
AI Language Models for Enterprise Productivity: Guide For
Enterprise leaders no longer have the luxury of treating generative AI as a side experiment. Menlo Ventures estimates companies spent $11.5 billion in 2024 and projects $37 billion in 2025, a 3.2× year-over-year increase, with $19 billion of that 2025 total going to the application layer alone, according to Menlo Ventures' 2025 enterprise AI analysis. That's the clearest signal yet that AI language models for enterprise productivity have moved out of the lab and into the operating budget.
What matters now isn't whether your company should use large language models. It's whether you'll use them in ways that improve throughput, reduce rework, and hold up under finance, compliance, and operational scrutiny.
Most articles stop at “AI saves time.” That's not enough for a CEO making a seven-figure platform decision or an ops leader trying to defend budget. The hard questions are more practical. Which model should you use for each workflow. And how do you prove the return without relying on vague claims and demo-friendly anecdotes.
The companies getting real value from AI aren't chasing the biggest model by default. They're choosing the right-sized model, connecting it to the right data, and measuring the result in business terms. If you want a useful benchmark for what scaled transformation looks like across the market, this roundup of companies using AI transformation in 2026 is a good reality check.
From Hype to Reality in Enterprise AI
Enterprise AI has entered a different phase. Budget owners are no longer asking whether language models are interesting. They're asking where they fit in core operations, who owns the rollout, and how quickly the investment can produce defensible results.
That shift changes the conversation. A year ago, many teams were content to run pilots in isolated departments. Today, the stronger organizations are treating AI as operating infrastructure. They're wiring it into support queues, internal search, document workflows, sales research, and compliance-heavy processes where employees lose time moving information from one system to another.
Why this matters to leadership teams
A founder or CEO usually sees the promise first in broad terms. Faster teams. Lower operating drag. Better customer responsiveness. But broad promise is where many initiatives get stuck.
The problem isn't model capability alone. It's implementation discipline.
Practical rule: Don't approve an AI program because the demo was impressive. Approve it because a specific business process has too much manual effort, too much delay, or too much rework.
That means productivity strategy has to start with work design. Which tasks are repetitive but judgment-based. Which ones depend on internal knowledge. Which ones break when answers are slightly wrong. Which ones require human approval even if AI does the draft.
What leaders often get wrong
The first mistake is treating AI as a chatbot project. Chat interfaces are easy to launch, but they're rarely where the biggest productivity gains live.
The second mistake is assuming the largest model is automatically the safest choice. In practice, the best result often comes from matching the model to the job, then surrounding it with retrieval, permissions, and workflow logic.
A third mistake is skipping measurement design until after launch. That's backwards. If you can't define what “better” means before rollout, your team will end up defending impressions instead of outcomes.
A sound enterprise AI plan usually answers four questions early:
- Which workflow breaks first without AI: Pick the process where delays, handoffs, or search friction already hurt the business.
- What does the model need access to: Public knowledge, internal documents, CRM records, policy libraries, or structured systems.
- Where must a human stay in the loop: Approval, exception handling, customer-facing edge cases, or regulated decisions.
- What metric proves value: Throughput, quality, cycle time, rework, or some combination.
That's the practical lens for the rest of this discussion.
Core AI Productivity Use Cases Unlocked
Most leaders understand AI in its simplest form. Someone types a question into ChatGPT or Copilot and gets a draft back. That's useful, but it's only the shallow end of the pool.
The more useful way to think about AI language models for enterprise productivity is as a maturity curve. At the low end, the model helps with isolated tasks. In the middle, it works from company knowledge. At the high end, it starts participating in workflows.
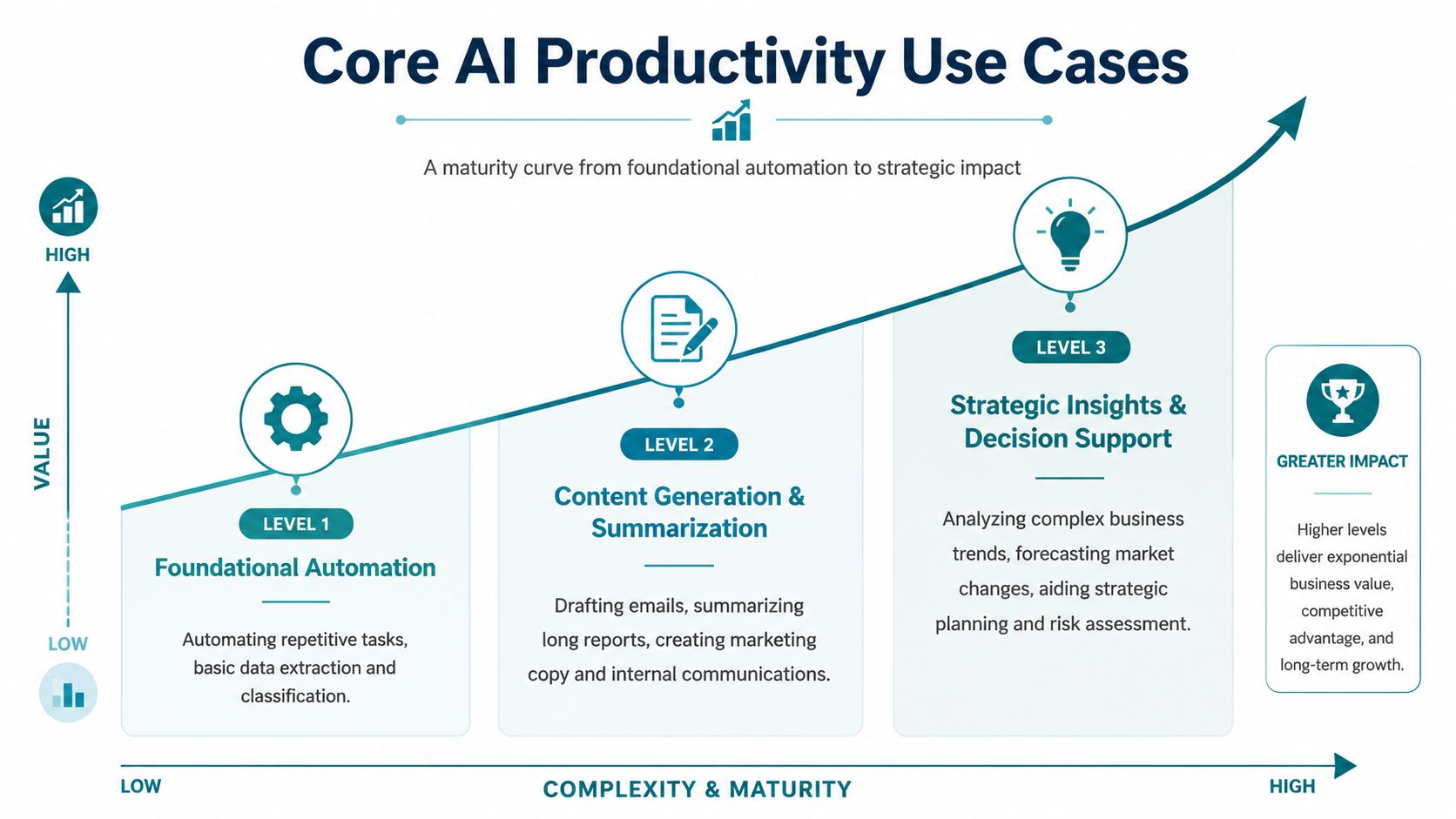
Level one starts with task assistance
This is the most familiar layer. Draft an email. Summarize a meeting. Rewrite support notes. Turn a rough outline into a first-pass proposal.
These use cases matter because they remove low-value writing and synthesis work from busy teams. They're especially useful in functions where people spend too much time turning existing information into usable communication.
Common examples include:
- Customer support drafting: Agents generate reply drafts from a ticket summary.
- HR self-service content: Internal teams draft policy explanations, onboarding notes, or role descriptions.
- Sales prep: Reps summarize account notes, past calls, and meeting prep docs.
- Operations summaries: Managers compress long reports into action items.
This layer is easy to adopt because it doesn't require deep systems integration. It's also the least impactful. It helps individuals, but it doesn't extensively redesign the workflow.
Level two turns AI into a knowledge worker
The jump in value happens when the model can work from your company's own information. That means internal policies, CRM data, product documentation, support history, contracts, SOPs, and shared drives.
At this stage, many teams start to see AI as more than a writing tool. The model becomes a search-and-synthesis layer over fragmented knowledge.
A good example is a support lead asking, “What's our current refund exception policy for enterprise customers in regulated accounts?” A generic model can guess. A grounded system can retrieve the actual policy and answer from it.
Useful patterns at this level include:
- Internal help desks: Employees ask policy and process questions in natural language.
- Sales enablement assistants: Reps retrieve approved positioning, battlecards, and product answers.
- Technical support search: Teams find troubleshooting steps without digging through scattered documentation.
- Document-heavy review work: Staff extract the relevant point from long files before acting.
If you're trying to spot the right opportunities, this guide on how to increase productivity with AI workflow design is worth reading because the value usually comes from where work is handed off, not where prompts are typed.
The fastest enterprise wins usually come from reducing search friction. Employees often know the answer exists. They just can't find it fast enough.
Level three embeds AI in workflows
AI begins to act less like an assistant and more like an operator inside a controlled lane.
Elsewhen notes that productivity gains are strongest when LLMs function as co-pilots that augment users or as autonomous agents that complete end-to-end workflows, and it cites NVIDIA's view that enterprises use these systems for knowledge management, customer inquiry handling, and automatic issue resolution to shorten work stages and improve operational speed in its analysis of enterprise copilots and agents.
That matters because a workflow system can do more than answer. It can retrieve context, choose a next action, call a tool, update a record, and pass the case to a human only when needed.
A practical progression looks like this:
| Use case type | What AI does | Where it helps most |
|---|---|---|
| Chat assistant | Answers or drafts | Individual productivity |
| Co-pilot | Assists inside existing software | Team workflow speed |
| Agent | Executes multi-step actions | Process automation |
Operations leaders should focus their efforts on solutions like these for meaningful productivity gains, not just novelty. A co-pilot inside a support system can summarize the case, recommend the next action, and pre-fill the response. An agent can go further and classify the issue, pull policy context, create a task, and route exceptions.
The maturity curve matters because each level needs different architecture, governance, and ROI logic.
Choosing Your Engine Vendor Models vs Custom Solutions
Most first-time buyers start with the wrong question. They ask, “Which model is best?” The better question is, “Which model is good enough for this workflow at an acceptable cost and risk?”
That shift sounds small, but it changes the whole buying process. Enterprise model selection isn't a beauty contest. It's a portfolio decision across speed, cost, privacy, latency, and control.
When vendor models are the right call
General-purpose vendor APIs are often the fastest path to production. They're strong when your use case involves broad language ability, flexible reasoning, or open-ended writing across many contexts.
They work well for:
- General drafting work: Marketing briefs, sales emails, internal communication.
- Early pilot programs: Teams testing where AI fits before committing to deeper architecture.
- Broad unstructured tasks: Summaries, brainstorming, rewrite assistance, meeting notes.
Their biggest advantage is speed. You can stand up a pilot quickly and learn where the workflow really breaks. Their weakness is that you may end up paying for capability you don't need, especially if the task is narrow and repetitive.
When custom tuning earns its place
A custom solution makes sense when your workflow depends on proprietary language, domain-specific outputs, or repeatable structure that generic prompting handles inconsistently.
This is common in legal review, insurance claims, compliance workflows, medical documentation support, and technical operations. The point isn't to customize for prestige. It's to reduce variability where precision matters.
A tuned system may help with:
- Specialized vocabulary: Industry terms, internal codes, approved phrasing.
- Structured output: Extraction, classification, tagging, routing.
- Repeatable process logic: The same task performed thousands of times under clear rules.
That said, many teams jump too early into model training. Often, the issue isn't the base model. It's poor retrieval, weak prompt structure, or unclear workflow design.
Why smaller models deserve more attention
This is one of the most under-discussed decisions in enterprise AI. Not every task needs a frontier model.
Red Hat and Cutter argue that many enterprise tasks are better served by small language models, or SLMs, and by techniques like RAG because they're easier to tune, require less compute, and offer more control over private data. Their view is especially relevant for well-scoped tasks such as customer support and operational efficiency, as outlined in Red Hat's analysis of small language models in enterprise AI.
That's a serious strategic point. If your job is fraud triage, internal policy classification, support intent detection, or routing operational requests, a smaller model may be the better economic answer.
Bigger models are often better at broad reasoning. Smaller models are often better business tools when the task is narrow, high-volume, and well-defined.
A useful decision lens looks like this:
| Option | Best for | Trade-off |
|---|---|---|
| Vendor API model | Fast deployment, broad capability | Less control, potentially higher run cost |
| Fine-tuned model | Specialized domain output | More setup and governance complexity |
| SLM | Narrow, high-volume workflows | Less general flexibility |
| Model plus RAG | Internal knowledge tasks | Depends heavily on retrieval quality |
If your team is planning to go beyond off-the-shelf copilots, this overview of how to build a custom AI agent is useful because it forces the right architecture questions before you commit to one model family.
The practical buying rule
Use the most capable model only when the task requires that capability. For everything else, optimize for fit.
A CEO doesn't need one AI model strategy. The company usually needs several. One model for broad drafting. Another setup for internal search. Possibly a smaller model for repetitive operational tasks. The winning architecture is usually mixed.
Integrating AI Securely with Your Business Data
An AI model without access to your business context is mostly a polished generalist. It can sound smart while missing the exact policy, customer detail, or operational fact your team needs.
That's why secure integration matters more than model hype. In enterprise settings, the question isn't solely whether the model can answer. It's whether it can answer from the right source, under the right permissions, with traceable grounding.
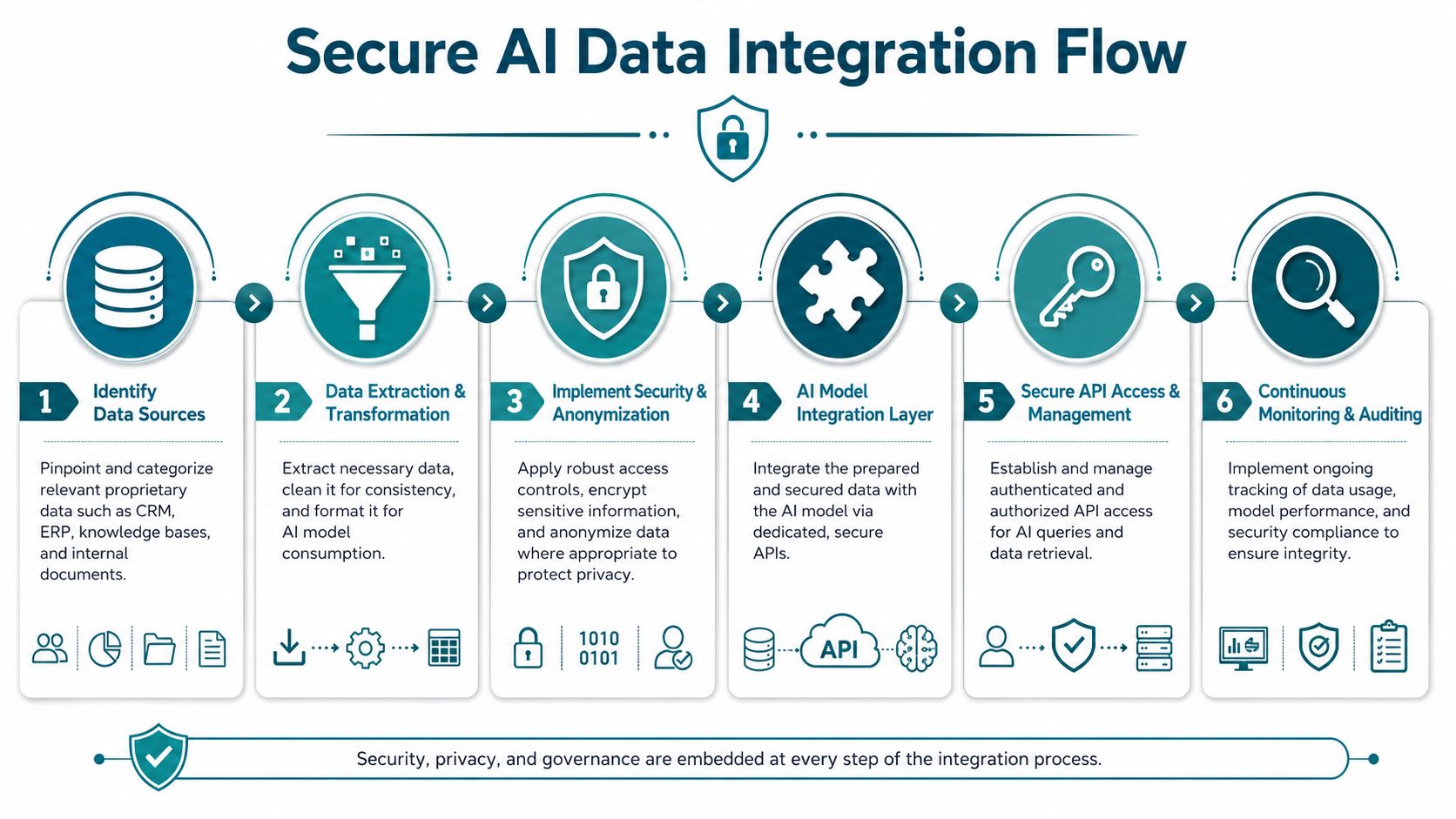
Why RAG matters in practice
The cleanest mental model is an open-book exam. A standalone model relies on what it already knows. A model using Retrieval-Augmented Generation, or RAG, looks up the relevant material before answering.
That's a major shift in how enterprise systems should be built. Instead of trying to cram every company fact into the model itself, you keep the model general-purpose and let retrieval pull in current, internal information from places like SharePoint, a CRM, or a knowledge base.
The Blue AI notes that RAG adapts AI models to internal data without retraining, increasing accuracy and reliability, and that connecting an LLM to sources like SharePoint or CRM systems helps reduce hallucinations in workflows such as policy Q&A and support triage in its enterprise guide to productivity with LLMs and AI agents.
What secure integration really requires
Many teams underestimate the implementation work because the demos look simple. In reality, secure enterprise AI depends on disciplined plumbing.
At minimum, you need:
- Identity-aware access: The model should only retrieve what the user is allowed to see.
- Content preparation: Badly organized documents produce bad retrieval.
- Source ranking: The system has to pull the most relevant records, not just any records.
- Response grounding: Answers should point back to underlying source material where possible.
- Monitoring: Teams need logs, evaluation, and exception tracking.
Security isn't only about keeping data inside a boundary. It's also about preventing confident wrong answers that trigger customer issues, policy mistakes, or compliance exposure.
For teams mapping this out, a practical companion is this checklist of AI security best practices, especially around access controls, governance, and deployment discipline.
A secure AI system is not just one that protects data. It's one that answers from approved data and refuses to improvise beyond it.
Where integration creates the most value
RAG tends to outperform generic prompting in workflows where accuracy and recency matter more than creative flair.
That includes:
- Policy and procedure Q&A
- Support triage and resolution guidance
- Sales knowledge retrieval
- Document review and extraction
- Internal search across scattered knowledge bases
This is also where trust is won or lost. If the system gives staff the right answer from the approved source, adoption grows. If it invents policy language once in a high-stakes process, confidence drops fast.
Leaders should treat retrieval quality as a first-class design decision, not a backend detail.
Measuring What Matters KPIs and True ROI
Most AI business cases collapse because the measurement plan is weak. Teams launch a co-pilot, collect positive anecdotes, and report that employees “saved time.” Finance hears soft benefits. Operations hears unverified claims. Compliance hears risk without proof of control.
That's not enough.

Why time savings is a weak primary metric
The broad market often talks about 5% to 40% time savings, but that's too blunt to run an investment committee on. Glean argues that measuring AI productivity requires moving beyond those broad claims to workflow-specific metrics such as throughput, accuracy, and rework rates, and that the core challenge is proving value in ways finance, ops, and compliance will all accept, as described in Glean's perspective on enterprise productivity measurement.
Time saved is real, but it's incomplete. If a team saves time and produces more errors, the business hasn't gained productivity. It has shifted work downstream.
Use function-specific KPI sets
The right metric depends on the function and the workflow. Support, sales, legal, and operations should not share one generic AI scorecard.
A stronger approach looks like this:
| Function | Better KPI focus | Why it matters |
|---|---|---|
| Customer support | Throughput, resolution quality, rework | Faster replies mean little if cases reopen |
| Sales | Research cycle speed, qualification quality, follow-up consistency | AI should improve seller focus, not just note-taking |
| Legal and compliance | Review turnaround, exception rate, policy adherence | Output quality matters more than raw speed |
| Internal operations | Queue velocity, error reduction, handoff quality | Workflow friction shows up in delays and repeat handling |
Build the baseline before rollout
Here, mature teams separate themselves. They capture pre-AI performance first.
That usually means identifying:
- Current cycle time: How long the process takes now
- Current error or rework rate: Where corrections happen
- Current labor intensity: Which roles touch the task
- Current exception path: What still requires escalation
Once AI is introduced, compare the same workflow under the same conditions. Don't compare a polished pilot to an unstructured baseline. And don't let adoption confusion distort the measurement window.
If AI changes the workflow, your ROI model has to measure the workflow, not the model.
What finance will trust
Finance rarely objects to AI itself. It objects to fuzzy attribution.
A metric framework becomes credible when it can answer four questions clearly:
- What business process changed
- What cost or output driver moved
- How you isolated AI's contribution
- What risk controls stayed in place
The strongest AI productivity stories sound less like innovation theater and more like operational improvement. “We reduced rework in support triage.” “We increased reviewed-document throughput without lowering quality.” “We improved policy answer accuracy and reduced manual escalations.”
That's how AI gets funded beyond the pilot.
Your Phased AI Adoption Roadmap
The fastest way to waste AI budget is to start with an ambitious agentic program before your company has usable data, clear ownership, or baseline metrics. Strong adoption usually looks boring at first. It starts small, proves a result, then expands where the business already feels pain.
That's not hesitation. That's how you scale without creating a mess.
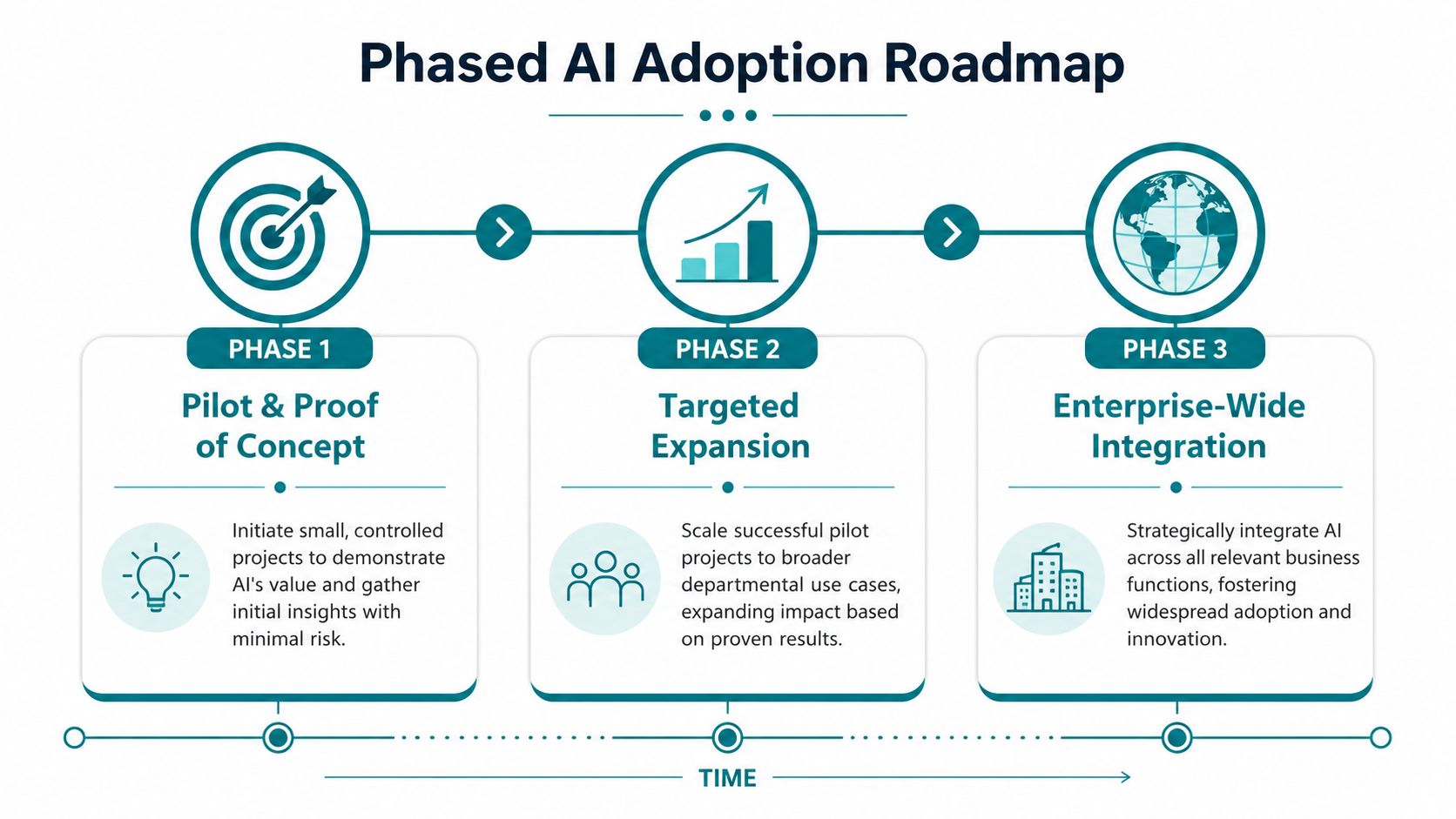
Phase one builds the foundation
The first phase is about readiness and one practical win. Not ten.
Pick a workflow with clear friction, low political resistance, and accessible data. Internal policy Q&A, support knowledge retrieval, and sales enablement are common starting points because they expose search problems quickly and produce visible improvements without overhauling core systems.
Focus areas in this phase:
- AI readiness audit: Understand data quality, access issues, governance gaps, and tool sprawl.
- Use case selection: Choose one process where employees already complain about delay or repetition.
- Baseline metrics: Lock in current throughput, quality, and rework before launch.
- Human review rules: Define where people must approve, edit, or override.
The output of phase one isn't “we have AI.” It's “we improved one process and know why.”
Phase two embeds AI into a team workflow
Once the first use case works, the next step is deeper integration into one business function. At this point, AI begins its transition from an assistant to an operational layer.
That often means a RAG-enabled system for support, sales, legal operations, or technical teams. The model now works from approved company sources and helps staff inside their actual workflow, not just in a separate chat window.
At this stage, leaders should tighten:
- System integration: CRM, ticketing, document repositories, or internal portals
- Evaluation discipline: Response quality, retrieval relevance, and exception handling
- Adoption management: Training, prompt guidance, and workflow redesign
- Governance: Access, logging, escalation policy, and content ownership
This is also where internal resistance becomes visible. Some teams will worry about trust. Others will try to use the tool outside its lane. Good leadership keeps the system narrow enough to succeed before broadening it.
Phase three scales automation carefully
Only after workflows are stable should you push into agentic automation and custom model strategy.
This phase is where companies explore multi-step execution. The system doesn't just answer questions. It retrieves context, makes bounded decisions, triggers tools, updates records, and routes exceptions to people when confidence or rules require it.
The right candidates are processes that are repetitive, structured, and high-volume. Think support issue resolution, document processing pipelines, internal operations routing, or tightly scoped compliance review.
A simple roadmap summary:
| Phase | Main goal | Best outcome |
|---|---|---|
| Pilot and proof | Validate one use case | Credible first win |
| Targeted expansion | Improve a team workflow | Repeatable productivity gain |
| Enterprise integration | Automate bounded processes | Scaled operational leverage |
If your leadership team needs a more structured planning template, this AI adoption roadmap is a practical starting point because it pushes the conversation from ideas to sequencing.
Start with a painful workflow, not an exciting technology. Expansion gets easier when the first deployment solves a problem people already care about.
What success looks like across phases
A mature roadmap doesn't force one model, one interface, or one vendor everywhere. It creates a controlled path from experimentation to operating value.
By the end of the roadmap, you should have:
- A clear model selection logic
- Trusted internal data integration
- Workflow-specific metrics
- Governance that can survive scrutiny
- A short list of processes ready for deeper automation
That's what turns AI into an operating capability instead of a side project.
The Next Step Becoming an AI-First Organization
An AI-first organization isn't a company that bought licenses for a chatbot. It's a company that redesigns work so people and models each do what they're best at.
That requires judgment. Some workflows need a frontier model. Some need a smaller model. Many need retrieval more than they need a smarter base model. And almost all of them need tighter measurement than the market usually talks about.
The leaders who get this right tend to follow the same pattern. They start with a business process, not a tool. They choose the right-sized system for the job. They connect it to trusted data. They measure throughput, accuracy, and rework, not just time saved. Then they expand only after the first gain is real.
If you're leading your first major AI initiative, the next practical moves are straightforward:
- Run an AI readiness audit: Review data maturity, access controls, and process candidates.
- Pick one workflow with visible friction: Support, internal knowledge, document review, or sales enablement.
- Define KPIs before launch: Make finance, ops, and compliance part of the design.
- Choose the model architecture by task: Don't default to the biggest model.
- Plan for phased expansion: Use one win to fund the next layer of automation.
That's how AI language models for enterprise productivity become more than a promising tool. They become part of how the company operates.
If you want help turning AI ambition into a measured operating plan, AmasaTech works with organizations to assess AI readiness, identify high-value use cases, and build phased programs tied to outcomes like accuracy, throughput, cost reduction, and revenue impact. Their approach is practical: start with an AI audit, prove value in a focused workflow, then scale into RAG systems, AI agents, and custom model strategies where the business case is real.