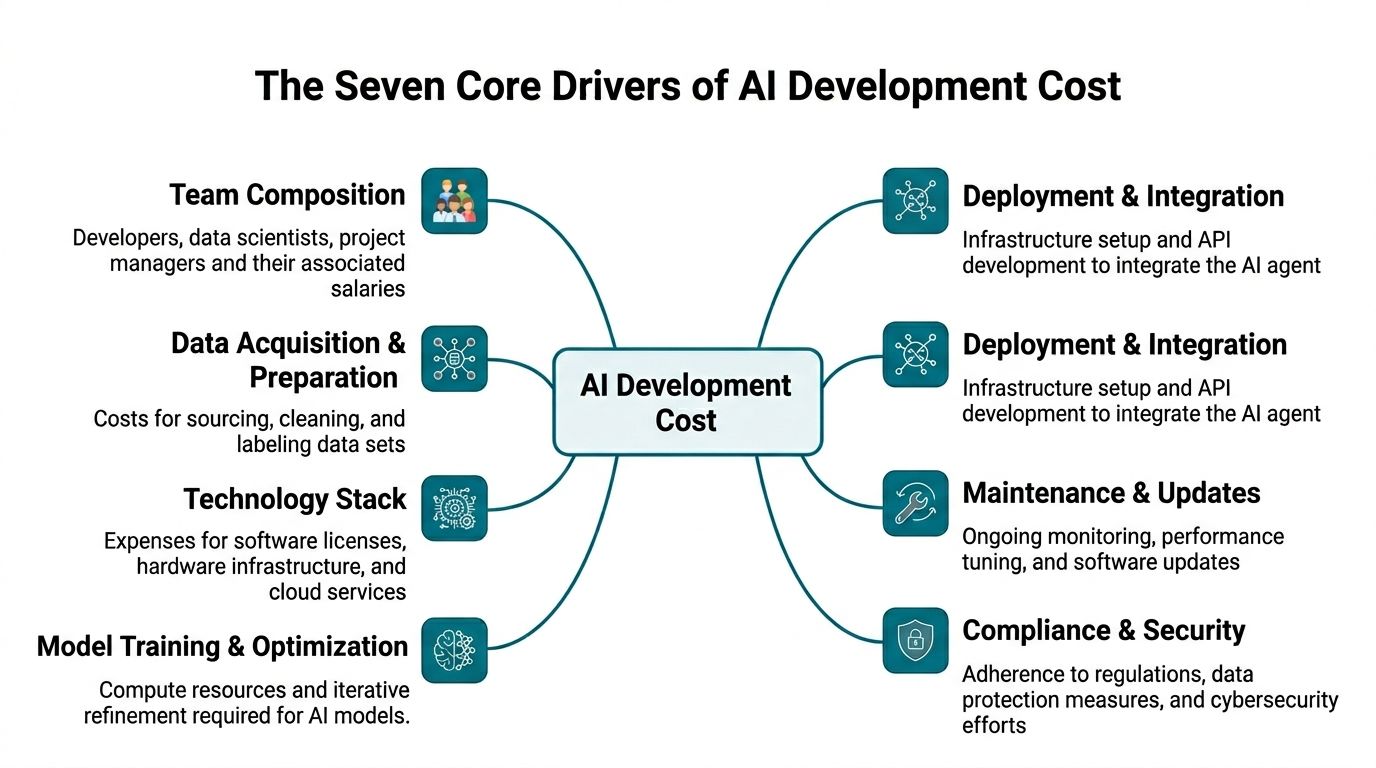
In practice, seven factors drive the final number. They do not act independently. A harder integration choice can increase testing time. Weak source data can force changes to retrieval design. Stricter security requirements can reshape infrastructure, deployment, and support.
Team composition
AI agents are built by teams, not by a single prompt engineer.
A typical delivery team includes application engineers, AI specialists, a product owner, QA, and someone responsible for delivery discipline. For a simple internal assistant, some of those roles can be part-time. For an enterprise agent that takes actions inside core systems, they usually cannot.
This is one reason offshore specialist partners can reduce cost without lowering the standard. A mature team in India, such as AmasaTech, already has the delivery pattern, evaluation process, and integration experience in place. Clients avoid the cost of assembling that capability from scratch, and they usually get to production faster.
Data acquisition and preparation
Data quality shapes both cost and outcome.
If the agent will answer questions from internal documentation, route work, or generate actions from business records, the source material has to be usable. Duplicate files, outdated policies, weak permissions, and missing metadata create rework long before launch. I have seen projects with a reasonable model budget stall because no one accounted for document cleanup and access mapping.
This area also drives a major share of the difference between a low-cost pilot and a production deployment. The pilot may use a curated folder of clean documents. The production version usually has to handle the existing state of enterprise data.
Model choice
Model selection affects more than API pricing.
A general model is often the right starting point because it reduces setup time and lets the team validate the workflow quickly. But if the agent needs consistent output structure, domain-specific reasoning, lower latency, stricter data handling, or lower cost at scale, the architecture changes. That may mean retrieval-augmented generation, fine-tuning, guardrails, model routing, or a mix of providers.
The cheapest model on paper is not always the cheapest system to run. If weaker outputs create more retries, more fallbacks, or more human review, operating cost goes up.
Infrastructure and runtime
Operational cost starts early, not after launch.
Hosting, model APIs, vector databases, logging, monitoring, caching, and background job processing all affect monthly spend. Volume matters, but so does reliability. A low-traffic internal agent can run with a lightweight setup. A customer-facing agent with uptime expectations, usage spikes, and audit requirements needs a different foundation.
The right architecture here is a cost-control decision. Overbuilding wastes budget. Underbuilding creates outages, slow responses, and expensive fixes later.
Deployment and integration
Integration work is where many estimates break.
Connecting an agent to Salesforce, HubSpot, SAP, Slack, internal databases, identity systems, or custom APIs is rarely plug-and-play. Each system brings authentication rules, field mapping, failure handling, rate limits, and permissions logic. If the agent can trigger actions, the review and rollback paths also need to be defined.
This is also where orchestration choices matter. Teams that want a clearer view of where these costs rise should review this guide on ways to save on AI orchestration services.
Testing and validation
Agent testing is broader than standard software QA.
The team has to test prompts, retrieval quality, tool use, fallback behavior, response structure, and failure cases. Then it has to repeat that process as models, prompts, and source data change. A demo may succeed with ten handpicked examples. Production requires confidence across hundreds of messy, real-world scenarios.
This work takes time. It also protects the budget, because finding these failures after release is far more expensive.
Compliance and security
Security requirements change architecture from day one.
If the agent touches customer records, financial data, health information, or internal decision workflows, access control, audit logs, retention rules, approval chains, and environment separation need to be built into the plan. These are not polish items. They are part of the system design.
For enterprise buyers, this is another area where offshore partnership can create real savings. An experienced partner can implement required controls with an established process instead of billing your team to learn them during the project.
AI agent budgets rise for predictable reasons. The cost usually follows scope, integration depth, data condition, and production requirements, not just the model choice.
Budget Examples by Agent Complexity
A client asks for an AI agent and the first budget number they hear is $15,000. Another firm quotes $90,000 for what sounds like the same idea. Both numbers can be reasonable. The difference usually comes down to what the agent must do in production, how many systems it touches, and how much failure will cost the business.
That is why broad market ranges are often frustrating. They flatten very different projects into one headline number. A better way to estimate ai agent development cost is to group the work by delivery complexity, then look at what is being built.
AI Agent Development Cost and Timeline by Complexity
| Complexity Tier | Example Use Case | Estimated Cost Range | Typical Timeline |
|---|---|---|---|
| Simple agent | Internal FAQ bot or rule-based workflow helper | $10,000 to $20,000 | 1 to 2 months |
| Advanced agent | NLP-powered lead qualification or support triage agent | $20,000 to $40,000 | 3 to 6 months |
| Enterprise-grade agent | Autonomous workflow system with deep integrations and advanced reasoning | $40,000 to $100,000+ | 6 to 12 months |
These ranges are useful as planning anchors, not fixed pricing. A narrowly scoped pilot can land below the first tier. A heavily governed enterprise agent can move above the top end quickly if it needs multiple integrations, custom evaluation, and controlled deployment.
Simple agents
Simple agents work best for narrow tasks with limited decision paths. Good examples include internal policy lookup, scripted intake, or a support assistant that answers from approved content and hands off anything ambiguous.
These projects stay affordable because the architecture is lighter. The agent usually uses one main knowledge source, a small toolset, and clear fallback rules. Teams get into trouble when they try to add broad autonomy to a use case that only needs fast retrieval and structured guidance.
For many companies, this is the right starting point.
An offshore delivery partner can make this tier even more cost-efficient. AmasaTech teams in India often build the first production version at a lower blended cost than a local team can justify, while still covering the engineering work that turns a demo into a usable internal tool.
Advanced agents
Advanced agents begin to affect operations directly. They do more than answer questions. They classify requests, retrieve context from business systems, summarize records, recommend actions, and route work based on intent or business rules.
A lead qualification agent is a useful example. It may read inbound messages, pull account context from a CRM, score urgency, draft a response, and push the next step to a sales queue. At this level, the cost is driven less by prompt writing and more by retrieval design, integration reliability, exception handling, and evaluation against real business data.
This is also the tier where offshore partnership creates a strategic advantage, not just a labor-rate advantage. A strong India-based team can supply AI engineering, backend integration, QA, and delivery management in one coordinated unit. That usually lowers total project cost and reduces the delays that happen when companies assemble a cross-functional team from scratch.
Enterprise-grade agents
Enterprise-grade agents support core workflows where mistakes have real operational or financial consequences. They may coordinate across multiple tools, update records, trigger approvals, maintain audit trails, and operate under strict permissions.
The budget rises because the engineering standard rises. These systems need stable orchestration, controlled tool access, monitoring, rollback plans, and evidence that outputs are reliable enough for the process they support. A departmental prototype and an enterprise workflow agent may both use the same model family, but they are not the same build.
I usually advise clients to stop comparing hourly rates in isolation. The better question is whether the partner has already solved production issues around deployment, evaluation, security controls, and integration patterns. Experienced offshore teams can save a large amount here because they bring mature delivery process without the overhead of building that capability internally first.
A practical way to choose the right tier
Use these four questions to place the project in the right budget band:
- Does the agent answer questions only, or does it take actions in other systems?
- Does it rely on one controlled data source, or several live business systems?
- Can a human review outputs before anything important happens?
- Would an error create minor friction, or disrupt revenue, compliance, or customer operations?
If the answers point to a narrow workflow, low-risk outputs, and limited integration, start with a simple build. If the agent will update records, trigger transactions, or operate in a sensitive business process, plan for the advanced or enterprise tier from the start.
The best first budget is the smallest one that can prove value in a real workflow and still meet production standards.
The Build vs Buy vs Partner Decision
A team approves an AI budget, picks a direction, and then loses months in the wrong delivery model. I see this often. The budget was reasonable, but the structure behind it was not.
Build, buy, and partner can all work. The right choice depends on what you need to control, how fast you need results, and whether your internal team is set up to carry delivery risk.
Build internally
Internal build makes sense when AI is already a strategic capability, not just a project. You keep direct control over architecture, security decisions, roadmap, and intellectual property. That matters for companies with a mature engineering organization and a clear plan to support the agent long after launch.
The hidden cost is not only salaries. It is the time spent hiring specialized people, aligning product and engineering ownership, and creating delivery practices for evaluation, release management, and ongoing support. In first-generation agent programs, internal teams often budget for model work and application code, then discover they also need stronger testing discipline, better observability, and more coordination across IT, data, and compliance.
That is a valid investment if you plan to build an internal AI function for the long term.
Buy a platform
Buying a platform is usually the fastest route for narrow, repeatable use cases. If the goal is an internal knowledge assistant or a basic support workflow, a platform can reduce setup time and give the business something usable quickly.
The trade-off shows up later. Prebuilt platforms are designed around common patterns, so they can become expensive or restrictive once the agent needs custom orchestration, deeper system actions, stricter governance, or model flexibility. I often tell clients to budget for the platform fee and the integration layer around it, because many “buy” decisions still turn into partial custom builds.
Buying works best when the workflow is standard and differentiation is low.
Partner with a specialist team
Partnership is often the strongest option for companies that need production quality without building a full AI delivery function from scratch. You get experienced engineering, delivery process, and architectural judgment earlier in the project, which lowers the chance of spending money in the wrong places.
This is also where offshore partnership changes the economics. The headline saving is lower engineering cost, but the more important advantage is access to a team that has already handled enterprise requirements with a leaner cost base. A capable India-based partner such as AmasaTech can often deliver the same class of enterprise agent at a materially lower total project cost than a domestic team, while still covering architecture, integration, testing, and rollout planning.
That difference explains why generic market ranges are so wide. They are mixing very different delivery models.
Where partnership usually wins
- Speed to production: Specialist teams reuse proven patterns instead of inventing them during your project.
- Lower execution risk: The team has already seen failure points in integrations, evaluations, and deployment.
- Better budget control: You pay for an assembled delivery capability instead of building one internally before the project starts.
- A practical handoff path: Good partners document decisions and architecture so your internal team can take over operations later, if that is the plan.
For leadership teams weighing those options, this guide to enterprise AI consulting for complex business deployments helps frame the decision in operational terms, not just procurement terms.
The best choice is usually the one that matches your real operating model. Build if AI capability is a long-term internal asset. Buy if the workflow is standard and low-risk. Partner if you need enterprise-grade delivery, faster time-to-value, and tighter cost control without compromising quality.
How Technology Choices Affect Your Final Cost
A client may ask for “the same AI agent” as a peer company and still end up with a very different budget. The reason is usually not the interface. It is the technical stack underneath: which model you use, how the agent accesses company knowledge, how much customization it needs, and how tightly it must perform in production.

The practical budgeting question is simple. What is the lowest-cost architecture that can meet your accuracy, latency, security, and maintenance requirements?
Off-the-shelf models keep initial costs lower
For many first deployments, a strong hosted model is the right starting point. Teams can use GPT-4o or Claude-class models, add prompt controls, connect business systems, and spend the budget on workflow design rather than model training.
This approach works best when the job depends on general reasoning, language handling, and access to current business context. It starts to break down when the agent must make repeatable judgments in a narrow domain, follow a strict output structure every time, or operate against internal rules that are poorly captured through prompting alone.
The upside is speed. The trade-off is ongoing model usage cost and less control over behavior.
RAG often gives the best cost-to-performance ratio
In enterprise projects, retrieval-augmented generation is often the best middle path. Instead of training the model on company knowledge, the system retrieves relevant policies, documents, product data, or support content at runtime and passes that context into the model.
That usually keeps build costs lower than custom training while improving factual grounding. It also makes updates easier. When a policy changes, the team updates the source content or index instead of retraining the system.
In our experience, many companies avoid unnecessary spend through a specific approach. They do not need a custom model, but rather a well-structured knowledge layer, reliable retrieval, and strong evaluation.
Fine-tuning should be tied to a clear failure pattern
Fine-tuning has a place, but it should solve a specific problem. Good reasons include unstable formatting, repeated errors in a narrow task, or a domain-specific style that prompting and retrieval still cannot enforce consistently.
It also adds work that buyers often underestimate. The team needs clean training data, labeling standards, evaluation criteria, retraining plans, and version control. That raises both the initial budget and the long-term maintenance burden.
As noted earlier from ProductCrafters, medium-complexity agent budgets often rise during model setup, dataset preparation, and fine-tuning work, while a RAG-based approach is often the more cost-efficient option when the goal is domain relevance rather than custom model behavior.
Infrastructure and deployment choices matter too
Model choice gets attention, but infrastructure can change the budget just as much. A cloud-native deployment with managed services is usually faster and cheaper to launch. A private or hybrid setup may be required for security, data residency, or procurement reasons, but it increases engineering scope.
The same applies to observability, testing, and fallback logic. A prototype can skip some of that. A production agent cannot.
What usually makes financial sense
- Use off-the-shelf models when speed matters and the workflow does not require highly specialized behavior.
- Use RAG when the agent must answer from internal documents, policies, or product knowledge that changes over time.
- Use fine-tuning when prompting and retrieval still fail to produce consistent enough outputs for the business process.
- Budget for infrastructure choices early if the agent must run in a private cloud, on-premise environment, or regulated setup.
The lowest quoted build cost is rarely the lowest total cost. Cheap architecture decisions often show up later as poor answer quality, higher review effort, or expensive rework.
Companies that want a clearer architecture recommendation before committing budget usually benefit from reviewing generative AI development services for enterprise use cases, especially when the goal is to balance quality with the cost advantages of an offshore delivery partner in India.
Calculating ROI and Planning for Ongoing Costs
A client approves a pilot at $25,000, sees good early results, and assumes the hard budget work is done. Three months later, key questions show up. How much will usage cost each month? Who reviews failures? What happens when the underlying knowledge base changes, or when the agent needs stronger controls for audit and compliance?
That is why I tell buyers to evaluate AI agents as operating expenses tied to a business process, not as a one-time software purchase. The build cost gets the project started. Total cost of ownership determines whether it remains financially sound.

A practical ROI model starts with three questions.
- How much human work disappears or gets reduced? Look at repetitive triage, document handling, data entry, first-line support, or internal knowledge retrieval.
- How much faster does the workflow move? Faster response times can improve conversion, SLA performance, and customer retention.
- How much human oversight remains? If every output still needs close review, the savings are smaller than the demo suggests.
The strongest business cases usually combine labor savings with speed gains and fewer process errors. A weak business case depends on broad innovation claims and assumes the agent will perform well without ongoing tuning.
I also advise clients to separate direct savings from strategic upside. Direct savings are easier to model. Fewer manual hours, lower handling time, fewer escalations. Strategic upside matters too, but it should sit on top of a grounded operating model, not replace it.
Where ongoing costs usually come from
Post-launch spending tends to come from five areas:
- Inference and API usage: Costs rise with query volume, longer prompts, larger context windows, and heavier model choices.
- Knowledge and prompt maintenance: Internal content changes. Product details change. Policies change. The agent has to keep up.
- Monitoring and evaluation: Production agents need regular testing, failure review, and quality checks against real traffic.
- Human oversight: Some workflows need reviewers for approvals, exception handling, or regulated decisions.
- Security and compliance upkeep: Access controls, audit logs, retention rules, and incident response add work after launch.
Wide market cost ranges become misleading. One company is pricing a low-volume internal assistant. Another is funding a customer-facing agent with integrations, approvals, and compliance controls. Both call it an AI agent. Their operating costs will not look remotely the same.
For enterprise teams, delivery model affects ROI almost as much as architecture. An experienced offshore partner can lower build and maintenance costs materially, but only if the team can still design for production quality, governance, and support. That balance is why many companies look beyond hourly rate comparisons and invest in a clearer enterprise AI adoption strategy before scaling.
A more useful way to estimate ROI
Use a simple annual view:
- Current yearly cost of the workflow
- Expected yearly cost after automation, including model usage, support, and maintenance
- Time-to-value, which matters if the workflow is already expensive or creating backlog
- Risk reduction, if the agent improves consistency or reduces missed steps
Here is the practical test I use. If the agent saves time but creates a new review burden, the ROI is weaker than it first appears. If it cuts manual effort, shortens turnaround, and stays stable with moderate upkeep, the economics usually hold.
This short overview is useful if you’re aligning stakeholders around cost and value expectations:
The best AI budgets fund launch, maintenance, and the operating discipline required to keep the agent useful.
Your Action Plan for a Successful AI Agent Project
Most failed projects don’t fail because AI is too expensive. They fail because the team buys too much ambition too early.
A better path is narrower, faster, and easier to evaluate.
Step 1
Define one business problem with painful repetition. Good candidates include support triage, knowledge retrieval, lead qualification, document review, or internal workflow routing. Weak candidates are broad goals like “use AI across operations.”
Step 2
Scope a pilot that can prove value without pretending to solve everything. Keep the action surface controlled. Decide what the agent should answer, what it may do, what data it can access, and when a human must stay in the loop.

Step 3
Run a discovery process before committing to the full build. Review data quality, integration points, security needs, and success criteria. That step usually prevents expensive misunderstandings later.
A practical starting point is an AI readiness checklist. It helps teams separate a promising use case from a poorly defined one.
What strong buyers do differently
- They budget for production, not just the demo.
- They start with a narrow workflow that has clear operational value.
- They choose architecture based on fit, not hype.
- They treat data and integration work as core scope, not background work.
If you follow that sequence, the question changes from “Can we afford an AI agent?” to “Which version should we build first?”
Frequently Asked Questions
1. How much does ai agent development cost?
The honest answer is that cost follows scope. A narrow internal assistant with limited actions is one budget. An enterprise agent that touches core systems, handles approvals, and runs under security review is a different project entirely.
The useful question is not “what is the average price?” It is “what does this agent need to do in production, and what level of reliability does the business expect?”
2. Why are AI agent cost estimates so different from one vendor to another?
Because quotes often describe different deliverables.
One vendor may price a pilot with basic prompting and a light interface. Another may include integration work, access controls, evaluation, monitoring, fallback logic, and launch support. I see this often in early conversations. Two proposals can look far apart on price while solving very different problems.
3. What is the cost of a custom AI agent for business use?
Custom work costs more because the agent has to fit your workflow, not a generic demo. That usually means business rules, internal data access, system integration, testing against real edge cases, and tighter review before launch.
The trade-off is straightforward. You spend more upfront, but you get an agent that matches how your team operates.
4. How much do enterprise AI agents cost?
Enterprise agents sit at the top of the range because the hard part is rarely the chat interface. The primary cost comes from security, auditability, integration depth, role-based access, failure handling, and operational control after launch.
If the agent can trigger actions inside important systems, expect a larger budget and a longer delivery cycle.
5. What’s cheaper, fine-tuning or RAG?
For many business use cases, RAG is the lower-cost starting point. It lets the agent answer from your documents and knowledge sources without the added work of curating training data and maintaining a custom-tuned model.
Fine-tuning can make sense when the task needs highly consistent behavior, domain-specific formatting, or repeatable outputs that prompting alone does not deliver. The right choice depends on the job, not on trend value.
6. How much can offshore AI development reduce cost?
A well-run offshore partnership can lower build cost in a meaningful way, especially for companies comparing Indian delivery teams with US or Western European pricing. The savings come from rate differences, but that is only part of the story.
The better reason to partner offshore is access to experienced engineering capacity without inflating fixed costs. At AmasaTech, the goal is not cheap output. It is efficient delivery with senior oversight, clear scope control, and production-grade engineering.
7. What are the hidden costs after launch?
Post-launch spend usually surprises teams more than the initial build. Common items include model usage, cloud infrastructure, monitoring, prompt and workflow updates, support, and periodic evaluation as data or policies change.
If the agent works in a regulated or customer-facing workflow, governance and review add more effort. Budget for operations from day one.
8. How long does it take to build an AI agent?
A focused pilot can move quickly. A production system takes longer because integration, testing, permissions, and rollout planning usually take more time than the first demo.
Teams that define one workflow clearly tend to ship faster. Teams that start with “one agent for the whole business” usually spend more time revising scope than building.
9. Is a low-cost MVP a good idea?
Yes, if the MVP is tied to one narrow workflow and one measurable outcome. That is a smart way to test adoption, answer quality, and integration assumptions before committing to a larger rollout.
It becomes a bad investment when the business expects MVP pricing to deliver enterprise reliability.
10. How should I budget for an AI agent project?
Start with the workflow and the business decision the agent will support. Then budget for data preparation, architecture, integration, security review, testing, rollout, and ongoing operations.
The strongest budgets separate phase-one delivery from long-term ownership. That makes trade-offs visible early and prevents a cheap prototype from turning into an expensive rewrite.
If you're evaluating an AI agent initiative and want a realistic view of scope, architecture, and budget, Amasa Tech can help you turn a vague AI idea into a delivery plan your team can execute.